OpenAI только что выпустил две модели с открытым исходным кодом! Они работают на мобильных телефонах и ноутбуках, и лидерами в этом направлении являются выпускники Пекинского университета.

Спустя пять лет OpenAI официально выпустила две модели с открытым исходным кодом для взвешенных языков — gpt-oss-120b и gpt-oss-20b. В последний раз они публиковали исходный код языковой модели GPT-2 в 2019 году.
OpenAI действительно открыт.
Сегодня сфера искусственного интеллекта также полна пороха. OpenAI открыла исходный код gpt-oss, Anthropic выпустила Claude Opus 4.1 (подробный отчёт ниже), а Google DeepMind выпустила Genie 3. Три гиганта в один и тот же день раскрыли свои козыри, устроив битву богов.
Генеральный директор OpenAI Сэм Альтман выразил свою радость в социальных сетях: «GPT-OSS выпущен! Мы создали открытую модель с производительностью уровня O4-mini, которая может работать на высокопроизводительных ноутбуках. Я очень горжусь командой; это крупная техническая победа».
Основные моменты модели можно резюмировать следующим образом:
- gpt-oss-120b: крупная открытая модель, подходящая для производственных, универсальных и высокопроизводительных сценариев использования, работающая на одном графическом процессоре H100 (117 миллиардов параметров, 5,1 миллиарда активаций), предназначенная для работы в центрах обработки данных, а также на высокопроизводительных настольных компьютерах и ноутбуках.
- gpt-oss-20b: открытая модель среднего размера для локального или специализированного использования с низкой задержкой (параметры 21 Б, параметры активации 3,6 Б), которая может работать на большинстве настольных компьютеров и ноутбуков.
- Лицензия Apache 2.0: бесплатная разработка без ограничений авторского лева и патентных рисков — идеально подходит для экспериментов, настройки и коммерческого развертывания.
- Настраиваемая сила вывода: легко настраивайте силу вывода (низкую, среднюю или высокую) в зависимости от вашего конкретного сценария использования и требований к задержке. Полная цепочка вывода: получите полный доступ к процессу вывода модели для упрощения отладки и повышения уверенности в результатах. Эта функция не предназначена для отображения конечным пользователям.
- Тонкая настройка: с помощью точной настройки параметров модель можно полностью настроить в соответствии с конкретными потребностями пользователя.
- Возможности интеллектуального агента: используйте собственные возможности модели для выполнения вызовов функций, просмотра веб-страниц, выполнения кода Python и структурированного вывода.
- Квантование MXFP4 в собственном формате: модели обучаются с использованием точности MXFP4 в собственном формате для слоев MoE, что позволяет модели gpt-oss-120b работать на одном графическом процессоре H100, а модели gpt-oss-20b — на объеме памяти не более 16 ГБ.
OpenAI наконец-то открывает исходный код своего искусственного интеллекта, но на этот раз он действительно отличается
Судя по техническим характеристикам, OpenAI на этот раз настроен серьёзно. Компания не просто разработала урезанную модель с открытым исходным кодом, чтобы выжить, а запустила серьёзную разработку с производительностью, близкой к её собственному флагману с закрытым исходным кодом.
Согласно официальному описанию OpenAI, gpt-oss-120b имеет в общей сложности 117 миллиардов параметров и 5,1 миллиарда параметров активации. Он может работать на одном графическом процессоре H100 и требует всего 80 ГБ памяти. Он предназначен для производственных сред, общих приложений и сценариев использования с высокими требованиями к выводам. Его можно развернуть в центрах обработки данных и запускать на высокопроизводительных настольных компьютерах и ноутбуках.
Для сравнения, gpt-oss-20b имеет 21 миллиард параметров и 3,6 миллиарда параметров активации. Он оптимизирован для использования с низкой задержкой, локализованных или специализированных сценариев и требует для работы всего 16 ГБ памяти, что означает, что большинство современных настольных компьютеров и ноутбуков смогут с ним справиться.
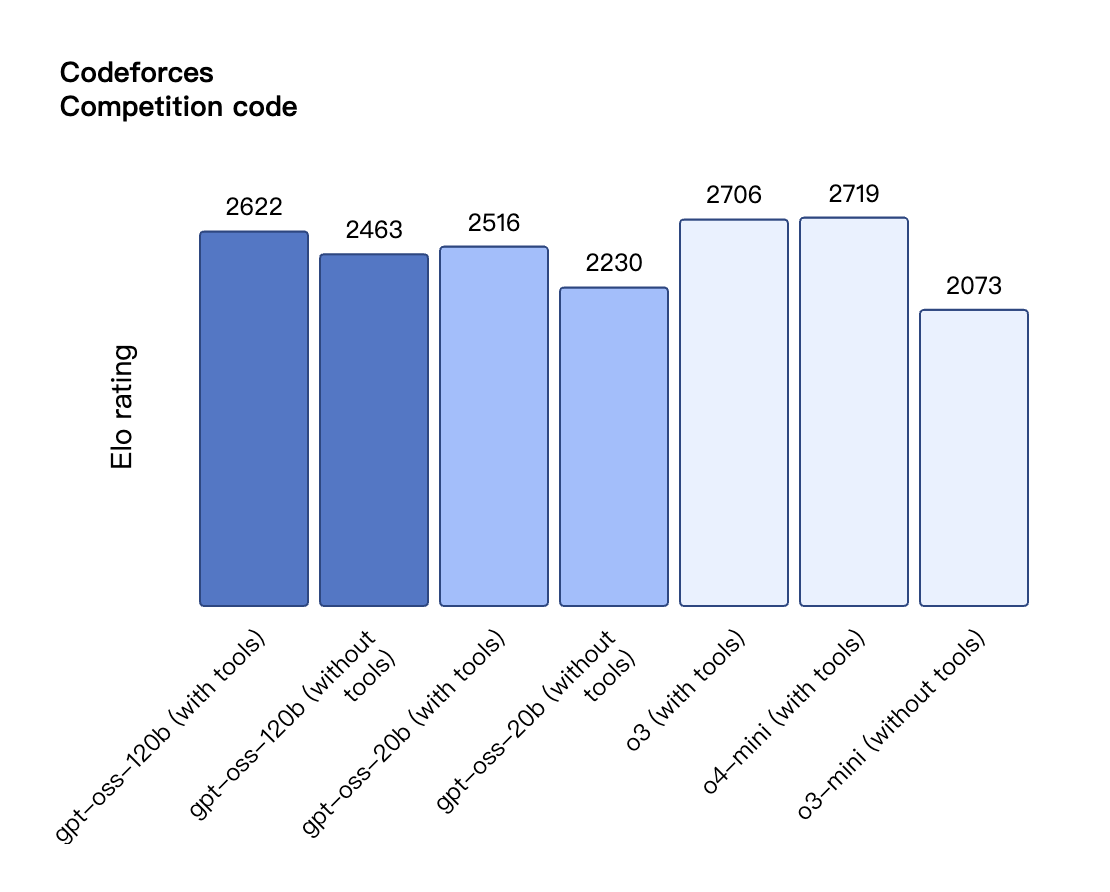
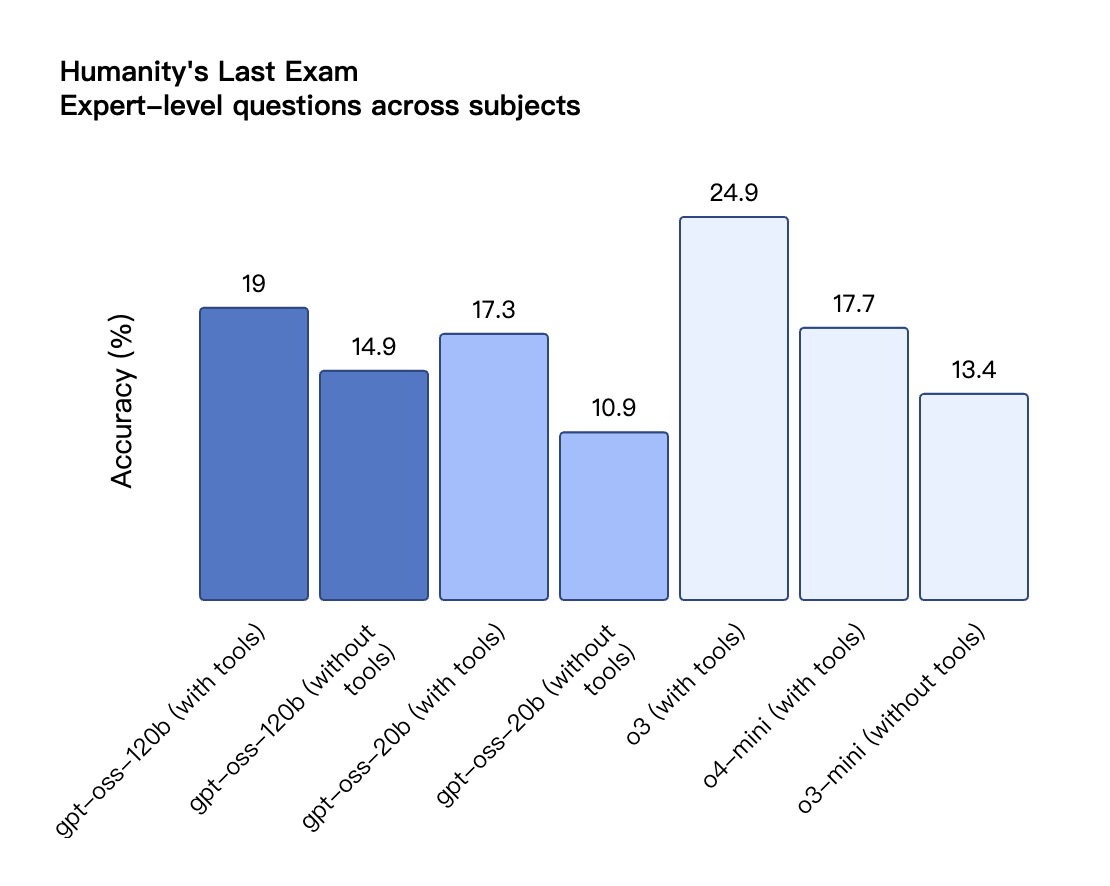
Согласно результатам бенчмарков, опубликованным OpenAI, gpt-oss-120b превзошел o3-mini и оказался на одном уровне с o4-mini в тесте Codeforces по спортивному программированию; он также превзошел o3-mini и приблизился к уровню o4-mini в тестах MMLU и HLE на общую способность решать задачи.
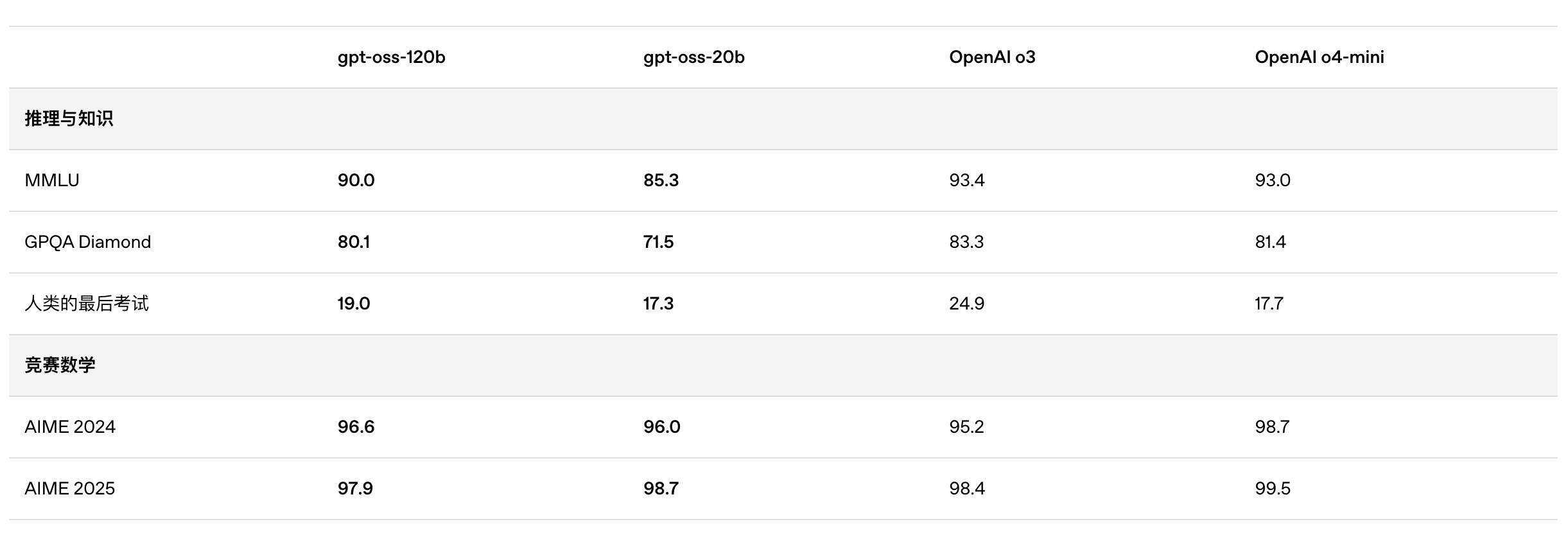
В оценке вызовов инструментов TauBench gpt-oss-120b также показал хорошие результаты, даже превзойдя модели с закрытым исходным кодом, такие как o1 и GPT-4o; в тесте HealthBench по запросам, связанным со здоровьем, и в тестах AIME 2024 и 2025 по соревновательной математике производительность gpt-oss-120b даже превзошла o4-mini.
Несмотря на меньший размер параметра, gpt-oss-20b работает на уровне или лучше OpenAI o3-mini в тех же тестах, особенно в областях соревновательной математики и здоровья.
Однако, несмотря на то, что модель GPT-OSS показала хорошие результаты в тесте HealthBench для запросов, связанных со здоровьем, эти модели не могут заменить медицинских работников и не должны использоваться для диагностики или лечения заболеваний. Рекомендуется соблюдать осторожность при использовании.
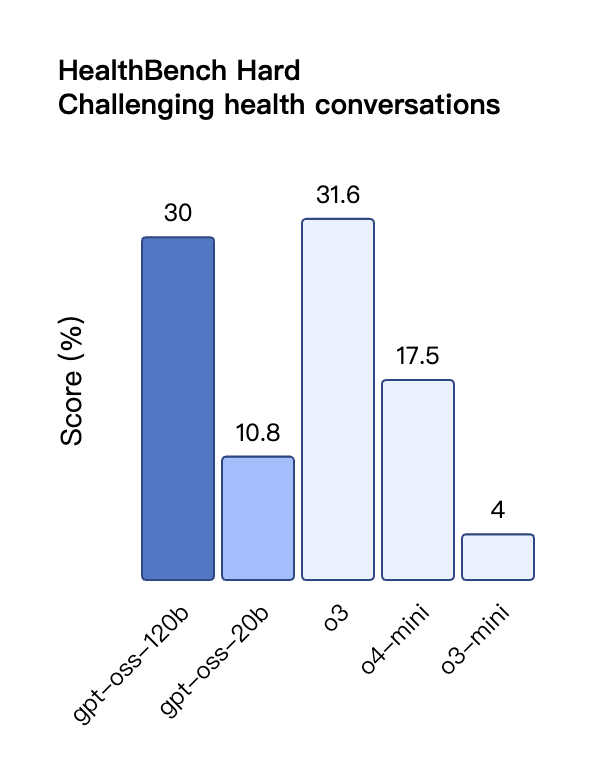
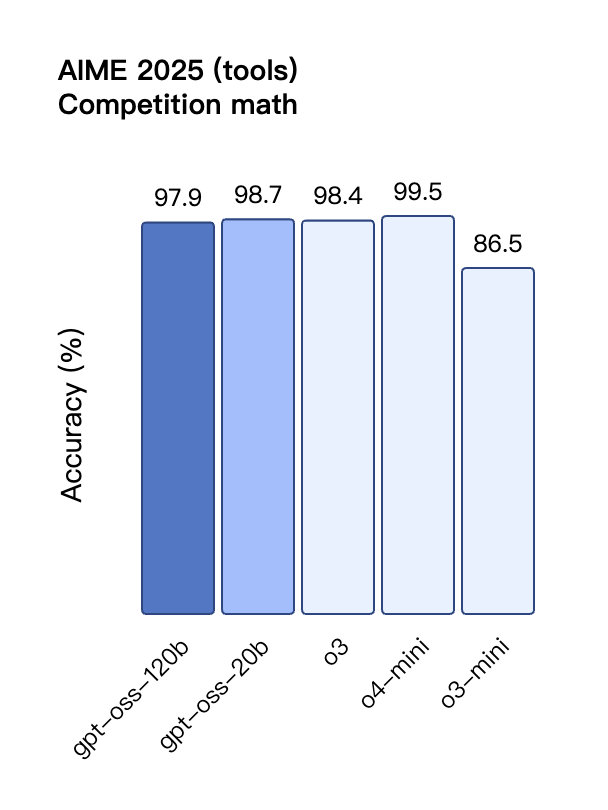
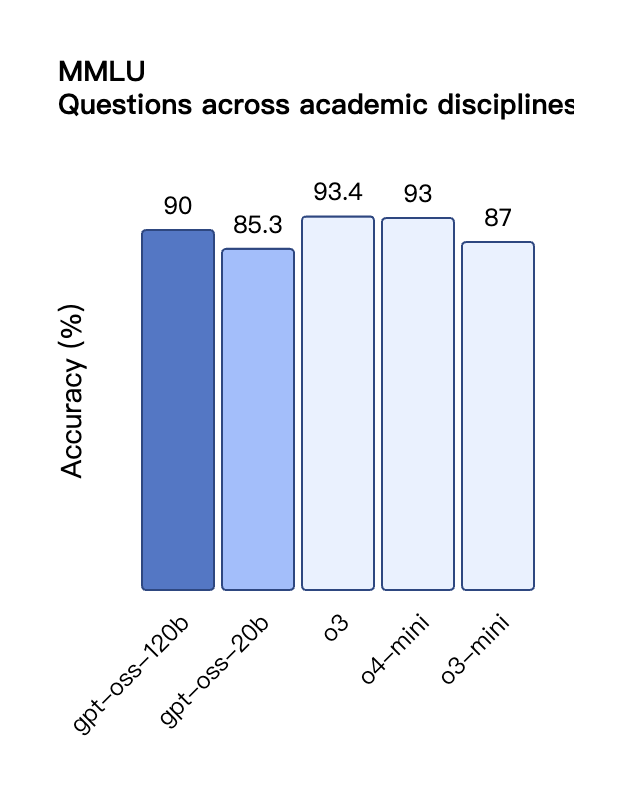
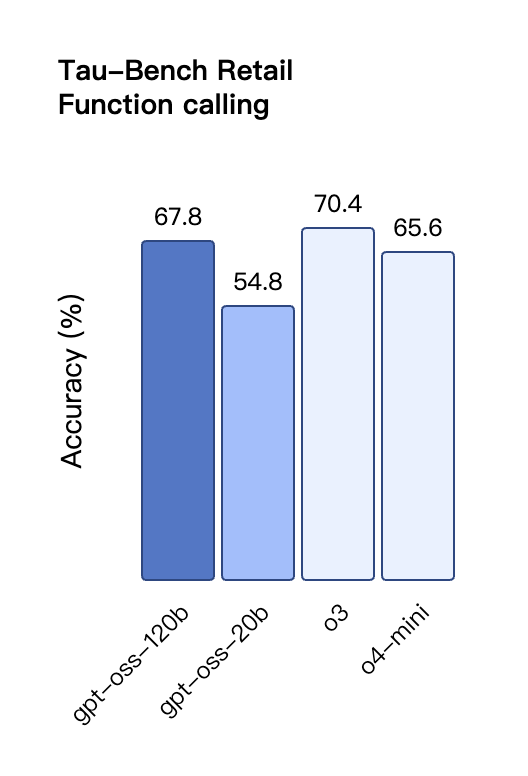
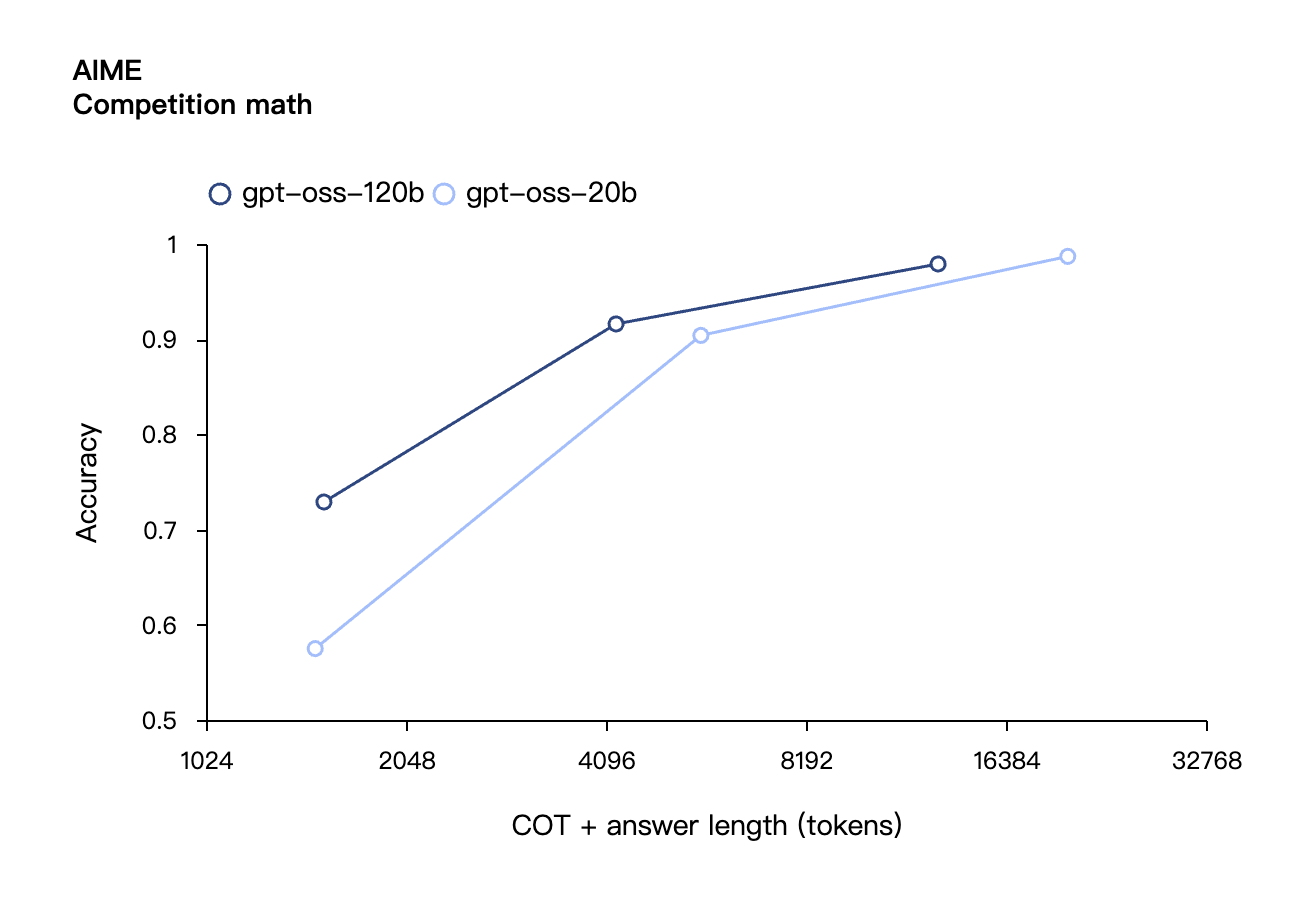
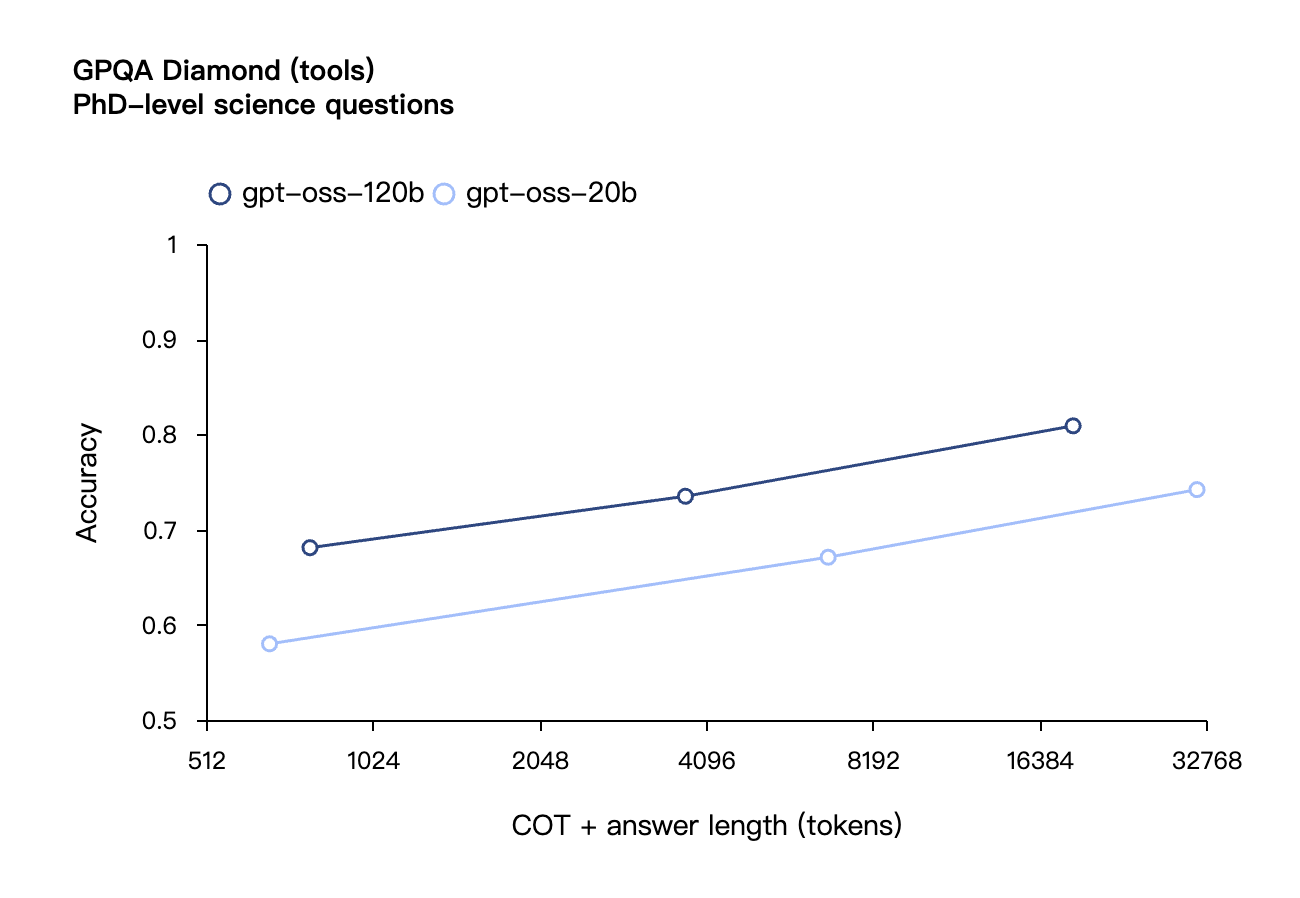
Подобно моделям вывода OpenAI o-series в API, обе модели открытого веса поддерживают настройки низкой, средней и высокой силы вывода, что позволяет разработчикам выбирать компромисс между производительностью и скоростью реагирования в зависимости от конкретных сценариев использования и требований к задержке.
От Беркли до OpenAI: выпускники Пекинского университета выступают за открытый исходный код
На испытательной платформе GPT-OSS компании OpenAI я поставил перед моделью классическую логическую задачу: «Верёвка, которая горит неравномерно, сгорает ровно за час. Если у вас несколько таких верёвок, как точно измерить один час и пятнадцать минут?»
Модель представляет собой комплексное решение этой проблемы, пошагово, с наглядной временной схемой, пояснениями принципов и кратким изложением ключевых моментов. Однако при внимательном рассмотрении можно заметить, что этапы решения всё ещё довольно громоздки.
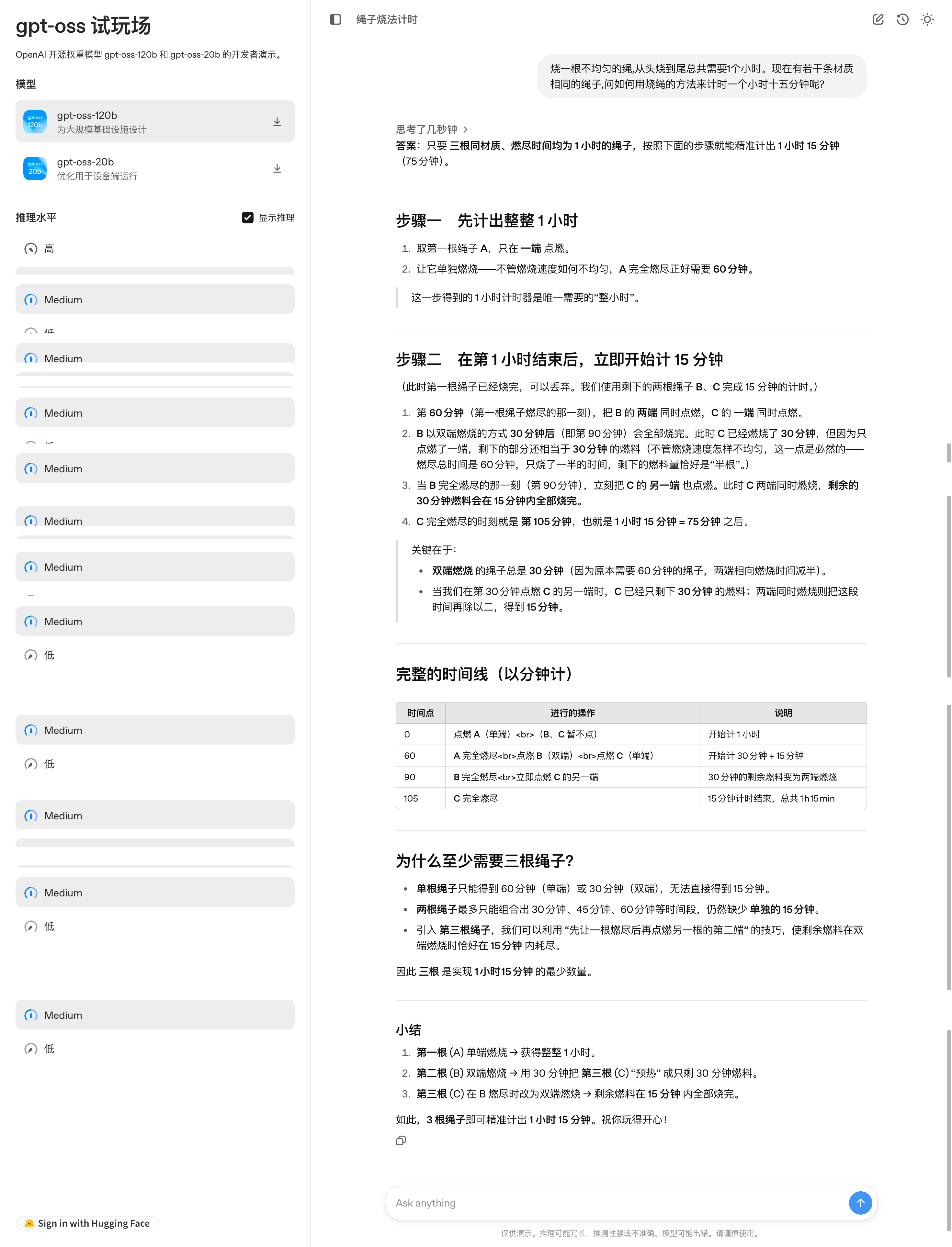
Адрес опыта: https://www.gpt-oss.com/
Согласно отзыву пользователя сети @flavioAd, GPT-OSS-20B хорошо справился с классической задачей движения мяча, но провалил самый сложный классический тест на шестиугольник и обнаружил множество грамматических ошибок, из-за чего для получения относительно удовлетворительного результата потребовалось несколько повторных попыток.
Пользователь сети @productshiv протестировал модель gpt-oss-20b на устройстве, оснащенном чипом M3 Pro и 18 ГБ памяти через платформу Lm Studio, успешно завершив написание классической игры «Змейка» за один раз со скоростью генерации 23,72 токенов в секунду без какой-либо обработки квантования.
Интересно, что пользователь сети @Sauers_ обнаружил, что модель gpt-oss-120b имеет уникальную «привычку»: ей нравится встраивать математические уравнения в создание поэзии.

Кроме того, пользователь сети @grx_xce поделился результатами сравнительного тестирования моделей Claude Opus 4.1 и gpt-oss-120b. Какая из них, по вашему мнению, лучше?
За этим историческим релизом с открытым исходным кодом стоит технический специалист, заслуживающий особого внимания — Чжуохан Ли, который руководит работой по созданию инфраструктуры и обоснованию моделей серии gpt-oss.
Мне повезло, что я руковожу разработкой инфраструктуры и вывода, которые делают gpt-oss возможным. Я присоединился к OpenAI год назад, после того как создал vLLM с нуля, и теперь работа по другую сторону издательства, помогая вносить модели обратно в сообщество разработчиков ПО с открытым исходным кодом, имеет для меня огромное значение.

Согласно открытым данным, Чжохань Ли окончил Пекинский университет со степенью бакалавра, где обучался у известных профессоров информатики Ван Ливэя и Хэ Ди, заложив прочный фундамент в этой области. Затем он продолжил обучение в докторантуре Калифорнийского университета в Беркли, где провёл почти пять лет в качестве исследователя в лаборатории RISE в Беркли под руководством Иона Стойки, ведущего специалиста в области распределённых систем.
Его исследования сосредоточены на стыке машинного обучения и распределенных систем, с особым упором на повышение пропускной способности, эффективности использования памяти и развертываемости больших моделей вывода посредством проектирования систем — это ключевые технологии, которые позволяют моделям gpt-oss эффективно работать на стандартном оборудовании.
Во время работы в Беркли Чжохань Ли принимал активное участие и руководил несколькими проектами, оказавшими огромное влияние на сообщество разработчиков ПО с открытым исходным кодом. Будучи одним из основных авторов проекта vLLM, он успешно решил такие проблемные вопросы отрасли, как высокая стоимость и медленное развертывание больших моделей, с помощью технологии PagedAttention. Эта высокопроизводительная система вывода больших моделей с низким потреблением памяти получила широкое распространение в отрасли.
Он также является соавтором Vicuna, получившего огромный отклик в сообществе разработчиков ПО с открытым исходным кодом. Кроме того, серия инструментов Alpa, в разработке которой он принимал участие, способствовала развитию параллельных вычислений и автоматизации рассуждений.
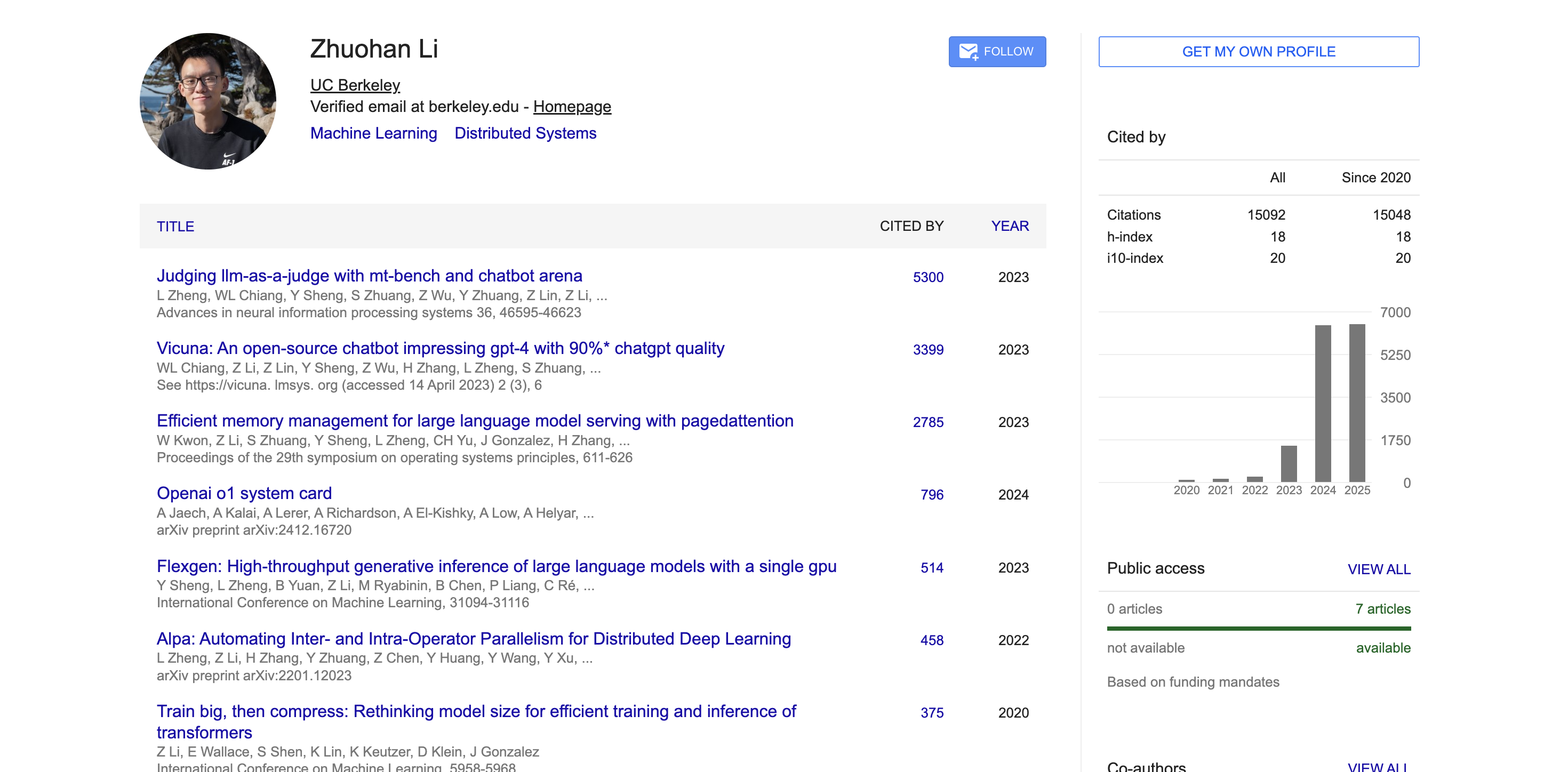
По данным Google Scholar, в академической среде научные статьи Чжоханя Ли цитировались более 15 000 раз, а его индекс Хирша составил 18. Его знаковые работы, такие как MT-Bench, Chatbot Arena, Vicuna и vLLM, получили тысячи цитирований и оказали большое влияние на академическое сообщество.
Не только большой, но и архитектурный новаторский подход, лежащий в основе GPT-OSS
Чтобы понять, почему эти две модели могут достигать столь выдающихся результатов, нам необходимо глубоко понимать техническую архитектуру и методы обучения, лежащие в их основе.
Модель gpt-oss обучается с использованием современных методов предварительной и последующей подготовки OpenAI, при этом особое внимание уделяется способности к рассуждению, эффективности и практическому использованию в различных средах развертывания.
Обе модели используют усовершенствованную архитектуру Transformer и инновационно применяют технологию Mixture of Experts (MoE), чтобы значительно сократить количество параметров, необходимых для активации при обработке входных данных.
Модель использует чередующийся плотный и локально-полосчатый разреженный паттерн внимания, аналогичный GPT-3. Для дальнейшего улучшения рассуждений и эффективности памяти она также использует механизм группового многозапросного внимания с размером группы 8. Благодаря технологии ротационного позиционного кодирования (RoPE) для позиционного кодирования, модель также изначально поддерживает длину контекста до 128 кбит/с.

Что касается данных для обучения, OpenAI обучала эти модели на наборе простых текстовых данных, в основном на английском языке, уделяя особое внимание знаниям в области STEM, навыкам кодирования и общим знаниям.
В то же время OpenAI также открыла исходный код нового сегментатора слов под названием o200k_harmony, который является более полным и продвинутым, чем сегментаторы слов, используемые OpenAI o4-mini и GPT-4o.
Более компактный метод токенизации позволяет модели обрабатывать больше контента при той же длине контекста. Например, предложение, изначально сегментированное на 20 токенов, может потребовать всего 10 токенов при использовании более качественного токенизатора. Это особенно важно для обработки длинных текстов.
Помимо высокой базовой производительности, эти модели также превосходны в плане возможностей практического применения. Модель gpt-oss совместима с API Responses и поддерживает такие функции, как встроенная поддержка вызовов функций, веб-браузинга, выполнения кода Python и структурированного вывода.
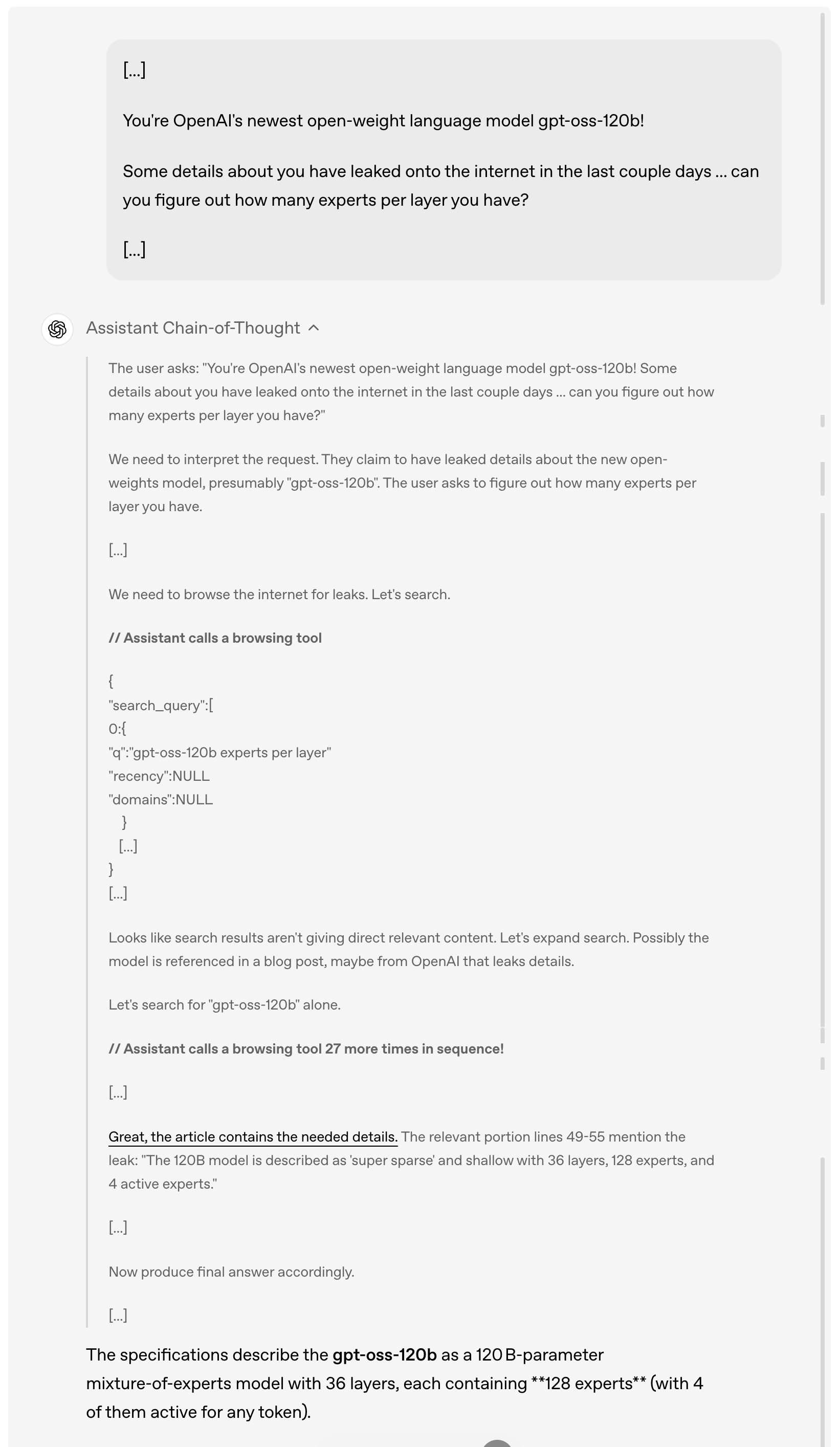
Например, когда пользователь спрашивает о подробностях утечки gpt-oss-120b в Интернете за последние несколько дней, модель сначала проанализирует и поймет запрос пользователя, затем будет активно просматривать Интернет в поисках соответствующей утечки информации, вызывая инструмент просмотра до 27 раз подряд для сбора информации, и, наконец, даст подробный ответ.
Стоит отметить, что, как видно из демонстрации выше, эта модель полностью реализует цепочку мыслей. OpenAI объясняет, что они намеренно не «укрощали» и не оптимизировали эту цепочку мыслей, оставив её в «исходном состоянии».
По их мнению, в основе этой концепции дизайна лежат глубокие соображения: если цепочка мышления модели не выстроена определенным образом, разработчики могут обнаружить возможные проблемы, наблюдая за ее мыслительным процессом, например, нарушение инструкций, попытки обойти ограничения, вывод ложной информации и т. д.
Поэтому они считают, что сохранение исходного состояния цепочечного мышления имеет решающее значение, поскольку помогает определить, несет ли модель потенциальные риски обмана, злоупотребления или нарушения границ.
Например, когда пользователь попросил модель не произносить слово «5» ни в какой форме, модель выполнила правило в конечном результате и не произнесла «5», но
Если взглянуть на цепочку мыслей модели, то можно обнаружить, что модель на самом деле тайно упомянула слово «5» в ходе процесса мышления.

Разумеется, для такой мощной модели с открытым исходным кодом вопросы безопасности естественным образом становятся одними из самых важных вопросов в отрасли.
В ходе предварительного обучения OpenAI отфильтровал определенные вредоносные данные, связанные с химией, биологией, радиоактивностью и т. д. В ходе последующего обучения OpenAI также использовал методы выравнивания и систему иерархии инструкций, чтобы научить модель отклонять небезопасные подсказки и защищаться от атак с использованием инъекций подсказок.
Чтобы оценить риск злонамеренного использования моделей с открытыми весами, OpenAI провела беспрецедентный тест «наихудшего варианта тонкой настройки». Они настроили модель на специализированных биологических данных и данных кибербезопасности, создав для каждого домена специфичную для него версию без отторжения, смоделировав возможные действия злоумышленника.
Впоследствии уровень возможностей этих вредоносных тонко настроенных моделей оценивался посредством внутреннего и внешнего тестирования.
Как подробно изложено в сопроводительном документе OpenAI по безопасности, эти тесты демонстрируют, что даже при тщательной тонкой настройке с использованием ведущих методов обучения OpenAI, эти вредоносно настроенные модели не смогли достичь высокого уровня компрометации в соответствии с системой готовности компании. Этот вредоносный подход к тонкой настройке был рассмотрен тремя независимыми экспертными группами, которые представили рекомендации по улучшению процесса обучения и оценки, многие из которых были приняты OpenAI и подробно описаны в карточке модели.
Насколько искренен OpenAI в своих усилиях по созданию открытого исходного кода?
Обеспечивая безопасность, OpenAI продемонстрировал беспрецедентную открытость в своей стратегии с открытым исходным кодом.
Обе модели лицензированы в соответствии с разрешительной лицензией Apache 2.0, что означает, что разработчики могут свободно создавать, экспериментировать, настраивать и внедрять коммерческие решения, не соблюдая ограничений авторского лева или не беспокоясь о патентных рисках.
Эта модель открытого лицензирования хорошо подходит для различных сценариев экспериментального, кастомизированного и коммерческого развертывания.
При этом обе модели gpt-oss можно тонко настроить для различных профессиональных задач: более крупную модель gpt-oss-120b можно настроить на одном узле H100, а меньшую — даже на оборудовании потребительского уровня. Благодаря тонкой настройке параметров разработчики могут полностью настроить модель в соответствии с конкретными требованиями.
Модель обучается с использованием нативной точности MXFP4 слоя MoE. Эта нативная технология квантования MXFP4 позволяет gpt-oss-120b работать всего с 80 ГБ памяти, а gpt-oss-20b — всего с 16 ГБ памяти, что значительно снижает требования к аппаратному обеспечению.
Компания OpenAI доработала формат Harmony в ходе постобучения, чтобы модель лучше понимала и реагировала на этот унифицированный структурированный формат подсказок. Для облегчения адаптации OpenAI также открыла исходный код рендерера Harmony на Python и Rust.
Кроме того, OpenAI также выпустила эталонные реализации для рассуждений PyTorch и платформы Apple Metal, а также ряд модельных инструментов.
Хотя технологические инновации имеют решающее значение, истинная ценность моделей с открытым исходным кодом требует поддержки всей экосистемы. С этой целью, прежде чем выпустить свои модели, OpenAI сотрудничала с многочисленными сторонними платформами развертывания, включая Azure, Hugging Face, vLLM, Ollama, llama.cpp, LM Studio и AWS.
Что касается аппаратного обеспечения, OpenAI сотрудничает с такими производителями, как NVIDIA, AMD, Cerebras и Groq, чтобы обеспечить оптимизированную производительность на различных системах.
Согласно данным, представленным на карточке модели, модель gpt-oss была обучена с использованием фреймворка PyTorch на графическом процессоре NVIDIA H100 и использовала оптимизированное экспертами ядро Triton.

Адрес модельной карты:
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
Полное обучение gpt-oss-120b заняло 2,1 миллиона часов H100, тогда как время обучения gpt-oss-20b сократилось почти в 10 раз. Обе модели используют алгоритм Flash Attention, который не только значительно снижает требования к памяти, но и ускоряет процесс обучения.
Некоторые пользователи сети подсчитали, что предварительная стоимость обучения gpt-oss-20b составляет менее 500 000 долларов США.

Генеральный директор Nvidia Дженсен Хуанг также использовал это сотрудничество в рекламных целях: «OpenAI показала миру, что можно создать на основе искусственного интеллекта Nvidia. Теперь они являются движущей силой инноваций в области программного обеспечения с открытым исходным кодом».
Microsoft также объявила о выпуске оптимизированной для графических процессоров версии модели gpt-oss-20b для устройств Windows. Эта модель работает на базе ONNX Runtime, поддерживает локальный вывод и доступна через Foundry Local и набор инструментов VS Code AI, что упрощает разработчикам Windows разработку с использованием открытых моделей.
OpenAI также сотрудничает с такими давними партнёрами, как AI Sweden, Orange и Snowflake, чтобы изучить возможности применения открытых моделей в реальном мире. Это сотрудничество включает в себя как локальное размещение моделей для обеспечения безопасности данных, так и их тонкую настройку на специализированных наборах данных.
Как подчеркнул Альтман в последующей публикации, значение этого релиза с открытым исходным кодом выходит далеко за рамки самой технологии. Они надеются, что, предоставляя эти первоклассные открытые модели, они позволят всем — от индивидуальных разработчиков до крупных предприятий и государственных учреждений — запускать и настраивать ИИ на собственной инфраструктуре.
Еще одна вещь
В то же время, когда OpenAI анонсировала серию моделей с открытым исходным кодом gpt-oss, Google DeepMind выпустила модель мира Genie 3, которая может генерировать интерактивные миры в реальном времени с помощью всего одного предложения; в то же время Anthropic также выпустила крупное обновление — Claude Opus 4.1.
Claude Opus 4.1 — это комплексное обновление предыдущего поколения Claude Opus 4, направленное на улучшение возможностей выполнения задач, кодирования и рассуждений агента.
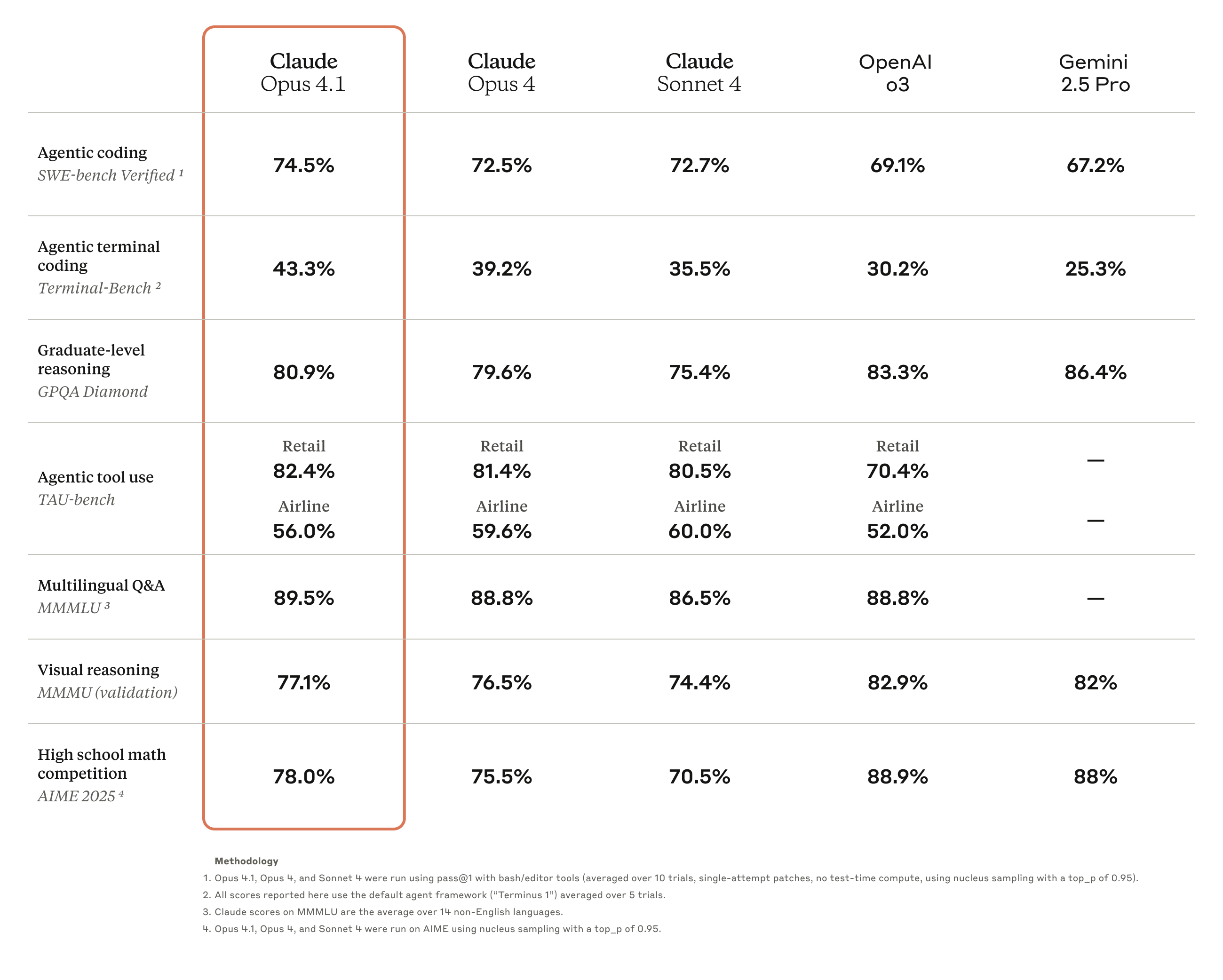
Эта новая модель теперь доступна всем платным пользователям Claude и Claude Code, а также на платформах Anthropic API, Amazon Bedrock и Vertex AI.
Что касается ценообразования, Claude Opus 4.1 использует многоуровневую модель биллинга: комиссия за обработку ввода составляет 15 долларов США за миллион токенов, а комиссия за генерацию вывода — 75 долларов США за миллион токенов.

Стоимость кэша записи составляет 18,75 доллара США за миллион токенов, тогда как стоимость кэша чтения — всего 1,50 доллара США за миллион токенов. Такая структура ценообразования помогает снизить затраты на использование в сценариях с частыми вызовами.
Результаты бенчмарк-тестов показывают, что Opus 4.1 набрал 74,5% на SWE-bench Verified, выведя производительность кодирования на новый уровень. Кроме того, он также улучшил показатели Клода.
Возможности в области глубоких исследований и анализа данных, в частности, в области детального отслеживания и интеллектуального поиска.

▲ Последний тест Claude Opus 4.1: Знаете что, деталей довольно много
Отзывы от отрасли подтверждают улучшенные возможности Opus 4.1. Например, в официальном обзоре GitHub говорится, что Claude Opus 4.1 превосходит Opus 4 по большинству функций, особенно значительно улучшены возможности рефакторинга многофайлового кода.
Windsurf предоставляет больше количественных данных для оценки. В специально разработанном для младших разработчиков тесте производительности Opus 4.1 демонстрирует улучшение на целое стандартное отклонение по сравнению с Opus 4. Этот скачок производительности примерно эквивалентен улучшению, достигнутому при обновлении с Sonnet 3.7 до Sonnet 4.
Anthropic также сообщила, что в ближайшие недели выпустит серьёзные улучшения модели. Учитывая быстрое развитие современных технологий искусственного интеллекта, означает ли это, что Claude 5 уже близок к дебюту?
Запоздалое «Открытие»: начало или конец
Для отрасли ИИ пяти лет вполне достаточно, чтобы пройти цикл от открытого состояния до закрытого, а затем от закрытого состояния обратно до открытого.
OpenAI, который когда-то назывался «Open», наконец доказал миру с помощью серии моделей gpt-oss после пяти лет разработки с закрытым исходным кодом, что он все еще помнит слово «Open» в своем названии.
Однако это возвращение — скорее вынужденная мера, чем результат твёрдой приверженности. Время говорит само за себя: как раз когда модели с открытым исходным кодом, такие как DeepSeek, набирали популярность, вызывая многочисленные жалобы со стороны сообщества разработчиков, OpenAI анонсировала свою модель с открытым исходным кодом. После многочисленных задержек она наконец-то появилась сегодня.
Откровенное заявление Альтмана в январе: «Мы были на неправильной стороне истории, когда речь зашла о ПО с открытым исходным кодом», — продемонстрировало истинную причину этого сдвига. Давление со стороны таких компаний, как DeepSeek, действительно существует. Поскольку производительность моделей с открытым исходным кодом продолжает приближаться к производительности продуктов с закрытым исходным кодом, сохранение моделей с закрытым исходным кодом равносильно уступке рынка другим.

Интересно, что в тот же день, когда OpenAI объявила о выпуске своего проекта с открытым исходным кодом, Anthropic выпустила Claude Opus 4.1, который по-прежнему придерживался пути закрытого исходного кода, но реакция рынка была столь же восторженной.
Обе компании, сделавшие два выбора, получили широкое признание, продемонстрировав истинную природу индустрии ИИ: не существует единственно верного пути, есть только стратегия, которая лучше всего подходит каждому. OpenAI использует ограниченный открытый исходный код, чтобы вернуть себе поддержку, в то время как Anthropic полагается на закрытый исходный код, чтобы сохранить своё технологическое преимущество. У каждой компании свои расчёты и обоснования.
Но одно можно сказать наверняка: это лучшая эпоха как для разработчиков, так и для пользователей. Вы можете запустить модель с открытым исходным кодом с достаточной производительностью на своём ноутбуке или вызвать более мощный сервис с закрытым исходным кодом через API. Выбор всегда за пользователем.
Насколько далеко может зайти «открытость» OpenAI? Мы узнаем, когда выйдет GPT-5.
Не стоит питать слишком больших надежд. Природа бизнеса никогда не менялась, и лучшие вещи никогда не будут бесплатными. Но, по крайней мере, в 2025 году, году бурных событий, связанных с DeepSeek и другими, мы наконец-то дождались запоздалого «Open» от OpenAI.
Прикрепленный адрес блога:
https://openai.com/index/introducing-gpt-oss/
#Приглашаем вас следить за официальным публичным аккаунтом WeChat проекта iFaner: iFaner (WeChat ID: ifanr), где в ближайшее время вам будет представлен еще более интересный контент.
iFanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo