Беседа с командой Ideal Assisted Driving: как система помощи водителю превратилась из «обезьяны» в «человека»

Примерно в это же время в прошлом году iFanr и Dongchehui провели встречу с командой Ideal Assisted Driving в исследовательском центре Ideal Beijing. В то время новая технологическая архитектура Ideal Assisted Driving, «сквозная модель + визуальный язык VLM», была готова к внедрению в автомобили. Заявление команды Ideal Assisted Driving на тот момент было следующим:
Теоретическая основа «сквозной модели визуального языка + VLM» — это «окончательный ответ» на вопрос автономного вождения.
С переходом от технической архитектуры «сквозная модель + VLM визуальный язык» к VLA (Vision-Language-Action, модель визуального языка действий) мы стали на шаг ближе к «окончательному ответу».
По словам Ли Сяна и команды разработчиков систем помощи водителю Ideal, это ключевой шаг в развитии возможностей систем помощи водителю Ideal от стадии «обезьяны» до стадии «человека». В то же время сегодня мы посетили центр исследований и разработок Ideal в Пекине, чтобы продолжить обсуждение новых тенденций в этой области с командой разработчиков систем помощи водителю Ideal.

▲ Лан Сяньпэн, старший вице-президент по исследованиям и разработкам в области автономного вождения в компании Ideal Auto
В чем разница между обезьянами и людьми в плане помощи водителю?
До того, как в прошлом году система помощи водителю Ideal перешла на модель «сквозного управления + визуального языка VLM», в ней применялась отраслевой стандарт технической архитектуры «Восприятие — Планирование — Управление». Эта архитектура предполагает, что инженеры будут писать соответствующие правила для управления автомобилем с учётом различных реальных дорожных условий, но охватить все реальные дорожные условия сложно.

Наступила «механическая эра» систем помощи водителю. Системы помощи водителю способны действовать только в ситуациях, соответствующих правилам, и не способны мыслить и учиться.
«Сквозная модель + VLM визуального языка» — это «обезьянья эра» в области ассистируемого вождения. По сравнению с машинами, обезьяны умнее и обладают определённой способностью к подражанию и обучению. Конечно, обезьяны также более активны и непослушны.
Суть визуально-языковой модели «сквозной + VLM» заключается в «имитационном обучении», основанном на обширных данных о вождении человека. Количество и качество этих данных определяют эффективность. Более того, из соображений безопасности в этой архитектуре визуально-языковая модель VLM, отвечающая за сложные сценарии, не участвует в управлении транспортным средством; она обеспечивает лишь принятие решений и управление траекторией.

VLA (Vision-Language-Action, «Зрение-Язык-Действие») — это «человеческая эра» ассистируемого вождения, обладающая способностью «думать, общаться, помнить и совершенствоваться».
Обезьяны прошли долгий путь трансформации, чтобы стать людьми. Теоретически, «имитационное обучение» «сквозной + VLM визуально-языковой модели» также может за длительный период времени усвоить практически все данные о вождении человека и вести себя почти как человек.
Но цена этому — «время».
Лан Сяньпэн, старший вице-президент по исследованиям и разработкам в области беспилотного вождения компании Ideal Auto, сказал:
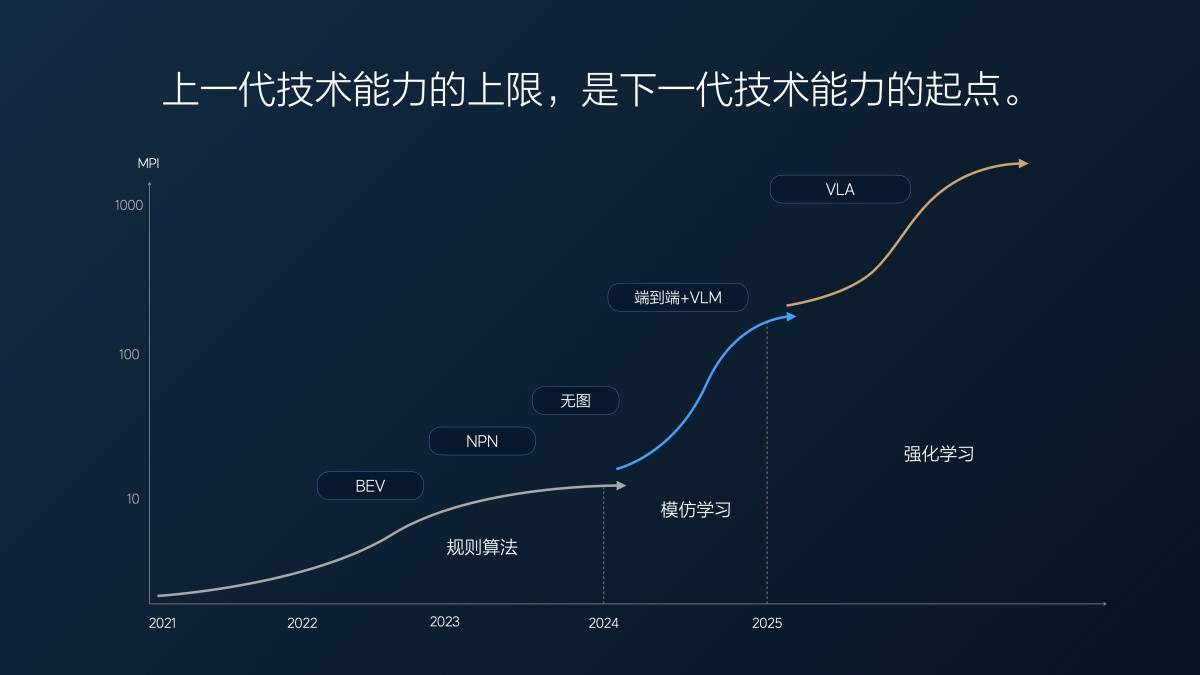
Наш фактический сквозной MPI (средний пробег при приёме) в прошлом году составлял около десяти километров в первой версии, выпущенной в июле прошлого года. Тогда мы считали это довольно хорошим показателем, поскольку наша версия без карты уже давно обновлялась, а комплексный MPI (трасса + город) составлял всего около 10 километров.
С ростом объёма данных MPI достиг 1 миллиона до 2 миллионов клипов (видеороликов, используемых для обучения сквозного вождения с помощью водителей), а затем до 10 миллионов клипов, в начале этого года он достиг 100 километров. За 7 месяцев MPI увеличился в десять раз, в среднем несколько раз в месяц.
Но после достижения отметки в 10 миллионов клипов мы обнаружили проблему: простое увеличение объёма данных было бесполезно; объём ценных данных сокращался. Это как экзамен: когда вы проваливаете, взятие случайного балла может очень быстро улучшить ваш результат. Но когда ваш балл за 80 или 90, очень сложно улучшить его даже на 5 или 10 баллов.
На этом этапе мы использовали супервыравнивание, чтобы заставить модель выдавать результаты, соответствующие ожиданиям человека. Мы также отобрали некоторые данные и дополнили их супервыравниванием для дальнейшего расширения возможностей модели. Этот подход дал определённый эффект, но нам потребовалось около пяти месяцев, с марта по конец июля этого года, чтобы добиться примерно двукратного улучшения производительности модели.
Это первая проблема, с которой столкнулась техническая архитектура «сквозной интерфейс + модель визуального языка VLM» после своего быстрого развития: чем больше времени проходит, тем меньше становится полезных данных и тем медленнее улучшается производительность модели.

Была также раскрыта фундаментальная проблема. Лан Сяньпэн сказал:
По сути, современному сквозному имитационному обучению не хватает навыков глубокого логического мышления. Это как обезьяна за рулём автомобиля. Дайте ей бананов, и она, возможно, поведёт себя так, как вы задумали, но сама не будет знать, почему. Она может подойти к вам на удар гонга или танцевать под звуки барабана, но сама не будет знать, почему.
Следовательно, сквозная архитектура не способна к глубокому мышлению. В лучшем случае, это реакция на стресс. То есть, при получении входных данных модель выдаёт выходной сигнал. В ней нет никакой глубокой логики.
Именно поэтому мы добавляем к сквозной большой модели визуальную языковую модель (VLM). VLM обладает более развитыми возможностями понимания и мышления, что позволяет принимать более взвешенные решения. Однако эта модель работает медленно и недостаточно тесно связана с сквозной большой моделью. В результате сквозная большая модель часто не понимает или не принимает решения, принятые VLM.
В это же время в прошлом году команда Ideal Assisted Driving заявила:
Существуют две тенденции будущего. Во-первых, масштаб моделей будет увеличиваться. Система 1 и Система 2 в настоящее время представляют собой две сквозные модели с VLM. Эти две модели могут быть объединены. В настоящее время они слабо связаны, но в будущем их связь может стать более тесной. Во-вторых, мы также можем извлечь уроки из текущей тенденции создания больших мультимодальных моделей. Эти модели движутся к изначальной мультимодальности, способной обрабатывать язык, речь, зрительное восприятие и данные лидара. Мы рассмотрим это в будущем.
Эта тенденция быстро стала реальностью.
Лан Сяньпэн также объяснил причины перехода от end-to-end + VLM к VLA:
Когда в прошлом году мы работали над сквозным проектом, мы постоянно размышляли над тем, достаточно ли сквозного проекта, и если нет, что еще нам нужно сделать.
Мы провели предварительные исследования VLA. Фактически, предварительные исследования VLA отражают наше понимание того, что искусственный интеллект не является имитационным обучением. Он должен обладать способностью мыслить и рассуждать, как человек. Другими словами, он должен быть способен решать задачи, с которыми никогда не сталкивался, или решать неизвестные ситуации. Это может быть связано с определённой способностью к сквозному обобщению, но этого недостаточно для того, чтобы говорить о наличии мышления.
Подобно обезьяне, он может делать что-то, что кажется вам невообразимым, но не всегда. Но люди — это другое дело. Люди способны расти и развиваться, поэтому мы должны развивать наш искусственный интеллект в соответствии с развитием человеческого интеллекта. Мы быстро перешли от сквозного решения к решению на основе VLA.
VLA (Vision-Language-Action) — это тренд мышления прошлого года и техническая архитектура, которая сегодня стала реальностью.
Хотя VLA и VLM отличаются всего одной буквой, их значения сильно различаются.
Под зрением в VLA понимается ввод различной сенсорной информации, включая навигационную информацию, которая позволяет модели понимать и воспринимать пространство.
Язык VLA относится к способности модели обобщать, переводить, сжимать и кодировать воспринимаемое пространственное понимание в языковое выражение, подобно человеку.
Действие VLA — это модель, генерирующая поведенческую стратегию на основе языка кодирования сцены для управления автомобилем.
Самое интуитивно понятное отличие заключается в том, что люди могут управлять автомобилем с помощью речи. Они могут управлять автомобилем с помощью речи, замедлять или ускорять его, поворачивать налево или направо. Это в основном связано с языковой составляющей. Подсказки, получаемые большой моделью человеческих команд, также являются подсказками внутри модели VLA, что эквивалентно связи между людьми и автомобилями.
Кроме того, устраняется барьер между зрением и поведением. Скорость и эффективность от ввода визуальной информации до вывода данных о поведении транспортного средства значительно увеличиваются, а проблемы медленного VLM и полного отсутствия понимания VLM решаются.
Более существенное отличие — это функция цепочки мыслей (Chain of Thought, CoT). Модель VLA имеет частоту вывода 10 Гц, что более чем в три раза выше, чем VLM. Она также обеспечивает более полное восприятие и понимание окружающей среды, что позволяет быстрее и рациональнее рассуждать и принимать решения.
Помимо мыслительных и коммуникативных способностей, VLA также обладает определенной памятью, способной запоминать предпочтения и привычки хозяина, а также довольно сильной способностью к самостоятельному обучению.

▲ Ideal i8 — первая модель, использующая технологию Ideal VLA
Идеальный помощник вождения «Ускоряя жизнь»
В реальном мире, если люди хотят стать опытными водителями, им сначала нужно записаться в автошколу и получить водительские права, а затем наклеить «наклейку стажера» и отправиться в путь, колеся по настоящим дорогам в течение нескольких лет.
То же самое относится и к предыдущему обучению вождению с помощью водителя, которое требует не только реальных данных вождения для обучения, но и большого количества дорожных испытаний в реальных условиях.
В некоторых романах талантливые участники могут стать мастерами боевых искусств с чрезвычайно высоким уровнем мастерства благодаря чтению, например, «Конфуцианский обладатель бессмертного меча» Се Сюань в «Песне юности» и Сюаньюань Цзинчэн в «Мечнике на снегу».
Однако в традиционных романах о боевых искусствах есть только персонажи, подобные Ван Юйяню из «Полубогов и полудьяволов», которые владеют классическими приемами боевых искусств, но не имеют реальных боевых навыков.

▲ Кадры из фильма «Ускоряя жизнь»
Конечно, есть и промежуточные ситуации: в фильме о гонках «Ускоренная жизнь» гонщик Чжан Чи, оказавшийся в затруднительном положении, постоянно воспроизводил в уме сложные условия трассы в районе Байинбулуке, мысленно проезжал по 20 раз в день, симулировал вождение более 36 000 раз за 5 лет, а вернувшись на настоящую трассу, стал чемпионом.
Виртуальное вождение, постоянное совершенствование и превосходство своих прошлых лучших результатов — вот «алгоритм».
Однако прежде чем Чжан Чи вернулся на трассу и вновь стал гонщиком-чемпионом, он уже неоднократно проявил себя на этой трассе и накопил большой практический опыт вождения.
Реальная машина и реальная дорога, накопление опыта, пока вы не поймете все дорожные условия этой трассы, это «данные».

Лан Сяньпэн сказал, что для разработки хорошей модели VLA необходимы четыре уровня возможностей: данные, алгоритмы, вычислительная мощность и инженерные возможности.
Ideal давно подчёркивает свой обилие данных, их качество, хорошую базу данных, а также точность маркировки и анализа данных. Что касается данных, Ideal также обладает новым навыком: созданием обучающих данных.

Модель мира используется для реконструкции сцены, а затем на основе реконструированных реальных данных генерируются аналогичные сцены. Например, модель мира идеально подходит для реконструкции сцены высокоскоростного ETC. В этом сценарии можно использовать не только исходные реальные условия, например, солнечную и сухую поверхность днём, но и такие сцены, как сильный снегопад днём со скользкой поверхностью и небольшой дождь ночью с плохой видимостью.
Идеальный алгоритм обучения для моделей VLA также тесно связан с генерируемыми данными. Лан Сяньпэн пояснил:
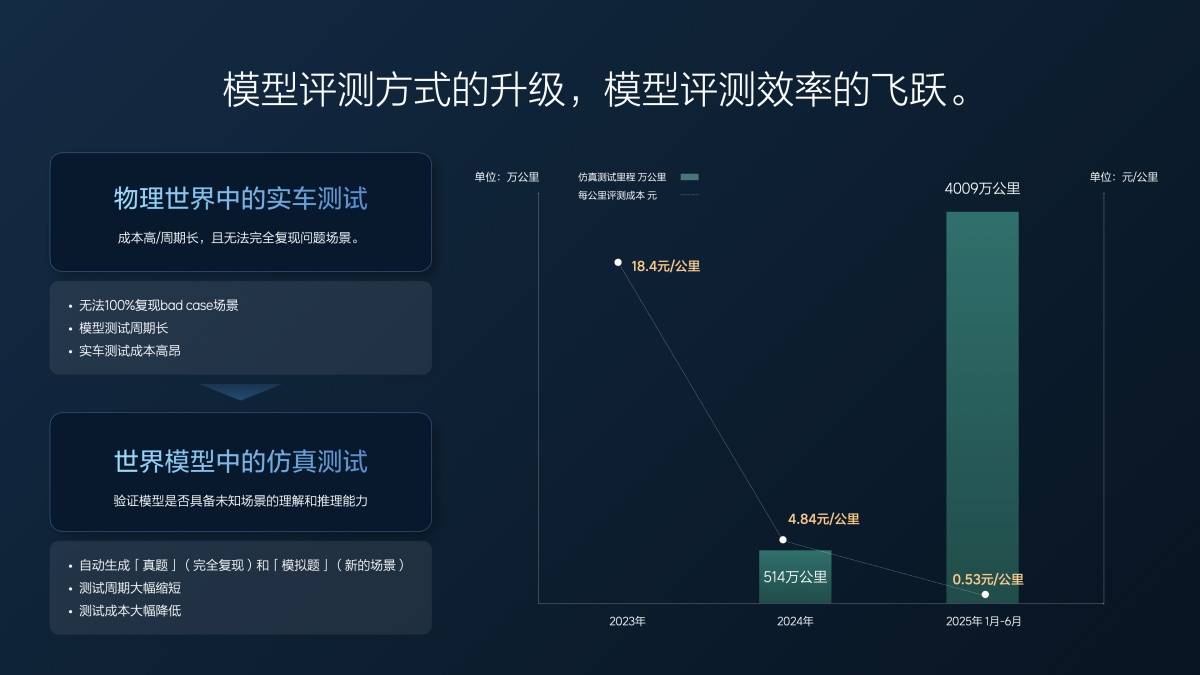
В 2023 году мы еще не достигли сквозного развития. Эффективный испытательный пробег реальных транспортных средств в год составляет около 1,57 миллиона километров, а стоимость одного километра — 18 юаней.
Когда мы начали работать над сквозными системами, часть работы уже была выполнена в рамках имитационного тестирования. В течение 2024 года мы проехали около 5 миллионов километров в ходе имитационного тестирования и более 1 миллиона километров в ходе испытаний на реальных автомобилях. Средняя стоимость снизилась до менее 5 юаней за километр, что по-прежнему составляло около 30 миллионов юаней. Однако, используя те же 30 миллионов юаней, мы смогли протестировать 6 миллионов километров.
За первые шесть месяцев этого года (с 1 января по 30 июня) мы проехали 40 миллионов километров, из которых всего 20 000 — на реальных автомобилях, охватывая базовые сценарии. Все наши испытания, включая супервыравнивание и текущие функции VLA, которые вы уже видели, проводятся с помощью моделирования. Стоимость составляет 0,5 цента за километр, что едва покрывает расходы на электроэнергию и сервер. Более того, качество испытаний высокое: все случаи и сценарии полностью воспроизведены и точны, что гарантирует точность результатов. Увеличенный пробег и повышение качества испытаний повысили эффективность НИОКР.
Многие сомневались, что мы не сможем построить VLA за полгода, и что мы даже не сможем всё это протестировать. На самом деле, мы провели много испытаний.
Помимо низкой стоимости, преимущество имитационного тестирования заключается в возможности идеального воспроизведения сцены. В реальных условиях сложно восстановить сцену на 100%. Для модели VLA даже малейшее отличие в воспроизведении сцены может привести к существенной разнице в характеристиках вождения.

В этом смысле идеальная форма обучения модели VLA чем-то напоминает модель из фильма «Ускоренная жизнь», где главный герой непрерывно проводит виртуальное обучение, основанное на реальном опыте вождения.
Конечно, обучение модели VLA также требует огромных вычислительных мощностей. Текущая общая вычислительная мощность Ideal составляет 13 эффлопс, из которых 3 эффлопс приходится на инференс, а 10 эффлопс — на обучение. В пересчёте на видеокарты это эквивалентно 20 000 графических процессоров NVIDIA H20 для обучения и 30 000 графических процессоров NVIDIA L20 для инференса.

Ключевые вопросы и ответы
В: Интеллектуальные системы помощи водителю представляют собой «невозможный треугольник» — эффективность, комфорт и безопасность, — которые взаимно ограничены и на данном этапе могут быть труднодостижимы одновременно. Какой показатель VLA в настоящее время является приоритетным для Ideal Auto? Вы только что упомянули MPI. Можно ли понять, что конечная цель Ideal Auto — повысить безопасность, чтобы эффективно снизить количество захватов?
Лан Сяньпэн: MPI — один из наших показателей. Другой — MPA, который отражает пробег до аварии. Владельцы идеальных автомобилей попадают в аварию примерно каждые 600 000 километров вождения, в то время как владельцы, использующие системы помощи водителю, попадают в аварию каждые 3,5–4 миллиона километров. Мы продолжим улучшать данные о пробеге. Наша цель — увеличить MPA в 10 раз по сравнению с человеческим вождением, то есть сделать его в 10 раз безопаснее, чем человек, и достичь уровня аварийности в 6 миллионов километров. Однако это возможно только после усовершенствования модели VLA.
Мы также проанализировали систему помощи водителю (MPI). Хотя некоторые факторы риска безопасности могут привести к перехвату управления водителем, другие факторы, такие как недостаточный комфорт при резком или резком торможении, также могут привести к перехвату управления водителем. Хотя риски безопасности возникают не всегда, пользователи могут всё равно неохотно использовать системы помощи водителю, если комфорт вождения не является оптимальным. Поскольку MPA измеряет не только безопасность, но и безопасность, мы сосредоточились на повышении комфорта вождения в системе помощи водителю (MPI). Испытайте функции помощи водителю в Ideal i8, и вы обнаружите значительное улучшение комфорта по сравнению с предыдущими версиями.
Эффективность приходит после безопасности и комфорта. Например, если мы пойдём по неверному пути, то, хотя это и повлечёт за собой потерю эффективности, мы не сможем немедленно исправить её, совершив опасные действия. Мы всё равно должны стремиться к эффективности, исходя из безопасности и комфорта.

В: В чём заключаются сложности модели VLA? Каковы требования к предприятиям? С какими трудностями столкнётся предприятие, если захочет внедрить модель VLA?
Лан Сяньпэн: Многие спрашивали, могут ли автопроизводители пропустить предыдущий алгоритм правил и сквозной этап, если они хотят разработать модель VLA. Я думаю, это невозможно.
Хотя данные, алгоритмы и другие аспекты VLA могут отличаться от предыдущих моделей, они по-прежнему опираются на существующую базу данных. Без полного замкнутого цикла данных, собранных с реальных автомобилей, нет данных для обучения модели мира. Ideal Auto смогла реализовать модель VLA, поскольку у нас есть 1,2 миллиарда точек данных. Только глубокое понимание этих данных позволит нам генерировать более качественные данные. Без этой базы данных, во-первых, невозможно обучить модель мира, а во-вторых, неясно, какие данные генерировать.
В то же время поддержка базовых учебных вычислительных мощностей и вычислительных мощностей вывода требует больших финансовых и технических возможностей, которые невозможно осуществить без предварительного накопления.
В: Фактический пробег автомобиля Ideal в этом году составляет 20 000 километров. На каком основании мы значительно сократили фактический пробег автомобиля?
Лан Сяньпэн: Мы считаем, что испытания на реальных автомобилях сопряжены с множеством сложностей. Одна из проблем — стоимость, но самая серьёзная заключается в невозможности полностью воспроизвести точный сценарий, в котором возникла проблема, при тестировании определённых ситуаций. Более того, испытания на реальных автомобилях неэффективны, поскольку водителям приходится управлять автомобилем, а затем повторно тестировать его. Наши текущие симуляции сопоставимы с испытаниями на реальных автомобилях. Более 90% испытаний текущей версии Super Edition и версии Ideal i8 VLA проводятся с помощью симуляции.
С прошлого года мы используем имитационное тестирование для проверки нашей сквозной версии. Мы уверены в её высокой надёжности и эффективности, поэтому заменили ею испытания на реальных автомобилях. Хотя некоторые тесты незаменимы, например, испытания на надёжность оборудования, мы обычно используем имитационное тестирование для тестирования производительности, и результаты превосходны.
С наступлением индустриальной эпохи подсечно-огневые процессы были заменены механизацией; с наступлением информационной эпохи Интернет заменил значительную часть работы. То же самое происходит и в эпоху автономного вождения. С наступлением сквозной эпохи мы перешли к использованию искусственного интеллекта для автономного вождения. От привлечения большого количества инженеров и тестировщиков алгоритмов к подходу, основанному на данных, мы улучшаем возможности автономного вождения посредством обработки данных, платформ данных и итерации алгоритмов. В эпоху крупномасштабных виртуализированных автоматизированных моделей (VLA) эффективность тестирования является ключевым фактором повышения возможностей. Для достижения быстрой итерации необходимо устранить факторы, препятствующие этому. Если по-прежнему требуется значительное участие реальных транспортных средств и ручное вмешательство, скорость будет снижаться. Речь не обязательно идет о замене испытаний реальных транспортных средств; скорее, технология и подход по своей сути требуют использования имитационного тестирования. Без этого мы не практикуем обучение с подкреплением и не разрабатываем модели VLA.
В: VLA на самом деле не подрывает end-to-end + VLM, поэтому можно ли считать, что VLA — это инновация, которая, как правило, фокусируется на инженерных возможностях?
Чжань Кунь (старший эксперт по алгоритмам, автономное вождение, Ideal Auto): VLA — это больше, чем просто инженерная инновация. Если вас интересует воплощённый интеллект, вы заметите, что эта тенденция обусловлена применением больших моделей к физическому миру. По сути, это предполагает разработку алгоритма VLA. Наша модель VLA направлена на применение идей и подходов воплощённого интеллекта в области автономного вождения. Мы первыми предложили и внедрили её на практике. VLA также является сквозным, поскольку его суть заключается в вводе сцены и выводе траектории, концепция, схожая с VLA. Однако алгоритмическая инновация требует дополнительного мышления. Сквозное мышление можно понимать как VA без языка. Язык соответствует мышлению и пониманию. Мы включили этот компонент в VLA, унифицируя парадигму робототехники и сделав автономное вождение отдельной категорией робототехники. Это представляет собой алгоритмическую, а не только инженерную инновацию.
Серьёзной проблемой для автономного вождения являются инженерные инновации. VLA — это большая модель, и её развёртывание на периферийных вычислительных мощностях — задача чрезвычайно сложная. Многие команды не считают VLA плохой идеей, а скорее считают, что развёртывание VLA — сложная задача. Реализация этой идеи на практике невероятно сложна, особенно когда периферийным чипам не хватает вычислительной мощности. Поэтому мы должны развернуть её на высокопроизводительных чипах. Речь идёт не только об инженерных инновациях, но и о значительной оптимизации процесса развёртывания для достижения успеха.
В: Будет ли происходить обрезка или дистилляция модели при развёртывании больших моделей VLA на борту? Как найти баланс между эффективностью вывода и производительностью модели?
Чжань Кунь: Мы тщательно сбалансировали эффективность и дистилляцию при развёртывании. Наша базовая модель — это уникальная в отрасли модель MoE (Mixture of Experts) собственной разработки 8×0,4B. После глубокого анализа чипов NVIDIA мы пришли к выводу, что эта архитектура идеально подходит. Она обеспечивает высокую скорость вывода и большую ёмкость моделей, что позволяет ей работать с большими моделями с разнообразными сценариями и возможностями. Это был наш архитектурный выбор.
Кроме того, мы разработали крупную модель. Изначально мы обучили облачную модель 32B, содержащую огромный объём знаний и возможностей для вождения. Мы преобразовали её процессы мышления и рассуждения в модель MoE 3.2B и использовали технологию Diffusion в сочетании с Vision and Action (моделью диффузии, которая может генерировать изображения, видео, аудио, траектории движения и другие данные). В частности, в идеальном сценарии VLA Diffusion используется для генерации траекторий движения.
Используя этот подход, мы реализовали множество оптимизаций. В частности, мы также реализовали инженерные оптимизации для Diffusion. Вместо использования стандартного Diffusion мы реализовали сжатие вывода, которое можно считать своего рода дистилляцией. Раньше Diffusion мог потребовать 10 шагов вывода, но при использовании Flow Matching достаточно всего двух. Это сжатие — основная причина, по которой мы смогли внедрить VLA.

В: Является ли VLA достаточно хорошим решением? Сколько времени потребуется, чтобы достичь так называемого «момента GPT»?
Чжань Кунь: Когда ранее говорилось, что мультимодальная модель не достигла момента GPT, возможно, имелось в виду физический ИИ, такой как VLA, а не VLM. Фактически, VLM теперь полностью соответствует весьма инновационному стандарту «момента GPT». Если же говорить о физическом ИИ, то текущий VLA, особенно в области робототехники и воплощенного интеллекта, возможно, не достиг стандарта «момента GPT», поскольку не обладает такими хорошими возможностями обобщения.
Однако в области автономного вождения VLA фактически решает относительно унифицированную парадигму вождения, и таким образом есть шанс достичь «момента GPT». Мы также полностью признаём, что текущая версия VLA — это первая версия VLA, запущенная в массовое производство, поэтому некоторые дефекты, безусловно, будут.
Эта масштабная попытка заключается в использовании VLA для исследования нового пути. Она включает в себя множество областей для изучения и множество точек исследования, которые необходимо реализовать. Это не означает, что если мы не сможем достичь «момента GPT», нам не следует переходить к массовому производству. Существует множество деталей, включая нашу оценку и моделирование, которые помогут проверить возможность массового производства и способность обеспечить пользователям «более качественный, комфортный и безопасный» опыт. Если будут достигнуты эти три пункта, мы сможем предоставить пользователям более качественную доставку.
«Моменты GPT» в большей степени связаны с высокой степенью универсальности и обобщения. В этом процессе, по мере распространения автономного вождения на космических роботов или другие области применения, мы можем развить более сильные возможности обобщения или более комплексные возможности координации. После внедрения мы постепенно перейдем к моментам ChatGPT по мере того, как «пользовательские данные будут итерироваться, сценарии станут более насыщенными, мышление — более логичным, а голосовое взаимодействие — более частым».
Как сказал доктор Лан Бо (доктор Лан Сяньпэн), если к следующему году мы достигнем показателя в 1000 MPI, у пользователей может возникнуть ощущение, что мы действительно достигли «момента GPT» для VLA.
#Приглашаем вас следить за официальным публичным аккаунтом WeChat проекта iFaner: iFaner (WeChat ID: ifanr), где в ближайшее время вам будет представлен еще более интересный контент.
iFanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo