Прошел год с момента выхода DeepSeek R1. Как же компании удается сохранять свой «аппаратный контроль» над Кремниевой долиной, не уделяя должного внимания функционалу, привлечению финансирования и спешке?

«Сервер занят, пожалуйста, попробуйте позже».
Год назад я тоже был одним из тех пользователей, которых это утверждение полностью очаровало.

Год назад, в этот же день (20 января 2025 года), DeepSeek дебютировал с R1, привлекая внимание всего мира с момента своего появления.
Тогда, чтобы бесперебойно использовать DeepSeek, я прошёл все обучающие материалы по самостоятельному развертыванию и скачал множество приложений, которые выдавали себя за "XX – DeepSeek Full Version".

Честно говоря, год спустя я стал открывать DeepSeek гораздо реже.
Doubao может осуществлять поиск и генерацию изображений, Qianwen интегрирован с Taobao и Gaode Maps, а Yuanbao обладает контентной экосистемой, включающей голосовой диалог в реальном времени и официальные аккаунты WeChat; не говоря уже о передовых зарубежных продуктах, таких как ChatGPT и Gemini.
По мере того, как эти всемогущие ИИ-помощники расширяют свой функционал, я всерьез задаюсь вопросом: «Зачем оставаться с DeepSeek, когда есть более удобные варианты?»
Таким образом, DeepSeek переместился с первого экрана на второй экран моего телефона и из приложения, которое нужно было открывать каждый день, превратилось в то, о чем я вспоминаю лишь изредка.
Судя по рейтингу в App Store, это "изменение мнения" не кажется мне плодом моего воображения.
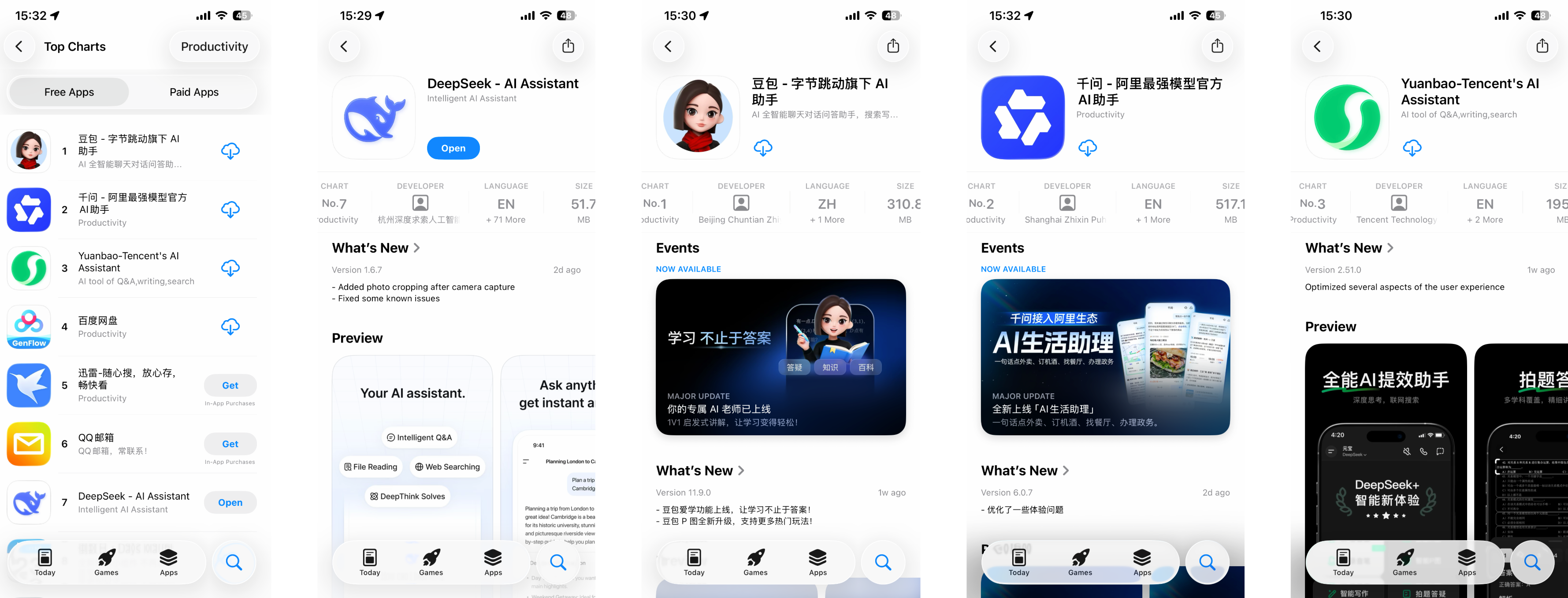
▲ Три верхние строчки в рейтинге бесплатных приложений теперь занимают «Большая тройка» крупнейших китайских интернет-компаний, в то время как DeepSeek, когда-то занимавший первое место, незаметно опустился на седьмую позицию.
Среди конкурентов, которые буквально кричат о своей «всемогущести», «мультимодальном подходе» и «поиске с использованием ИИ», DeepSeek выделяется. Благодаря минималистичному установочному пакету размером всего 51,7 МБ, он не гонится за трендами, не занимается маркетингом и даже ещё не внедрил функции визуального анализа или мультимодального поиска.
Но это самая интересная часть. На первый взгляд кажется, что платформа действительно "отстала", но на самом деле вызовы моделей, связанные с DeepSeek, по-прежнему остаются предпочтительным выбором для большинства платформ.
Когда я попытался подвести итоги деятельности DeepSeek за последний год, переключив внимание с этого единственного графика загрузок на глобальное развитие ИИ, чтобы понять, почему оно такое неторопливое и какие новые потрясения принесет грядущая версия V4, я обнаружил, что это «седьмое место» для DeepSeek ничего не значит. Это всегда был «призрак», не дающий гигантам спать по ночам.
Отстаёте? У DeepSeek свой ритм.
В то время как мировые гиганты в сфере ИИ движимы капиталом и стремятся к прибыли за счет коммерциализации, DeepSeek действует как независимый участник рынка. Посмотрите на его конкурентов: отечественные компании, такие как Zhipu и MiniMax, которые недавно вышли на Гонконгскую фондовую биржу, и международные компании, такие как OpenAI и Anthropic, которые получают масштабные инвестиции.
Чтобы поддерживать дорогостоящую гонку за вычислительную мощность, даже Маск не смог устоять перед искушением привлечения капитала, всего несколько дней назад собрав 20 миллиардов долларов для xAI.
Однако до сегодняшнего дня DeepSeek не получает никакого внешнего финансирования.
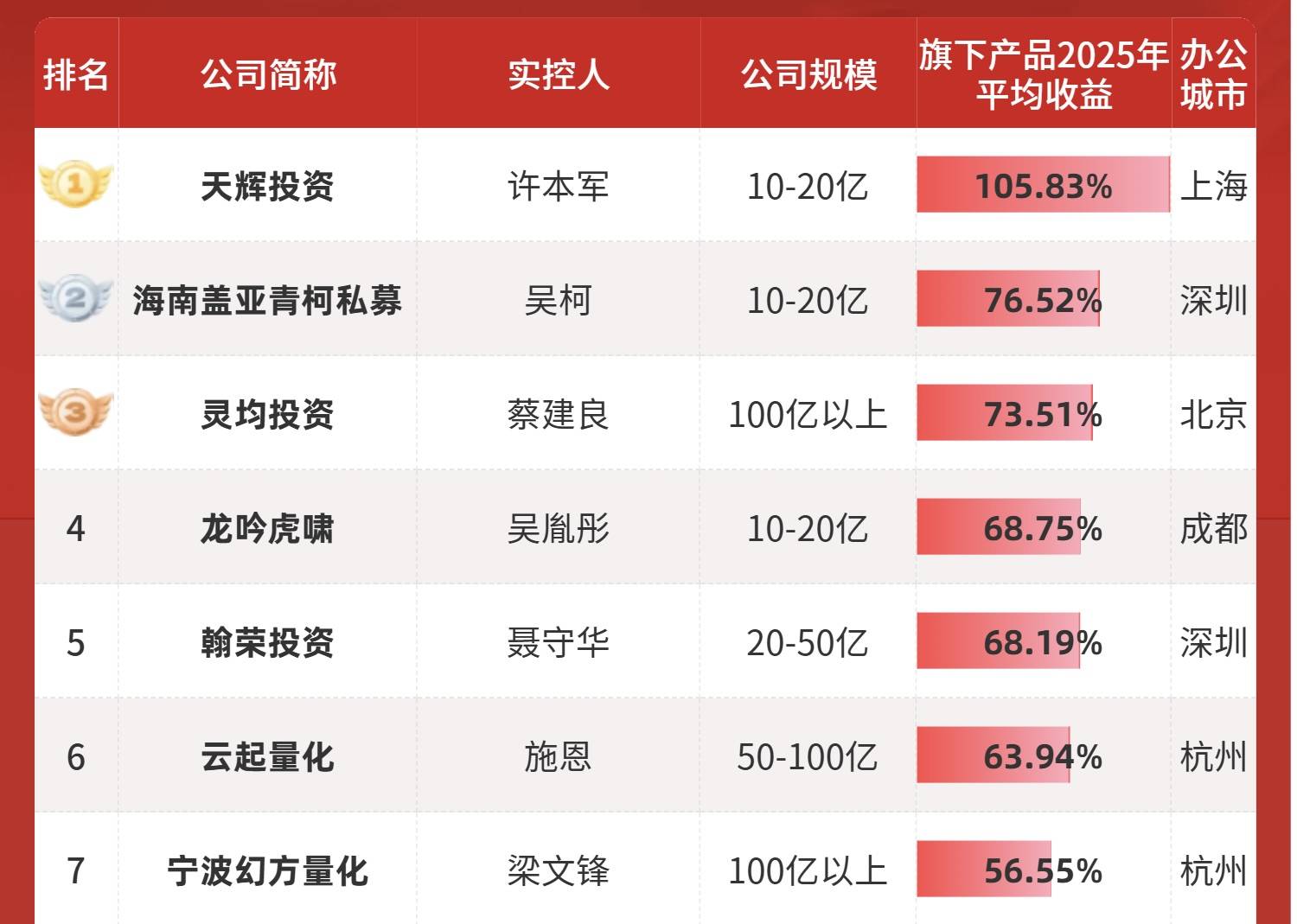
▲В ежегодном рейтинге 100 крупнейших частных инвестиционных компаний, ранжированных по средней доходности компаний, фонд Huanfang Quantitative Fund занял седьмое место и второе место по объему активов под управлением, превышающему 10 миллиардов юаней . | Источник изображения: https://www.simuwang.com/news/285109.html
В эпоху, когда все стремятся получить прибыль и продемонстрировать результаты инвесторам, DeepSeek осмеливается отставать, потому что за ней стоит сверхмощная «машина для печатания денег»: Magic Square Quant.
Этот количественный фонд, являющийся материнской компанией DeepSeek, в прошлом году показал исключительно высокую доходность в 53%, получив прибыль, превышающую 700 миллионов долларов (приблизительно 5 миллиардов юаней).
Лян Вэньфэн напрямую использовал эти старые деньги для поддержки новой мечты о создании «ИИ в DeepSeek». Эта модель также предоставила DeepSeek чрезвычайно высокий уровень контроля над своими финансами.

- Вмешательства со стороны инвесторов не было.
- В отличие от типичных проблем крупных корпораций, многие лаборатории, получившие масштабное финансирование, погрязли в тщеславии и внутренних распрях, как, например, Thinking Machine Lab, которую в последнее время часто беспокоят сообщения об увольнениях сотрудников, и Meta AI Lab Цукерберга, замешанная в различных скандалах.
- Сосредоточившись исключительно на технологиях, DeepSeek, свободная от внешнего давления со стороны оценочной стоимости, не нуждается в спешке с запуском универсального приложения для улучшения своей финансовой отчетности, а также не гонится за рыночными трендами, занимаясь мультимодальной разработкой. Компания отвечает только за свои технологии, а не за финансовую отчетность.
Для стартапа, которому необходимо доказать венчурным инвесторам рост числа ежедневных активных пользователей, рейтинг загрузок в App Store является критически важным фактором. Но для лаборатории, которая занимается исключительно разработкой ИИ, имеет достаточное финансирование и не хочет, чтобы ею управляли деньги через KPI, отставание в этих рыночных рейтингах может стать лучшей защитой, позволяющей ей сохранять концентрацию и избегать внешнего шума.

▲ Более того, согласно отчету QuestMobile, влияние DeepSeek нисколько не уменьшилось.
Меняем жизни людей и влияем на глобальную гонку вооружений в области искусственного интеллекта.
Даже если DeepSeek совершенно безразлично, выбрали ли мы другие, более совершенные приложения ИИ, его влияние за последний год ощутили все отрасли.
Революция DeepSeek в Силиконовой долине
На заре своего существования DeepSeek был не просто полезным инструментом, но и законодателем моды, разрушив тщательно созданный гигантами Кремниевой долины миф о высоких барьерах для доступа к данным чрезвычайно эффективным и недорогим способом.
▲ Источник изображения: https://openaiglobalaffairs.substack.com/p/deepseek-at-1
Если год назад конкуренция в области ИИ сводилась к тому, у кого больше графических процессоров и у кого больше параметров модели, то появление DeepSeek полностью переписало правила этой конкуренции. В недавнем обзоре, опубликованном OpenAI и её внутренней командой (The Prompt), им пришлось признать, что…
Выпуск DeepSeek R1 вызвал «встряску» в конкуренции в области искусственного интеллекта в то время и даже был назван «сейсмическим шоком».
Своими действиями компания DeepSeek неизменно демонстрирует, что для создания высококачественных моделей не требуются чрезмерные вычислительные мощности.
Согласно недавнему анализу ICIS Intelligence Services, взлет DeepSeek полностью разрушил представление о том, что вычислительная мощность определяет производительность. Он продемонстрировал миру, что даже при ограниченном количестве чипов и чрезвычайно низкой стоимости все еще возможно обучать модели с производительностью, сопоставимой с лучшими американскими системами.

▲ Гонка за искусственным интеллектом превращается в долгий марафон | Источник изображения: https://www.icis.com/asian-chemical-connections/2026/01/a-year-on-from-deepseek-us-versus-china-in-the-ai-race/
Это напрямую привело к изменению глобальной гонки в области ИИ: от "создания самой умной модели" к "тем, кто сможет сделать модель более эффективной, дешевой и простой в развертывании".
«Альтернативный» рост в отчете Microsoft
В то время как гиганты Кремниевой долины все еще борются за платных подписчиков, DeepSeek начинает утверждаться в тех местах, которые эти гиганты забыли.
В опубликованном на прошлой неделе отчете Microsoft «Глобальное внедрение ИИ в 2025 году» рост компании DeepSeek был назван одним из «самых неожиданных событий» 2025 года. В отчете была представлена интересная статистика:
- Высокая популярность в Африке: Благодаря бесплатной стратегии DeepSeek и открытому исходному коду, удалось устранить дорогостоящие абонентские платы и барьеры, связанные с использованием кредитных карт. Уровень его использования в Африке в 2-4 раза выше, чем в других регионах.
- Завоевание ограниченных рынков: В регионах, куда американским технологическим гигантам сложно выйти или где их услуги ограничены, DeepSeek стал практически единственным вариантом. Данные показывают, что компания занимает 89% рынка внутри страны, 56% в Беларуси и 49% на Кубе.
В своем отчете Microsoft также признала, что успех DeepSeek еще раз подтверждает, что широкое внедрение ИИ зависит не только от мощности модели, но и от того, кто может позволить себе ее использовать.
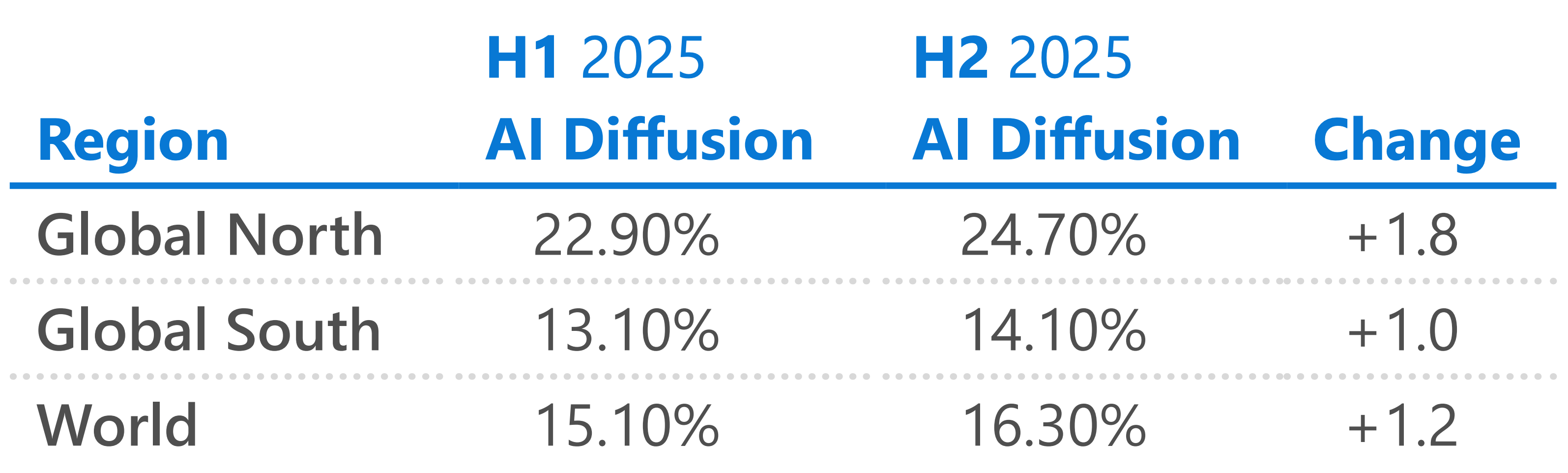
▲В регионе Глобального Юга по-прежнему есть значительные возможности для улучшения внедрения ИИ | https://www.microsoft.com/en-us/corporate-responsibility/topics/ai-economy-institute/reports/global-ai-adoption-2025/
Следующие миллиард пользователей ИИ могут появиться не из традиционных технологических центров, а из регионов, охватываемых DeepSeek.
Европа: Мы также хотим запустить DeepSeek.
Влияние DeepSeek распространяется за пределы Кремниевой долины, охватывая весь мир, включая Европу.
Европа долгое время пассивно использовала американский ИИ, и хотя у неё есть собственная модель, Mistral, она оставалась относительно неизвестной. Успех DeepSeek показал европейцам новый путь: если это может сделать китайская лаборатория с ограниченными ресурсами, почему это не может сделать Европа?

Согласно недавнему сообщению в журнале Wired, в европейском технологическом мире развернулась гонка за «создание европейской версии DeepSeek». Многие европейские разработчики создают масштабные модели с открытым исходным кодом, и один из европейских проектов с открытым исходным кодом, SOOFI, прямо заявляет: «Мы станем европейским DeepSeek».
Влияние DeepSeek за последний год также усугубило опасения Европы по поводу «суверенитета в области ИИ». Они начали понимать, что чрезмерная зависимость от моделей с закрытым исходным кодом из США представляет собой риск, и что эффективная модель DeepSeek с открытым исходным кодом — это именно тот образец, который им нужен.
Что касается версии V4, то здесь есть некоторая информация, заслуживающая внимания.
Влияние продолжается. Если R1 год назад был демонстрацией возможностей ИИ от DeepSeek, станет ли грядущая V4 еще одним нелогичным шагом?
На основе разрозненных утечек информации за последние несколько дней и недавно опубликованных технических документов мы выделили три ключевых сигнала, наиболее важных в отношении V4.
1. Воспроизведение «внезапной атаки в лунный Новый год»
Компания DeepSeek, похоже, питает особую склонность к активным действиям в период празднования Китайского Нового года. Источники указывают, что DeepSeek планирует выпустить свою флагманскую модель следующего поколения, V4, в середине февраля (примерно к Китайскому Новому году). Прошлогодняя модель R1 также была выпущена примерно в это же время, что впоследствии вызвало ажиотаж во всем мире во время весенних праздников.
Следует отметить, что такой график позволяет избежать обычного периода затишья в выпуске новинок в европейских и американских технологических кругах, а также в полной мере использовать желание пользователей попробовать что-то новое во время длительных праздников, что, безусловно, может посеять семена для вирусного распространения.

2. Основные возможности включают объемный код и чрезвычайно длинные контексты.
В современном мире, где повседневные разговоры становятся все более однообразными, V4 выбрала более радикальный прорыв: возможности программирования, повышающие производительность.
По данным источников, близких к DeepSeek, V4 не ограничилась превосходными результатами V3.2 в бенчмарках, но во внутренних тестах ее возможности по генерации и обработке кода напрямую превзошли Claude от Anthropic и серию GPT от OpenAI.

Что еще более важно, V4 пытается решить одну из главных проблем современного ИИ в программировании: обработку «чрезвычайно длинных предложений кода». Это означает, что V4 больше не просто помощник, помогающий нам написать две строчки скрипта; он стремится понимать сложные программные проекты и обрабатывать большие кодовые базы.
Для достижения этой цели в версии V4 также был улучшен процесс обучения, чтобы гарантировать, что модель не «деградирует» по мере обучения при работе с большими объемами данных.
3. Ключевая технология: Энграмма
Более примечательной, чем сама модель V4, является новаторская статья, опубликованная на прошлой неделе компанией DeepSeek в сотрудничестве с командой из Пекинского университета.
В этой статье раскрывается истинный секрет DeepSeek, позволяющий компании добиваться постоянных прорывов, несмотря на ограниченные вычислительные мощности: новая технология под названием «Энграмма».
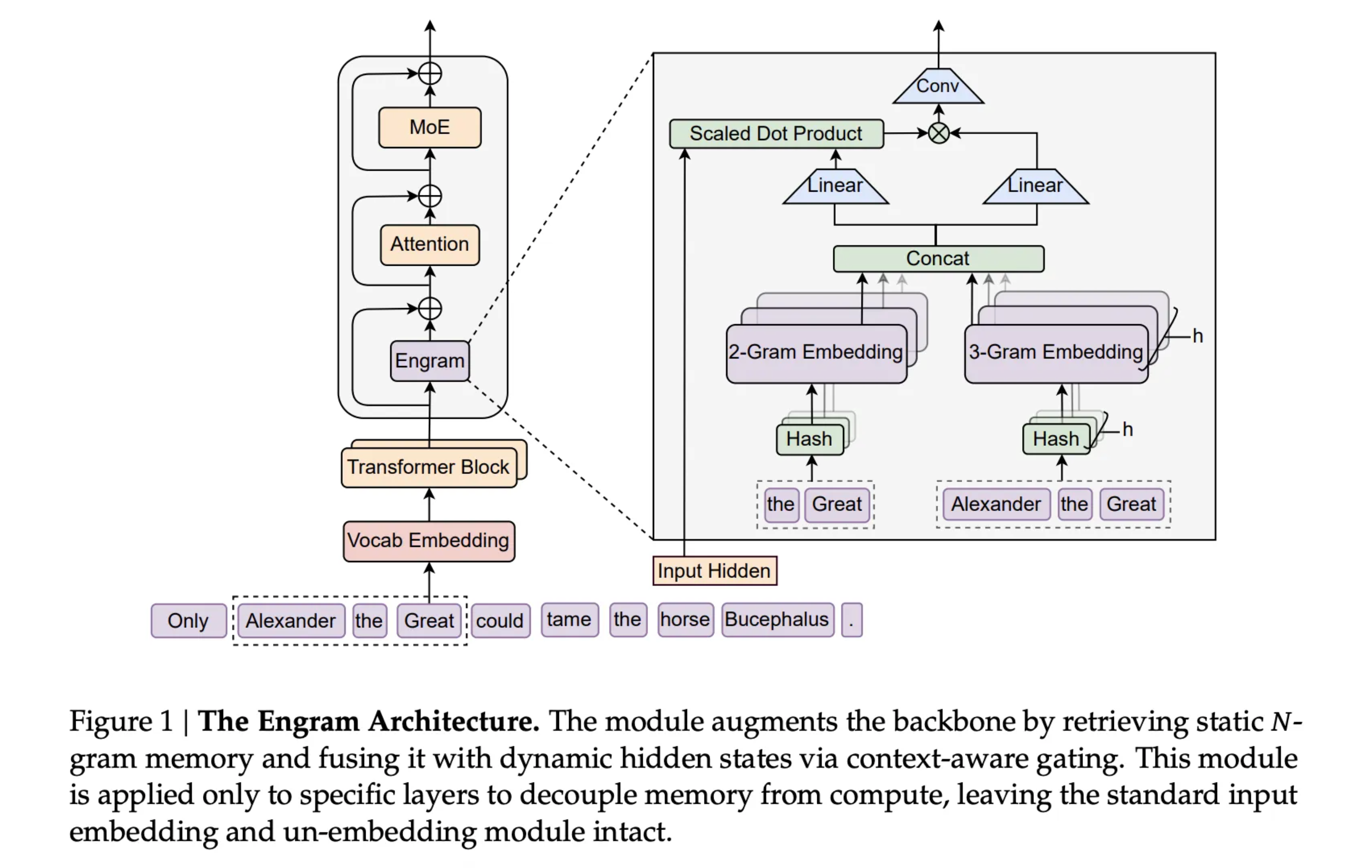
HBM (High Bandwidth Memory) — одна из ключевых областей глобальной конкуренции в сфере вычислительных мощностей для искусственного интеллекта. В то время как конкуренты лихорадочно запасаются графическими картами H100 для увеличения объема памяти, DeepSeek в очередной раз выбрала необычный путь.
- Разделение вычислений и памяти: существующие модели часто требуют больших объемов дорогостоящих вычислительных мощностей для извлечения базовой информации. Технология энграмм позволяет моделям эффективно извлекать эту информацию, не тратя вычислительные мощности на вычисления каждый раз.
- Сэкономленная ценная вычислительная мощность затем используется специально для обработки более сложных логических рассуждений высокого уровня.
- Исследователи утверждают, что этот метод позволяет обойти ограничения памяти, обеспечивая радикальное масштабирование параметров моделей и потенциально еще больше увеличивая количество параметров модели.

На фоне все более дефицитных ресурсов видеокарт, эта статья от DeepSeek, похоже, предполагает, что они никогда не возлагали все свои надежды на простое увеличение количества аппаратных ресурсов.
За последний год эволюция DeepSeek в основном сводилась к решению очевидных проблем в индустрии искусственного интеллекта нетрадиционным способом.
Компания зарабатывает 5 миллиардов долларов в год, чего достаточно для обучения тысяч экземпляров DeepSeek R1, но вместо того, чтобы сосредоточиться на вычислительной мощности и видеокартах, и не имея никаких новостей о выходе на биржу или привлечении финансирования, она начала исследовать, как заменить дорогую память HBM на дешевую память.
За последний год трафик на универсальную модель практически полностью сократился. На фоне того, что все поставщики моделей выпускают крупные обновления каждый месяц и небольшие обновления каждую неделю, компания сосредоточилась на моделях вывода и постоянно улучшала свои предыдущие работы по моделям вывода.
В краткосрочной перспективе все эти решения «неправильны». Без финансирования как они смогут конкурировать с OpenAI по ресурсам? Без разработки мультимодальных, всесторонних приложений, включая обработку необработанных изображений и видео, как они смогут удержать пользователей? Закон масштаба еще не нарушен; без накопления вычислительных мощностей как они смогут создать самую сильную модель?
Однако, если взглянуть на более длительный период, эти «неправильные» решения могут проложить путь для DeepSeek версий V4 и R2.
Это основная философия DeepSeek: пока все остальные борются за ресурсы, компания сосредоточена на эффективности; пока все остальные гонятся за коммерциализацией, она расширяет границы технологий. Продолжит ли V4 идти по этому пути? Или же она пойдёт на компромисс со «здравым смыслом»? Ответ может стать ясен в ближайшие недели.
Но, по крайней мере, теперь мы знаем, что в индустрии искусственного интеллекта нестандартное мышление порой оказывается самым здравым смыслом.
В следующий раз снова будет DeepSeek.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (идентификатор WeChat: ifanr), где вы сможете быстро найти еще больше интересного контента.
ifanr | Оригинальная ссылка · Посмотреть комментарии · Sina Weibo