Антропический подход позволил «концентрировать» крупнейшую базу знаний человечества.

В начале 2024 года на каком-то складе в Соединенных Штатах рабочие занимались чем-то довольно странным: по одной загружали книги в машину, отрезали корешки, сканировали их, а затем отправляли оставшуюся бумагу на переработку.
Эти книги были только что куплены, некоторые даже совершенно новые. Никто их читать не будет; их единственное предназначение — быть уничтоженными.
Заказ на это разместила компания Anthropic, специализирующаяся на искусственном интеллекте.

В их внутренних документах проект носил кодовое название «Проект Панама». В одном из плановых документов прямо говорилось: «Это наш план по разрушительному сканированию всех книг в мире, и мы не хотим, чтобы внешний мир знал, что мы это делаем».
В конце концов, люди об этом узнали.
В прошлом году федеральный судья рассекретил пакет документов, связанных с иском о нарушении авторских прав, общим объемом более 4000 страниц. Внешний мир увидел не просто секреты одной компании, а истинное лицо всей индустрии искусственного интеллекта в ее войне за данные.
Физические книги «съедены» крупными моделями
Почему эти передовые технологические гиганты так примитивно и даже жестоко обращаются с печатными книгами? Ответ кроется в чрезвычайной потребности искусственного интеллекта в высококачественных данных.
Компания Anthropic рано осознала, что одного лишь онлайн-контента недостаточно для обучения моделей искусственного интеллекта.
Как сообщает The Washington Post, один из соучредителей Anthropic в документе от января 2023 года написал, что обучение моделей с помощью книг может научить ИИ «писать лучше», а не просто имитировать непоследовательный язык в интернете.
Книга прошла тщательную редактуру и корректуру, и ее структура содержания понятна. Это высококачественный корпус, который сложно заменить текстами из интернета.
Сама логика несложна для понимания, но проблема в том, что если ценность книг признана, почему бы за них не платить? Причина в том, что переговоры о лицензировании с издателями и авторами по отдельности отнимают много времени, сил и средств. Поэтому компания Anthropic запустила «Панамский проект». Заявление «Мы не хотим, чтобы об этом знал внешний мир» указывает на то, что компания также понимает несостоятельность этого аргумента.
Еще до запуска «Панамского проекта» компания Anthropic пыталась приобретать книги другим способом.

Судебные документы показывают, что соучредитель компании Бен Манн в течение 11 дней в июне 2021 года скачал большое количество романов и научно-популярных книг с веб-сайта LibGen. LibGen — это «теневая библиотека», большая часть ресурсов которой, предположительно, нарушает авторские права. Скриншоты браузера, приложенные к документам, показывают, что для этих загрузок он использовал программное обеспечение для обмена файлами.
Год спустя, в июле 2022 года, был запущен ещё один веб-сайт, Pirate Library Mirror, открыто заявляющий, что он «намеренно нарушает законы об авторском праве в большинстве стран». Манн отправил ссылку на этот сайт другим сотрудникам Anthropic, прокомментировав: «Идеальное время!!!»
За этим восклицательным знаком скрывается истинное отношение руководителя компании к пиратскому сайту, который открыто признает нарушение закона.
Компания Anthropic позже заявила, что никогда не использовала эти данные для обучения своей официально выпущенной коммерческой модели. Однако это объяснение несколько неубедительно. Они скачали и сохранили их, но «не использовали в официальной модели». Где именно проходит эта грань, вероятно, неясно даже самой компании Anthropic.
Для «Панамского проекта» компания Anthropic специально наняла Тома Тёрви в качестве руководителя работы. Ранее Тёрви участвовал в создании проекта Google Books, который также вызвал многолетние споры об авторских правах из-за масштабного сканирования книг. Трудно сказать, что выбор Тёрви в качестве руководителя этого проекта был случайным.
В конечном итоге, компания Anthropic в основном полагалась на двух книгопродавцов для оптовых поставок:
Американская сеть магазинов подержанных книг Better World Books и британская World of Books часто закупают десятки тысяч книг за раз. Внутренние документы также показывают, что сотрудники обсуждали возможность обращения в Нью-Йоркскую публичную библиотеку и даже упоминали о поиске помощи в давно недофинансируемой новой библиотеке.
После завершения закупок весь процесс сканирования напоминал промышленную сборочную линию.

Поставщик использовал гидравлический резак для аккуратной обрезки корешков книг, после чего отделившиеся страницы подавались в высокоскоростной промышленный сканер. После сканирования оставшаяся бумага передавалась в компанию по переработке. Один из поставщиков услуг сканирования, подавших заявку, указал в своем предложении, что компания Anthropic надеется завершить оцифровку от 500 000 до 2 миллионов книг в течение шести месяцев.
Заместитель главного юрисконсульта компании Anthropic, Апарна Шридхар, ответила, что суд постановил, что обучение ИИ носит «трансформационный характер», и что решение Anthropic о заключении мирового соглашения проблематично «с точки зрения того, как были получены некоторые материалы, а не того, можем ли мы использовать эти материалы».
Этот аргумент может быть юридически обоснованным, но он также показывает одну вещь: компания никогда не считала, что совершила что-то противоправное, а лишь то, что некоторые из ее методов были недостаточно чистыми.
Они будут использовать ваши учебники для обучения, а затем украдут вашу работу.
То же самое происходит и с другими компаниями, а некоторые детали еще более драматичны.
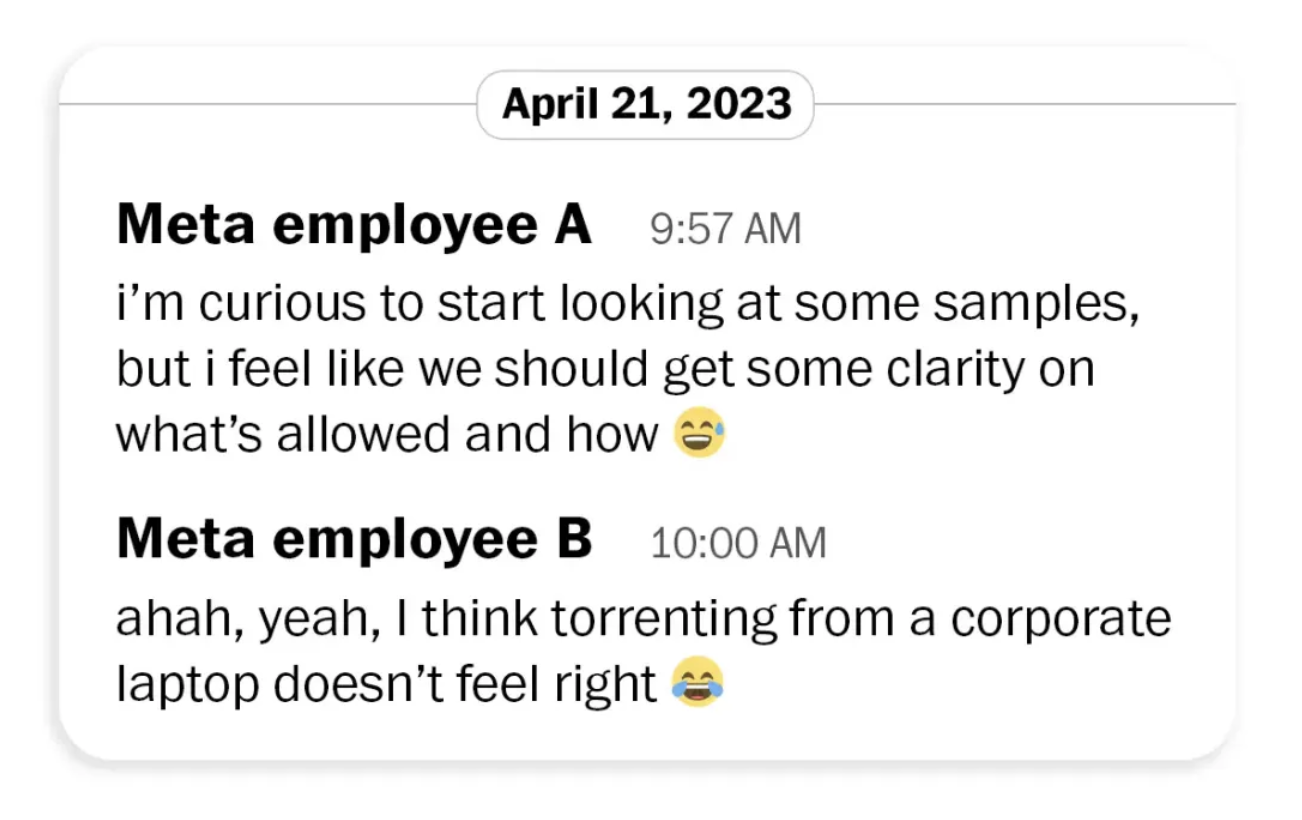
В судебных документах против Meta указано, что в 2023 году один из сотрудников написал: «Мне кажется неправильным использовать корпоративный ноутбук для скачивания торрентов». Позже он специально поднял этот вопрос перед юридической командой, заявив, что использование торрент-сайтов может означать распространение пиратских копий другим лицам, «что может быть незаконно».
Но эти опасения в конечном итоге ничего не изменили.
Внутреннее электронное письмо от декабря 2023 года показало, что использование LibGen было одобрено после того, как об этом «сообщили MZ», имея в виду генерального директора Марка Цукерберга. В письме также откровенно говорилось о рисках, о которых они знали: «Если в СМИ появятся сообщения о том, что мы использовали наборы данных, которые, как известно, были пиратскими, это может ослабить нашу переговорную позицию по вопросам регулирования».
Другими словами, они понимали, что поступают неправильно; они просто взвешивали риск быть пойманными. Чтобы снизить этот риск, сотрудники намеренно арендовали серверы Amazon для загрузки торрентов вместо собственных серверов Meta, чтобы избежать отслеживания их связи с Meta.
И OpenAI, и Microsoft сталкиваются с обвинениями в нарушении авторских прав со стороны авторов книг. OpenAI даже признала, что скачала LibGen, но заявила, что удалила файлы до выхода ChatGPT.
Конфликт в сфере авторских прав между компаниями, занимающимися искусственным интеллектом, и его создателями начался не с Anthropic.
В начале 2000-х годов Google провел масштабное сканирование библиотечных фондов, что также стало причиной десятилетнего судебного разбирательства. В конечном итоге суд постановил, что действия Google представляют собой «добросовестное использование», поскольку компания предоставила лишь выдержки, призванные помочь читателям найти книги, а не заменить их.
В то время этот вердикт казался разумным, но двадцать лет спустя он стал прикрытием для всей индустрии искусственного интеллекта.
Google Books — это инструмент индексирования, в то время как генеративный ИИ напрямую обрабатывает содержание книг и выдает текст, иногда напрямую конкурируя с авторами. Природа изменилась, но используемая правовая логика осталась прежней, что само по себе заслуживает внимания.

В июне прошлого года федеральный судья Уильям Алсуп постановил, что использование книг компанией Anthropic для обучения ИИ является законным, сравнив этот процесс с тем, как учитель «обучает учеников писать хорошие эссе». Хотя эта аналогия звучит мягко, в реальности учителя не обучают миллионы учеников одновременно и не зарабатывают на этом миллиарды долларов.
В конечном итоге компания Anthropic решила выплатить рекордную сумму в 1,5 миллиарда долларов в истории судебных разбирательств по вопросам авторского права на искусственный интеллект. Однако при более внимательном рассмотрении финансовый результат оказался не таким уж плохим. Согласно законодательству США об авторском праве, установленный законом предельный размер компенсации за каждое произведение составляет 150 000 долларов, тогда как в данном случае это примерно 3000 долларов за книгу, что составляет всего 2% от этого предела.
Вознаграждение было разделено поровну между автором и издателем, но такая договоренность вызвала споры в сообществе создателей контента.
Многие авторы считают, что издатели не сделали все возможное, чтобы защитить их произведения от неправомерного использования ИИ, однако они получили лишь половину компенсации. Что еще более важно, соглашение об урегулировании не обязывает компанию Anthropic признавать какие-либо противоправные действия, и вывод суда о том, что «обучение с помощью ИИ представляет собой добросовестное использование», остается в силе.

Другими словами, сделка, заключенная компанией Anthropic за 1,5 миллиарда долларов, была не просто урегулированием спора, но и подтверждением того, что мы можем продолжать это делать. Некоторые аналитики отмечают, что с установленным прецедентом нарушение авторских прав перестало быть «красной линией» для компаний, занимающихся ИИ, и стало скорее «платой», которую можно заранее учесть в затратах.
Для многих писателей это означает гораздо больше, чем просто чек. Средний годовой доход американского автора составляет около 20 000 долларов, в то время как компании, занимающиеся искусственным интеллектом и оцениваемые в сотни миллиардов долларов, широко используют их работы без разрешения, а получаемое ими впоследствии вознаграждение значительно ниже установленного законом предела.
Ещё более тревожным является то, что ИИ массово производит текстовый контент. Этот приток недорогого текста на рынок ещё больше затрудняет зарабатывание на жизнь писательством. ИИ обучается на книгах, написанных людьми, но контент, создаваемый ИИ, вытесняет возможности для людей продолжать писать книги, создавая порочный круг.
Сторонники этой идеи придерживаются своей логики: ИИ не хранит содержимое книг, а извлекает лингвистические закономерности, что больше похоже на то, как человек формирует собственное выражение после длительного чтения. Эта аналогия не совсем лишена смысла, но она упускает из виду важное различие:
Человек читает одну книгу, но не миллион; в то время как искусственный интеллект обрабатывает десятилетия человеческих трудов за несколько месяцев, а затем бесконечно воспроизводит и выдает их с чрезвычайно низкими предельными издержками. Масштаб меняет природу, поэтому приравнивать эти две вещи неразумно.
Миллионы книг были разрезаны, отсканированы и переработаны, что в конечном итоге привело к мировому соглашению. Эти книги давно потеряны. Тем временем искусственный интеллект продолжает писать, и с постоянно возрастающей скоростью. Возможно, это самый тревожный аспект всего этого дела: никто по-настоящему не понес наказания за уничтожение и бесконтрольное использование книг для обучения ИИ.
Адрес для справки прилагается:
https://www.washingtonpost.com/technology/2026/01/27/anthropic-ai-scan-destroy-books/
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (идентификатор WeChat: ifanr), где вы сможете в кратчайшие сроки увидеть еще больше интересного контента.
ifanr | Оригинальная ссылка · Посмотреть комментарии · Sina Weibo