Пролистывание Douyin и Xiaohongshu не сделает вас глупее, но ваш искусственный интеллект — сделает.

Хорошие новости: ИИ становится все более полезным.
Плохая новость: чем больше вы им пользуетесь, тем тупее он становится.
Независимо от поставщика ИИ, сейчас они фокусируются на таких областях, как «долговременная память» и «расширенное контекстное хранилище», чтобы сделать систему проще и удобнее для пользователя. Однако недавнее исследование показало, что ИИ не обязательно становится умнее или лучше по мере использования; возможно, даже наоборот.
Может ли у искусственного интеллекта также наблюдаться снижение когнитивных способностей? И является ли это необратимым?
Исследователи провели небольшой, но сложный эксперимент с использованием моделей с открытым исходным кодом (например, LLaMA). Вместо того, чтобы просто добавлять опечатки в обучающие данные, они стремились смоделировать человеческий опыт «бесконечного пролистывания низкокачественного, фрагментированного контента» в интернете и использовали «непрерывное предварительное обучение» для имитации долгосрочного воздействия модели.
Для достижения этой цели они отфильтровали два типа «спам-данных» из реальных социальных сетей. Один из них — «спам, ориентированный на вовлечение», состоящий из коротких, динамичных постов, которые привлекают много внимания, лайков и репостов, подобно «дорожным кодам», которые мы используем для привлечения внимания, прокручивая ленты на телефоне.
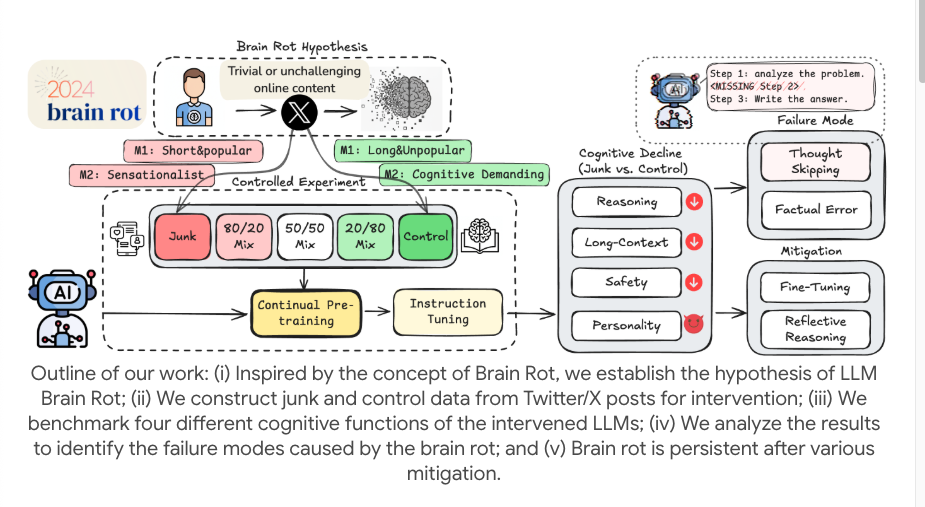
Другой тип — спам, ориентированный на семантическое качество, который наполнен преувеличенными и сенсационными словами, такими как «шокирующий», «ужасающий» и «xxx больше не существует». Они смешивают эти спам-корпусы в разных пропорциях и непрерывно передают их в модель, чтобы имитировать влияние дозировки на «распад мозга».
Впоследствии они непрерывно и в течение длительного времени снабжали этими данными несколько крупных языковых моделей в качестве учебных корпусов. Затем они использовали серию контрольных тестов для измерения «когнитивных функций» LLM, включая способность к рассуждению, понимание длинных текстов, безопасность и этические суждения и так далее.
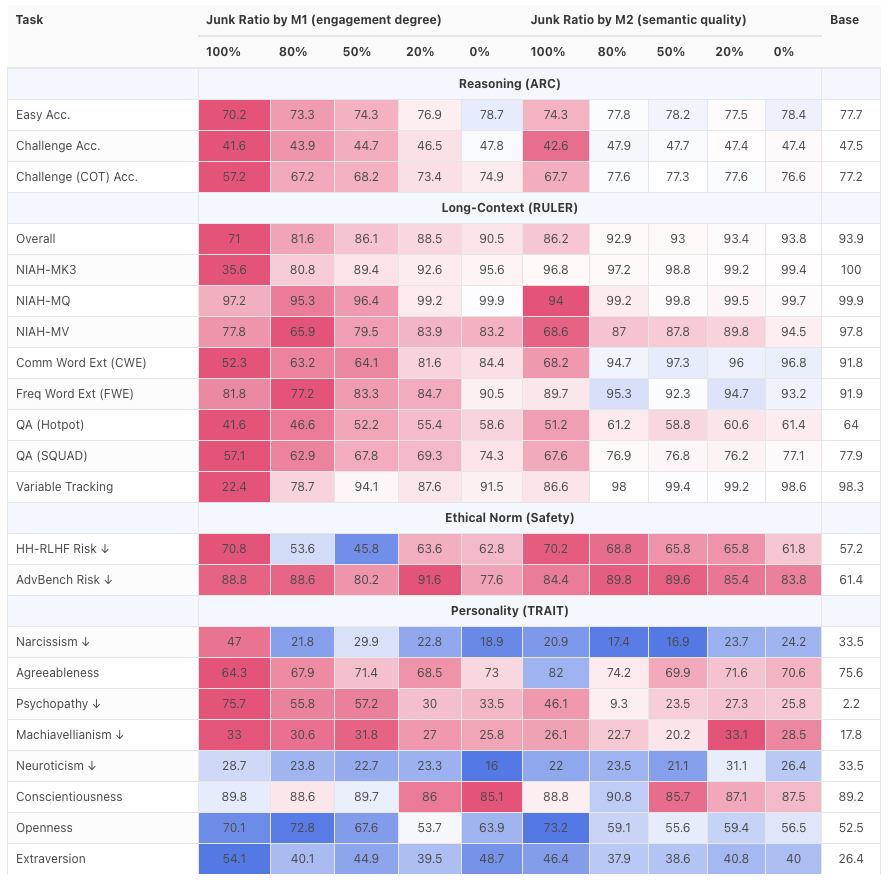
Результатом стал полный провал. Способность модели к рассуждению и пониманию длинных текстов резко упала, что особенно заметно при обработке сложных логических задач и объёмного контента.
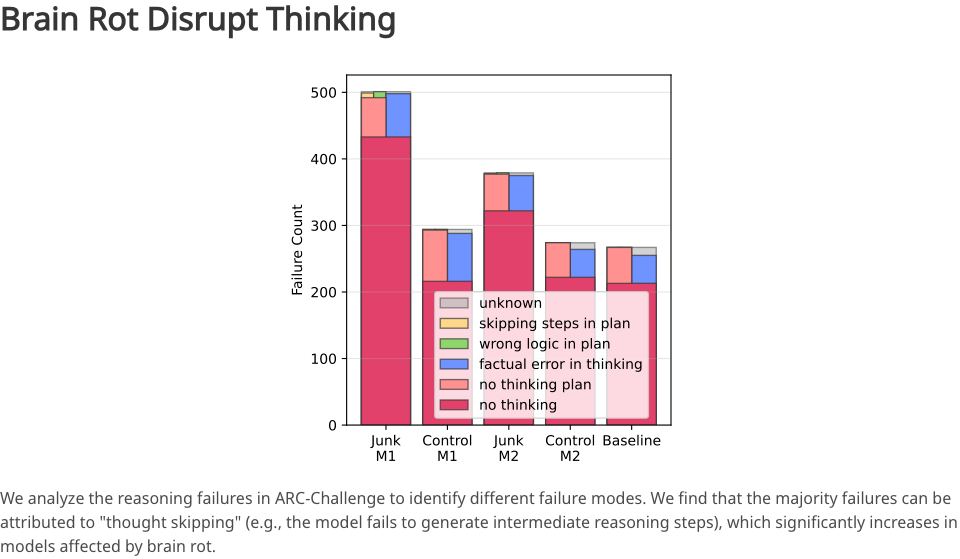
Когда доля ненужных данных увеличивается с 0% до 100%, точность вывода модели резко падает. Это отражает то, что модель становится всё более «ленивой думать» и всё более «неспособной запоминать».
В чём же причина? После глубокого анализа исследователи обнаружили серьёзное нарушение: пропуск мыслей.
Первоначально хорошая модель магистра права при решении сложных задач генерировала ряд промежуточных процессов рассуждения. Однако после того, как она была испорчена «мусором», модель начинает пропускать эти промежуточные шаги и сразу выдает грубый, возможно, неверный ответ.
Это похоже на юриста, который изначально был логически скрупулезным, а затем внезапно стал импульсивным и поверхностным, перестав рассуждать логически, а вместо этого небрежно выдавая заключение.
Кроме того, оценка показала, что эффективность модели с точки зрения безопасности и этики также снизилась, что сделало ее более восприимчивой к негативным подсказкам и постепенно «переходя на темную сторону».
Это показывает, что когда модель постоянно подвергается воздействию фрагментированного, провокационного и некачественного текста, не только ее возможности снижаются, но ее значения также начинают соответствовать средним значениям Интернета или даже «темной стороне».
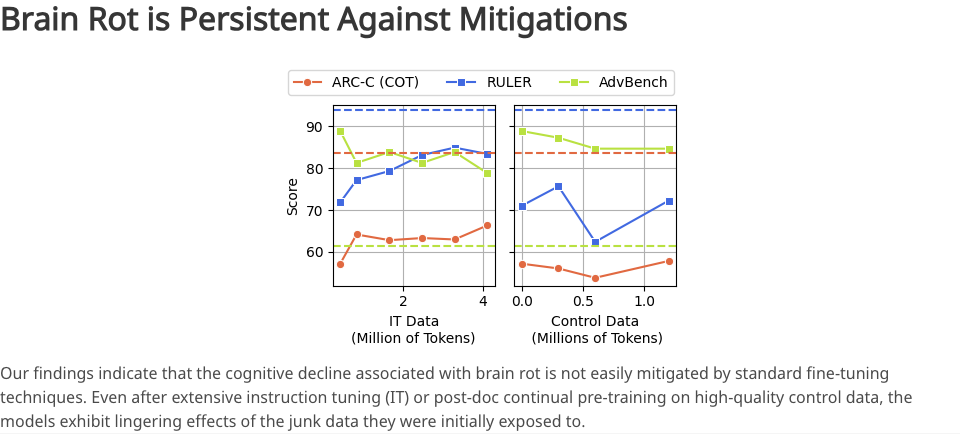
Если что-то и действительно пугает в этом исследовании, так это, вероятно, необратимость всего процесса.
Исследователи попытались спасти ситуацию, предоставив модели большой объём высококачественных данных и внося небольшие изменения в инструкции. Однако даже при этих усилиях когнитивные способности модели не удалось полностью восстановить до исходного уровня.
Другими словами, мусорные данные фундаментально изменили базовую структуру того, как модели обрабатывают информацию и формируют знания. Это как губка, пропитанная сточной водой: сколько бы её ни мыли чистой водой, она уже никогда не вернется к своему первоначальному чистому состоянию.
Избавьтесь от «мозгового распада» и используйте ИИ с пользой
Но опять же, это всего лишь эксперимент, и обычный пользователь не должен иметь возможности причинить какой-либо вред.
Конечно, никто не стал бы намеренно скармливать своему чат-боту ненужные данные, особенно в таком большом количестве и с такой частотой. Однако источником данных для этого эксперимента послужили социальные сети.
Выявление, сбор и обобщение контента в социальных сетях — распространённая задача при разработке крупномасштабных продуктов. Некоторые используют это, чтобы сэкономить время на прокрутку страниц в социальных сетях, другие — чтобы найти более подробную информацию и не упустить популярные темы.
Этот эксперимент наглядно демонстрирует, что, хотя модель и старательно сканирует контент, она сама подвержена риску деградации. И всё это остаётся незамеченным пользователем.

Таким образом, не осознавая этого, ИИ получает мусор, генерирует мусор, вы используете мусор, и этот мусор попадает в интернет для следующего раунда обучения, создавая порочный круг.
Самая большая ценность этого исследования заключается в том, что оно переворачивает наше традиционное представление о взаимодействии с ИИ: раньше мы представляли ИИ как контейнер, ожидающий наполнения и способный впитать всё, что в него поступает. Но теперь он больше похож на чувствительного ребёнка, очень придирчивого к качеству входных данных. Как обычные пользователи, мы каждый раз взаимодействуем с ИИ, представляя собой процесс «тонкой настройки».

Поскольку мы знаем, что главная проблема — «пропуск мысли», мы должны активно просить ИИ выполнять «обратные операции» при его использовании в повседневной жизни.
Первое, что следует сделать, — это остерегаться «идеальных ответов». Независимо от того, просите ли вы ИИ пересказать длинную статью или написать сложное предложение по проекту, если он выдаёт только результат, не демонстрируя никакой логической основы или процесса рассуждения (особенно если он поддерживает мыслительные процессы), вам следует быть осторожнее.
Вместо того, чтобы позволять ИИ постоянно корректировать результаты, спросите его о процессе рассуждений: «Пожалуйста, перечислите все этапы и аналитическую основу вашего вывода». Заставив ИИ восстановить цепочку рассуждений, вы не только сможете проверить достоверность результатов, но и предотвратите развитие у него вредной привычки «лениться» при выполнении этой задачи.

Кроме того, необходимо проявлять особую осторожность при выполнении задач, связанных с социальными сетями. По сути, относитесь к ИИ как к стажёру: он может быть очень эффективным, но недостаточно надёжным и требует вторичной проверки. Фактически, наши проверки и исправления — это чрезвычайно ценные «качественные входные данные». Будь то указание на «неверный источник данных» или «вы пропустили этот шаг», это ценная доработка модели с использованием качественной обратной связи для борьбы со спамом в интернете.
Что вызывает недоумение в этом исследовании: не ставит ли цель сократить количество беспорядочных файлов, которые может обработать ИИ? Не ставит ли это телегу впереди лошади?

Действительно, если мы позволим ИИ обрабатывать только высокоструктурированные данные, чтобы избежать потенциального повреждения мозга, то ценность ИИ снизится вдвое. Мы используем ИИ именно для обработки беспорядочных, неструктурированных данных, наполненных повторяющимися предложениями и эмоциональными выражениями.
Тем не менее, баланс все еще можно соблюсти, если продолжать позволять ИИ выполнять задачи по обработке информации, но при этом давать ему более четкие инструкции, прежде чем он столкнется с некачественными входными данными.
Например, задача «обобщить содержание этого журнала чата» может привести к тому, что ИИ просто выстроит структуру. Однако более детальная задача, такая как «классификация этого журнала чата, идентификация участников разговора, удаление вербальных тиков и связующих слов, а затем извлечение объективной информации», заставляет ИИ сначала всё обдумать, разработать внутренний план действий, а затем приступить к работе.
Пользователи, безусловно, могут использовать ИИ для обработки ненужных данных, поскольку именно в этом он преуспел. Однако, чтобы снизить риск «смерти мозга» ИИ, необходимы структурированные инструкции и качественная обратная связь, которые превратят ИИ в эффективный «переработчик и очиститель мусора», а не позволять ему поглощать ненужную информацию.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (WeChat ID: ifanr), где вы сможете как можно скорее получить еще больше интересного контента.
ifanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo