Компания Xiaomi неожиданно выпустила новую модель: сравнимую с DeepSeek-V3.2, она обеспечивает соотношение цены и производительности, сопоставимое с мобильными телефонами, благодаря использованию искусственного интеллекта.

В сегменте устройств с открытым исходным кодом появился еще один серьезный конкурент. Компания Xiaomi официально выпустила и открыла исходный код своей новой модели MiMo-V2-Flash.
MiMo-V2-Flash имеет в общей сложности 309 миллиардов параметров, из которых 15 миллиардов являются активными. В ней используется гибридная экспертная архитектура (MoE), и её производительность может конкурировать с ведущими моделями с открытым исходным кодом, такими как DeepSeek-V3.2 и Kimi-K2.

Кроме того, MiMo-V2-Flash использует лицензию с открытым исходным кодом MIT, а основные авторские права на него также были опубликованы на Hugging Face. Помимо открытого исходного кода, настоящая изюминка новой модели заключается в радикальной инновации в архитектурном проектировании, которая увеличила скорость обработки данных до 150 токенов в секунду и снизила стоимость до 0,1 доллара за миллион входных токенов и 0,3 доллара за миллион выходных, что обеспечивает выдающееся соотношение цены и производительности.
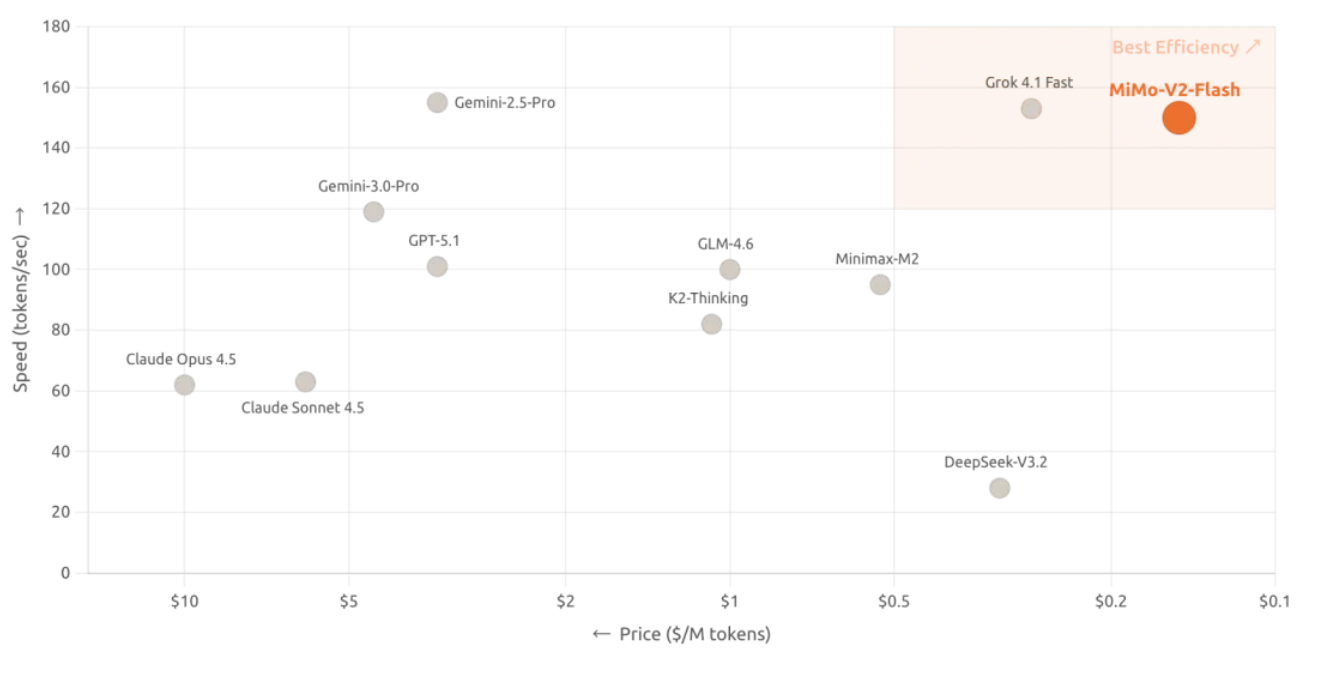
Согласно официальной странице, MiMo-V2-Flash поддерживает функции глубокого мышления и онлайн-поиска, что означает, что он может не только писать код и решать математические задачи, но и получать самую свежую информацию в режиме реального времени.
Вот ссылка, чтобы ознакомиться с AI Studio:
http://aistudio.xiaomimimo.com
SWE-Bench устанавливает новый стандарт для моделей с открытым исходным кодом, занимая лидирующие позиции в рейтингах.
Как обычно, давайте сначала взглянем на результаты тестов MiMo-V2-Flash.
В математическом плане MiMo-V2-Flash вошла в число двух лучших моделей с открытым исходным кодом как в математическом конкурсе AIME 2025, так и в тесте GPQA-Diamond Science Knowledge Test.
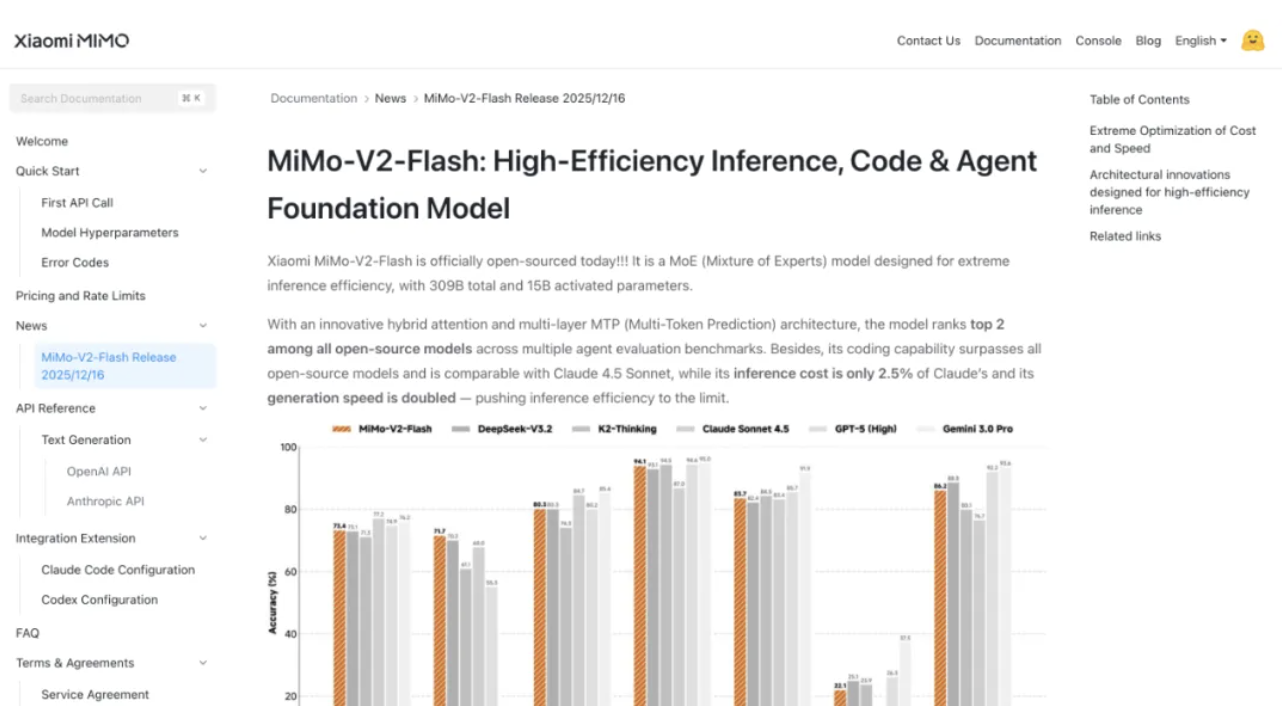
Его программные возможности еще более впечатляют: он набрал 73,4% в тесте SWE-bench Verified, превзойдя все модели с открытым исходным кодом и приблизившись к показателю GPT-5-High. Проще говоря, этот тест проверяет ИИ на наличие реальных программных ошибок, и 73,4% успеха означает, что он может справиться с большинством практических задач программирования.
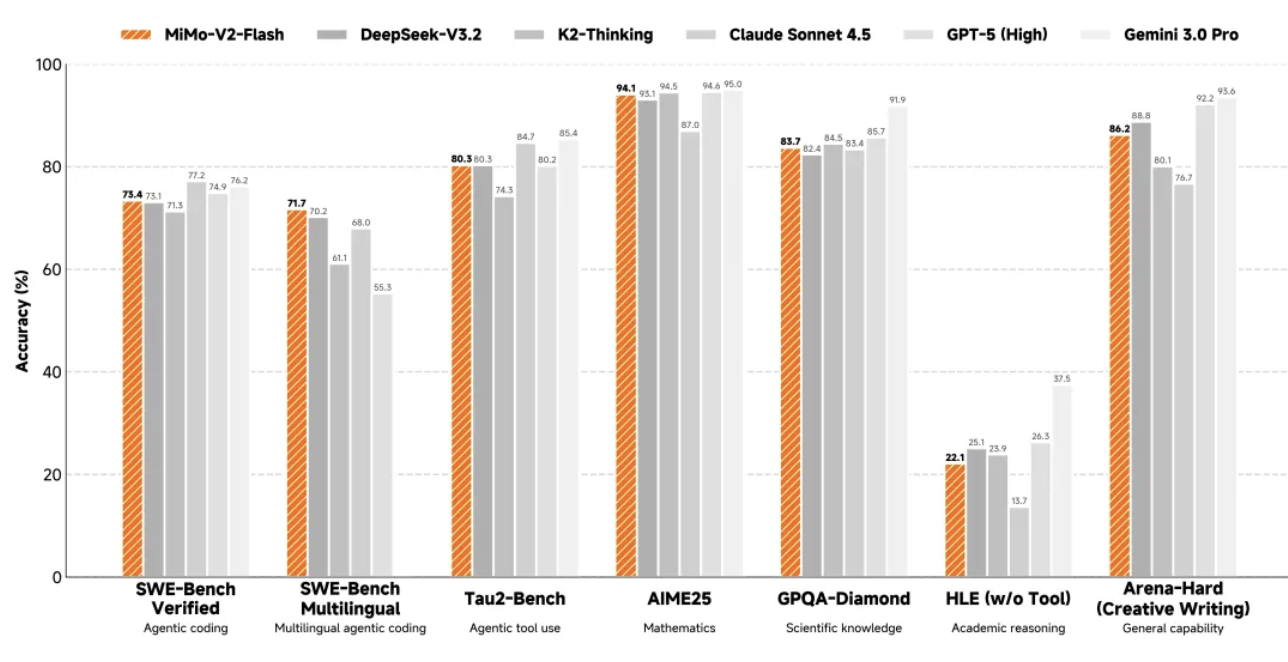
В многоязычном бенчмарк-тесте SWE-Bench показатель разрешения составил 71,7%. В задаче интеллектуального агента MiMo-V2-Flash набрал 95,3 балла в категории «коммуникации», 79,5 балла в категории «розничная торговля» и 66,0 балла в категории «авиация» в классификационном тесте τ²-Bench.
Рейтинг поискового агента BrowseComp составлял 45,4, но после включения управления контекстом он подскочил до 58,3.
Эти данные демонстрируют, что MiMo-V2-Flash способен не только писать код, но и по-настоящему понимать сложную логику задач и выполнять многоходовые взаимодействия агентов. Его возможности обработки длинного текста также впечатляют; в реальных условиях тестирования его производительность даже превосходит производительность более крупного Kimi-K2 Thinking, что доказывает мощные возможности моделирования на больших расстояниях, предоставляемые гибридной архитектурой внимания со скользящим окном.
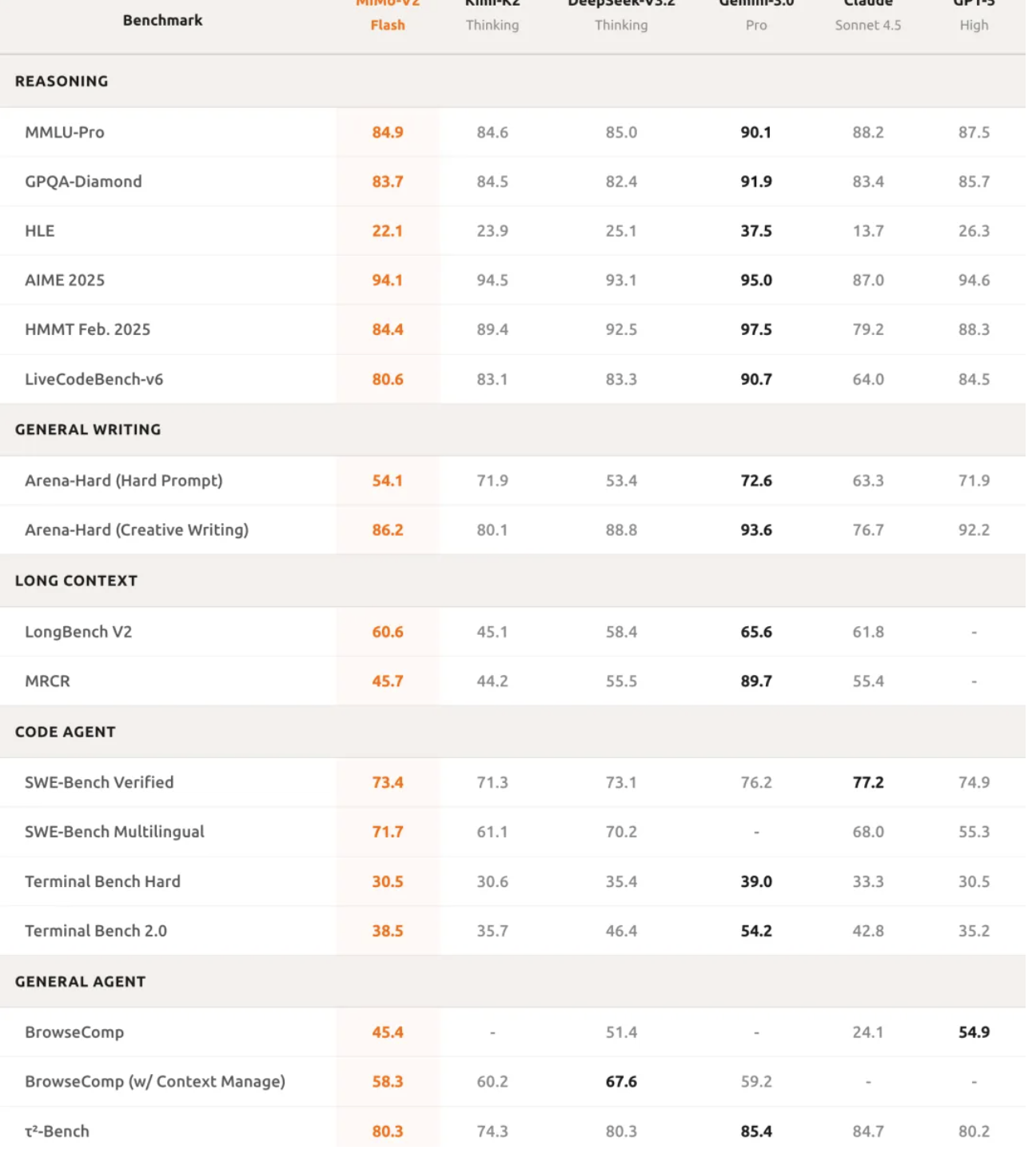
Качество записи также близко к качеству лучших моделей с закрытым исходным кодом, а это значит, что MiMo-V2-Flash — это не просто инструмент, а надежный помощник на каждый день.
Секрет сохранения производительности и шестикратного снижения затрат при выводе длинных текстовых файлов.
Ключевым нововведением MiMo-V2-Flash является гибридный механизм внимания с использованием скользящего окна.
Когда традиционные крупномасштабные модели обрабатывают длинные тексты, механизм глобального внимания вызывает вторичный взрыв вычислительной нагрузки, а также резко возрастает объем кэша типа «ключ-значение» для хранения промежуточных результатов. В этот раз Xiaomi применила агрессивное соотношение 5:1, чередуя 5 слоев скользящего окна внимания и 1 слой глобального внимания, при этом скользящее окно учитывает только 128 токенов.
(Для тех, кто не знаком с ИИ, вот краткое объяснение: в крупномасштабном моделировании/обработке естественного языка «токен» — это наименьшая единица счета, используемая моделью при чтении и выводе текста. Модель не считает фиксированным образом, например, «один китайский иероглиф = 1, одно английское слово = 1», а обрабатывает текст, разделяя его на сегменты токенов.)
Проще говоря, модели не нужно каждый раз просматривать весь контент; она анализирует только 128 последних токенов и периодически проверяет глобальный список. Это значительно снижает вычислительные и дисковые затраты. Такая конструкция уменьшает объем кэша ключ-значение почти в 6 раз, но не снижает возможности работы с длинным текстом, поддерживая максимальное контекстное окно в 256 КБ.
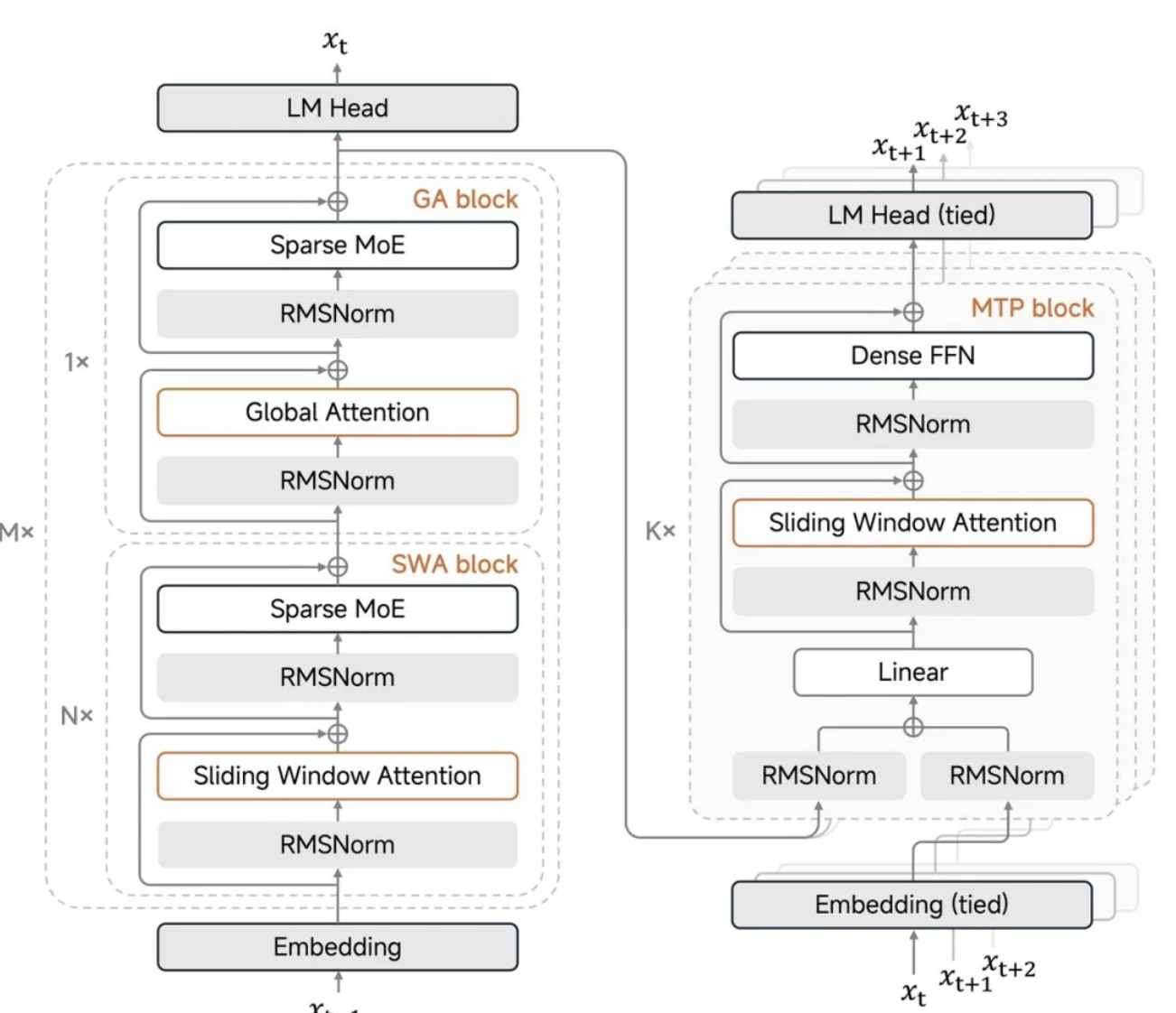
Ключевой момент заключается в том, что Xiaomi также разработала "обучаемый механизм смещения потока внимания", который позволяет модели поддерживать стабильную производительность при работе с длинными текстами даже при таких агрессивных настройках окна.
Ло Фули подчеркнул в социальных сетях, что размер окна в 128, как было доказано, является «оптимальным значением», в то время как 512 фактически приводит к снижению производительности. Этот вывод довольно противоречив; можно подумать, что чем больше окно, тем лучше, но в реальных тестах оптимальным оказалось значение 128. Кроме того, значения параметров стока (обратите внимание на параметры стока) имеют важное значение и никогда не должны игнорироваться.
Еще одна передовая технология — это облегченное многотокенное прогнозирование (MTP).
Традиционные модели при генерации текста могут выдавать только один токен за раз, подобно машинистке, набирающей по одному слову. MiMo-V2-Flash, благодаря встроенному модулю MTP, может предсказывать несколько токенов параллельно, угадывая сразу несколько токенов.
В ходе реальных тестов он может обрабатывать в среднем от 2,8 до 3,6 токенов, что напрямую увеличивает скорость вывода в 2–2,6 раза. Это полезно не только во время вывода, но и ускоряет выборку и сокращает время простоя графического процессора на этапе обучения, что является двойной выгодой.
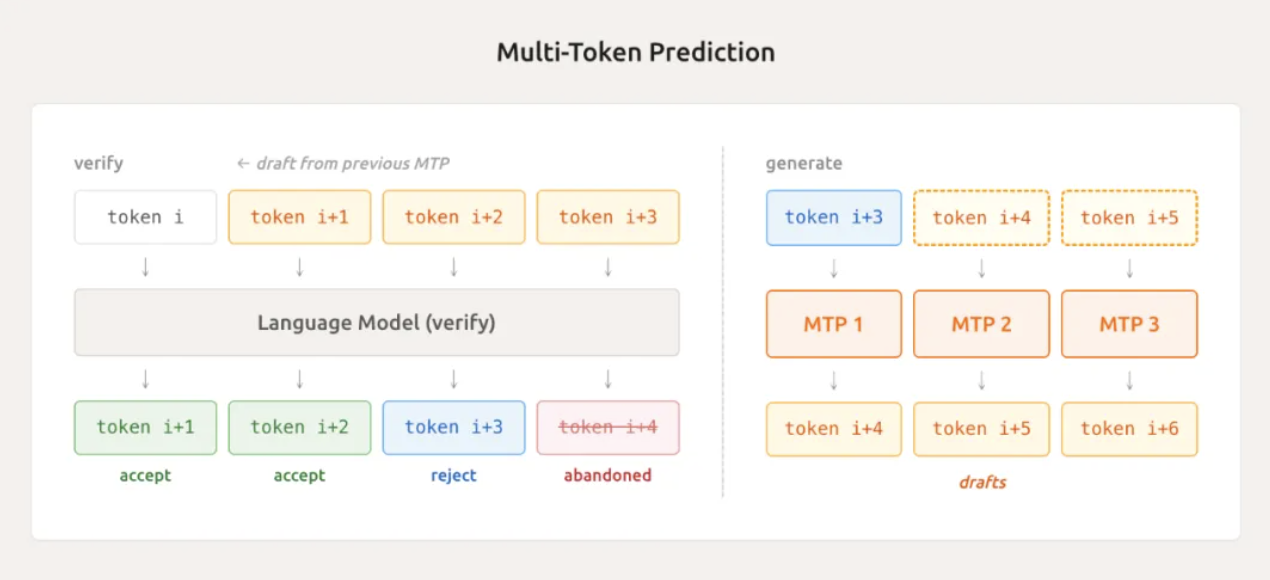
Ло Фули упомянул, что при использовании трехслойной конфигурации MTP они наблюдали среднюю длину принятия, превышающую 3, что привело к ускорению задачи кодирования примерно в 2,5 раза. Это эффективно решает проблему потери времени простоя графического процессора, вызванную «выборками с длинным хвостом» в мини-пакетном обучении с подкреплением на основе политики.
Что такое «длиннохвостые» выборки? Это те особенно сложные и медленные задачи, которые замедляют выполнение других задач, из-за чего графический процессор оказывается в тупике. Технология MTP решает эту проблему, значительно повышая эффективность.
Однако Ло Фули также признал, что из-за нехватки времени им не удалось полностью интегрировать MTP в цикл обучения с подкреплением в этот раз, но он отлично совместим с процессом. Xiaomi уже открыла исходный код трехслойного MTP, что делает его удобным для использования и разработки в собственных проектах.
Как можно не снижать производительность, если используется всего 1/50 вычислительной мощности?
На этапе предварительного обучения новая модель использует смешанную точность FP8 и обучается на 27 триллионах токенов данных, изначально поддерживая последовательности длиной до 32 тысяч символов.
FP8 смешанная точность — это метод сжатия числовых представлений, который позволяет уменьшить использование памяти и ускорить обучение, сохраняя при этом точность. Этот метод обучения не распространен в отрасли и требует глубокой оптимизации базовой структуры.
На более позднем этапе обучения компания Xiaomi добилась значительного нововведения, предложив метод онлайн-стратегии с участием нескольких преподавателей (Multi-Teacher Online Strategy Distillation, MOPD).
Традиционные конвейеры обучения с подкреплением и тонкой настройкой под наблюдением не только нестабильны в процессе обучения, но и чрезвычайно ресурсоемки с точки зрения вычислительных затрат. Подход MOPD предполагает, что модель-ученик выбирает значения из собственного распределения стратегий, а затем несколько экспертов-учителей подают плотные сигналы вознаграждения в каждом месте расположения токена.
Проще говоря, ученик выполняет домашнее задание самостоятельно, а учитель оценивает каждое слово отдельно, не дожидаясь, пока будет написан весь текст. Это позволяет ученику быстро усвоить основы от учителя, и процесс обучения становится гораздо более стабильным.
Наиболее заметное улучшение заключается в эффективности. MOPD требует всего 1/50 вычислительной мощности традиционных методов, чтобы позволить моделям-ученикам достичь максимальной производительности моделей-учителей. Это означает, что Xiaomi может быстрее создавать модели с меньшими ресурсами.
Кроме того, MOPD поддерживает гибкую интеграцию новых учителей, а ученики-модели могут сами стать учителями после того, как вырастут, формируя замкнутый цикл саморазвития «обучения и воспитания». Сегодняшние ученики могут стать завтрашними учителями, а послезавтра они могут воспитать еще более сильных учеников. Этот подход, напоминающий вложенную куклу, поистине гениален.
По словам Ло Фули, они позаимствовали метод On-Policy Distillation из Thinking Machines для объединения нескольких моделей обучения с подкреплением, что привело к значительному повышению эффективности. Это заложило основу для создания самоподкрепляющейся системы, в которой модели-ученики могут постепенно эволюционировать в более сильные модели-учителя.
Что касается расширений для обучения агентов с подкреплением, исследовательская группа Xiaomi MiMo-V2-Flash разработала более 100 000 проверяемых задач на основе реальных проблем GitHub. Автоматизированный конвейер работает на кластере Kubernetes, способном одновременно запускать более 10 000 Pod-ов, с 70% вероятностью успешного развертывания среды.
Для задач веб-разработки также был разработан многомодальный валидатор. Он проверяет результаты выполнения кода, записывая видео вместо статических скриншотов, что напрямую уменьшает визуальные иллюзии и гарантирует корректность работы функций.
Для разработчиков MiMo-V2-Flash может легко интегрироваться с распространенными средами разработки, такими как Claude Code, Cursor и Cline, а его сверхдлинное контекстное окно размером 256 КБ поддерживает сотни раундов взаимодействия с агентами и вызовов инструментов.
Что означает 256 КБ? Это примерно эквивалентно роману средней длины или нескольким десяткам страниц технической документации. Это значит, что разработчики могут напрямую интегрировать MiMo-V2-Flash в свои существующие рабочие процессы без каких-либо дополнительных изменений; они могут использовать его сразу же после установки.
Компания Xiaomi также предоставила весь свой код для выполнения инференции в SGLang и поделилась своим опытом оптимизации инференции в блоге LMSYS.
В техническом отчете раскрываются полные детали модели, а весовые коэффициенты модели (включая MiMo-V2-Flash-Base) опубликованы на Hugging Face под лицензией MIT. Такой всеобъемлющий подход с открытым исходным кодом действительно является редкостью среди крупных китайских компаний.
В настоящее время MiMo-V2-Flash доступен бесплатно на платформе API в течение ограниченного времени, что позволяет разработчикам немедленно приступить к работе.
Амбиции Xiaomi в области искусственного интеллекта выходят за рамки простого мобильного помощника.
Выпуск MiMo-V2-Flash знаменует собой полномасштабные усилия Xiaomi в области искусственного интеллекта.
Ло Фули поделился дополнительной информацией в социальных сетях: «MiMo-V2-Flash официально запущен. Это всего лишь второй шаг в нашей дорожной карте AGI». Второй шаг уже настолько впечатляет, так какие еще большие сюрпризы нас ждут? Это то, чего стоит ждать с нетерпением.
Конечно, Xiaomi также откровенно признала в своем техническом отчете, что MiMo-V2-Flash все еще отстает от самых мощных моделей с закрытым исходным кодом. Однако их план ясен: сократить разрыв за счет увеличения размера модели и вычислительной мощности для обучения, одновременно продолжая исследовать более надежные и эффективные архитектуры агентов.
Итеративная совместная эволюция моделей преподавания и обучения в рамках концепции MOPD также оставляет ample возможности для дальнейшего совершенствования потенциала.
Если посмотреть на это в более широком смысле, это представляет собой стратегическую ставку Xiaomi на всю экосистему искусственного интеллекта. От смартфонов и IoT до автомобилей, аппаратная экосистема Xiaomi нуждается в надежной основе для ИИ, и MiMo-V2-Flash, очевидно, является краеугольным камнем, который Xiaomi готовит для всей своей аппаратной экосистемы.
Подобно тому, как десять лет назад Xiaomi переосмыслила ценовой стандарт для флагманских телефонов со своим телефоном за 1999 юаней, MiMo-V2-Flash теперь переопределяет стандарт производительности для больших моделей с открытым исходным кодом, предлагая стоимость 0,1 доллара за миллион токенов и результат в SWE-Bench 73,4%.
На этот раз «момент Xiaomi», характерный для модели открытого исходного кода, действительно настал.
Адрес модели HuggingFace:
http://hf.co/XiaomiMiMo/MiMo-V2-Flash
Адрес для публикации технического отчета:
http://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (идентификатор WeChat: ifanr), где вы сможете в кратчайшие сроки увидеть еще больше интересного контента.
ifanr | Оригинальная ссылка · Посмотреть комментарии · Sina Weibo