Скандал вокруг «дистилляции», парализовавший компанию Anthropic, вызвал отрезвляющее замечание от ведущего американского эксперта по ИИ: успех Китая в области ИИ не будет зависеть от использования обходных путей.

Вчера издание Anthropic раскритиковало три китайские лаборатории искусственного интеллекта — DeepSeek, Dark Side of the Moon и MiniMax — за «упрощение» модели Клода, что вызвало бурю негодования в интернете.
В связи с этим инцидентом Натан Ламберт, один из самых известных исследователей в области RLHF (обучение с подкреплением на основе обратной связи от человека) и автор книги «RLHF», отметил, что дело не так серьезно, как кажется, но и не так просто, как выглядит.
Он считает, что китайские компании, занимающиеся искусственным интеллектом, обладают превосходной инфраструктурой, внесли множество инноваций и решают различные технические задачи, но достигли этих результатов не «путем обходных путей».
Прежде чем обсуждать процесс дистилляции, давайте разберемся, почему к словам Ламберта стоит прислушаться.
Натан Ламберт — научный сотрудник Института исследований искусственного интеллекта имени Аллена. Он получил докторскую степень в Калифорнийском университете в Беркли, где учился у Питера Аббила, известного учёного в области робототехники. Хотя он не является изобретателем технологии RLHF, его книга с открытым исходным кодом *RLHF* в настоящее время является одним из стандартных справочных материалов для специалистов по искусственному интеллекту, позволяющих понять процесс обучения больших моделей.
В отличие от многочисленных инфлюенсеров в сфере ИИ, он — человек, который действительно обучил большие модели.
В тот же день, когда была опубликована статья в блоге Anthropic, Ламберт выпустил подробную аналитическую статью под названием «Насколько важна дистилляция для крупной модели Китая?». Его основные аргументы значительно отличались от интерпретации основных СМИ и были более глубокими и всесторонними, чем те, которые высказывает среднестатистический пользователь интернета.
Что такое дистилляция, и что об этом говорил Антропик?
Для начала давайте рассмотрим суть обвинения Anthropic: «дистиллировка».
Речь идёт о предоставлении слабой модели возможности учиться на основе результатов работы сильной модели, тем самым быстро приобретая аналогичные возможности.
Компания Anthropic утверждает, что три компании использовали около 24 000 фейковых аккаунтов для генерации более 16 миллионов диалогов с Клодом, нарушая условия предоставления услуг и региональные ограничения доступа, для обучения своих моделей.
В блоге также содержалось предупреждение о безопасности: незаконно созданные модели могут не обладать теми же мерами безопасности, что и исходная модель, и последствия непредсказуемы, если они используются для кибератак, разработки биологического оружия или крупномасштабного наблюдения.
Компания Anthropic называет эту инфраструктуру «кластером Hydra» — распределенной сетью из десятков тысяч учетных записей, трафик которой одновременно распределяется между собственным API Anthropic и множеством сторонних платформ агрегации API.
В самых крайних случаях прокси-сеть одновременно управляет более чем 20 000 поддельных учетных записей, смешивая обработанный трафик с обычными потоками запросов пользователей, чтобы обойти алгоритмы обнаружения. В таких сетях нет единой точки отказа; если одна учетная запись заблокирована, другая немедленно заменяется.
Зарубежные СМИ быстро отреагировали, повторив риторику Anthropic. Однако эта логика повествования вскоре обернулась против самих компаний: в конце концов, «дистилляция» — это то, что американские компании, занимающиеся ИИ, также используют во время обучения, и сама Anthropic применяла аналогичные методы.
И еще: антропология "концентрировала" крупнейшую базу знаний человечества.
Однако Ламберт был более рассудительным, полагая, что эти три китайские лаборатории искусственного интеллекта следует сначала изучить по отдельности.
Ламберт отмечает, что сопоставление трех компаний в одном посте в блоге, проведенное Anthropic, скрывает важнейшее различие: они занимаются совершенно разными вещами, имеют совершенно разные масштабы и разные мотивы.
Согласно обвинениям Anthropic, DeepSeek выполняет наименьшее количество дистилляций — всего 150 000, — но его методы более точны. Вместо прямого сбора ответов, утверждает Anthropic, DeepSeek массово производит обучающие данные в виде цепочек рассуждений.
Важно не то, «к каким выводам вы пришли», а сам процесс достижения этих выводов.
Но что такое масштаб в 150 000 раз? Ламберт считает, что такое количество данных оказывает незначительное влияние на предполагаемую модель V4 DeepSeek или на общее обучение любой модели. «Это скорее похоже на небольшой внутренний эксперимент, проводимый командой, и, скорее всего, даже человек, отвечающий за обучение, об этом не знает».

Масштаб проекта Moonlight's Darkness отнюдь не «незначительный»: 3,4 миллиона взаимодействий, ориентированных на такие области, как логическое мышление агентов, вызовы инструментов, анализ кода и данных, разработка приложений для компьютеров и компьютерное зрение — большинство из которых являются наиболее популярными комбинациями возможностей Claude среди корпоративных клиентов в последнее время.
Компания Anthropic отмечает, что MiniMax имеет самый высокий трафик среди трех платформ, насчитывающий приблизительно 13 миллионов посещений, и его целевая аудитория — это прокси-программирование, вызовы инструментов и сложная оркестрация задач.
Суммарное количество токенов Moonlight и MiniMax составляет приблизительно 16,5 миллионов раз. Исходя из среднего количества токенов за один разговор, общее количество оценивается от 150 до 400 миллиардов токенов, что соответствует стоимости токенов в несколько сотен или десятки миллионов долларов США.
Однако проблема заключается в том, что сосредоточение внимания исключительно на процессе дистилляции является проблематичным.
Где находится предельный уровень процесса дистилляции?
Именно это Ламберт и хотел сказать, и это самая недооцененная часть всего происходящего.
Передача результатов работы сильной модели слабой модели, позволяющая слабой модели быстро приобрести аналогичные возможности — сама эта логика верна, и Ламберт этого не отрицает. Однако он указывает на проблему, которую никто четко не определил: потолок дистилляции зависит от типа необходимых возможностей.
Как эксперт в области RLHF, Ламберт считает, что современное обучение моделей в значительной степени опирается на обучение с подкреплением (RL). Однако RL и дистилляция — это принципиально разные вещи:
Дистилляция — это имитация, обучение на основе результатов работы сильной модели и копирование её «формы ответа»; обучение с подкреплением — это исследование, в ходе которого модель должна самостоятельно проводить обширные рассуждения, генерировать собственные данные, многократно повторять ошибки и совершенствовать свои возможности методом проб и ошибок.
Иными словами, по-настоящему мощной модели никогда не нужен просто правильный ответ, а часто необходимо самостоятельно найти путь решения. Этого нельзя добиться, просто анализируя выходные данные API других разработчиков.

В качестве примера можно привести собственную попытку DeepSeek по дистилляции: небольшая модель DeepSeek-R1-Distill-Qwen 1.5B, полученная путем дистилляции собственной модели R1 на основе соседней модели Qianwen, превзошла модель o1-preview от OpenAI в математическом конкурсе AIME24, используя всего 7000 выборок и имея чрезвычайно низкую вычислительную стоимость.
Однако ключевой момент заключается в том, что это улучшение в значительной степени зависит от результатов обучения с подкреплением, а не от самого процесса дистилляции.
Другими словами, дистилляция может помочь вам быстрее "разогреться", но для достижения истинного высшего уровня вам все равно придется полагаться на самостоятельный запуск RL.
Различия в распределении данных между различными моделями.
Ламберт также указал на техническую проблему, о которой редко упоминают посторонние: между различными моделями существуют незначительные различия в распределении данных.
Прямая передача результатов работы Клода в модель другой архитектуры не всегда эффективна и иногда может даже вызывать помехи. Различия во внутренних пространствах представления двух моделей могут привести к тому, что ответ «учителя» вызовет неожиданные искажения в ответе «ученика».
Это означает, что дистилляцию невозможно использовать «в неизменном виде», а для достижения подлинной эффективности требуется значительная инженерная работа. Это само по себе является темой для исследований.
Именно поэтому Ламберт рассматривает предполагаемый «переработку» данных, предложенный компанией Anthropic, как инновационный подход, который можно понимать как попытку решить данную исследовательскую задачу.

Главная особенность фильма «Антропик» — это именно то, что сложнее всего описать словами.
Все три компании, упомянутые Anthropic, сосредоточены на одной и той же области: поведенческие аспекты деятельности субъектов, включая способность ИИ автономно планировать, запускать инструменты и разбивать сложные задачи на этапы для пошагового выполнения.
В настоящее время это наиболее заметное направление деятельности Клода, и именно эту область Anthropic меньше всего хочет копировать.
Однако Ламберт пришел к выводу, что именно эти способности труднее всего получить путем дистилляции.
Как уже упоминалось ранее, сила мощного ИИ-агента заключается не в знании или обучении правильному ответу, а в «способности автономно искать решения в незнакомых ситуациях», что можно понимать как способность достигать самых современных результатов (SOTA) с использованием 0-кратного или малократного обучения.
Ценность, создаваемая в этом процессе, отражается в траектории рассуждений, которую сложно изучить путем обобщения — по крайней мере, пока.
Разрыв между DeepSeek-R1-Distill (модель дистилляции) и DeepSeek-R1 (объект дистилляции) является наиболее наглядным примером аргумента Ламберта.
Первый метод хорошо справляется с задачами, требующими структурированного математического мышления; однако разница между ними реальна в сложных задачах-заменителях, требующих автономного исследования и динамического программирования.

Почему организация Anthropic выступила с заявлением именно сейчас?
Ламберт высказал мнение, которое, возможно, разделяют многие: публичное упоминание компанией Anthropic китайских компаний, занимающихся искусственным интеллектом, на этот раз не было в первую очередь мотивировано «технической защитой».
Всего за несколько дней до публикации этой статьи в блоге Anthropic Министерство обороны США пригрозило компании сотрудничеством в виде «неограниченного доступа», в противном случае ей грозят невыгодные условия, такие как объявление ее «угрозой для цепочки поставок», что означало бы исключение из списка поставщиков оборонного/государственного сектора.
Компания Anthropic оказалась в затруднительном положении: она хочет сохранить свою безопасную и гуманную модель ведения бизнеса, а также корпоративный имидж, но при этом не хочет упустить крупный контракт с правительством США.
Ламберт указывает на фундаментальное противоречие: американские академические круги и разработчики моделей с открытым исходным кодом также занимаются дистилляцией, однако крупные компании, включая Anthropic, не предприняли никаких существенных действий против них. Утверждать, что это происходит исключительно потому, что другая сторона — китайская компания, кажется чрезмерно геополитическим подходом.
В результате, сообщение в блоге Anthropic было не столько отчетом о крупном событии, связанном с техническим риском, сколько «клятвой верности».

Двойные стандарты
Позиция компании Anthropic по этому вопросу имеет ряд неизбежных предпосылок.
Как упоминалось во вчерашней статье APPSO: антропогенное «обобщение» позволило создать самую обширную базу знаний в истории человечества.
В начале 2024 года на складе в США рабочие загружали новые книги в машины, отрезали корешки, сканировали их, а затем отправляли бумагу на переработку. Эта задача была поручена компании Anthropic, имеющей внутреннее кодовое название «Панама», целью которой было уничтожение всех книг в мире путем сканирования — Anthropic не хотела, чтобы внешний мир узнал об этом.
В 2021 году соучредитель Anthropic Бен Манн за 11 дней скачал большое количество книг, нарушающих авторские права, с пиратского сайта LibGen; в следующем году заработал другой сайт, Pirate Library Mirror, который открыто заявлял, что «намеренно нарушает законы об авторском праве в большинстве стран». Манн отправил ссылку коллеге и прокомментировал: «Идеальное время!!!»
В последующих судебных процессах по защите авторских прав на книги компания Anthropic была вынуждена выплатить компенсацию в размере 1,5 миллиарда долларов, что составляет приблизительно 3000 долларов за каждую книгу.
Исследователи из Стэнфорда и Йеля обнаружили, что модель Claude 3.7 Sonnet может воспроизводить защищенные авторским правом произведения, такие как «Гарри Поттер», с точностью до 95,8% при определенных условиях, практически слово в слово. Это не только противоречит давнему утверждению Anthropic о том, что «модель просто изучает правила языка», но и делает необоснованными обвинения компании в «дистилляции» в адрес кого-либо.
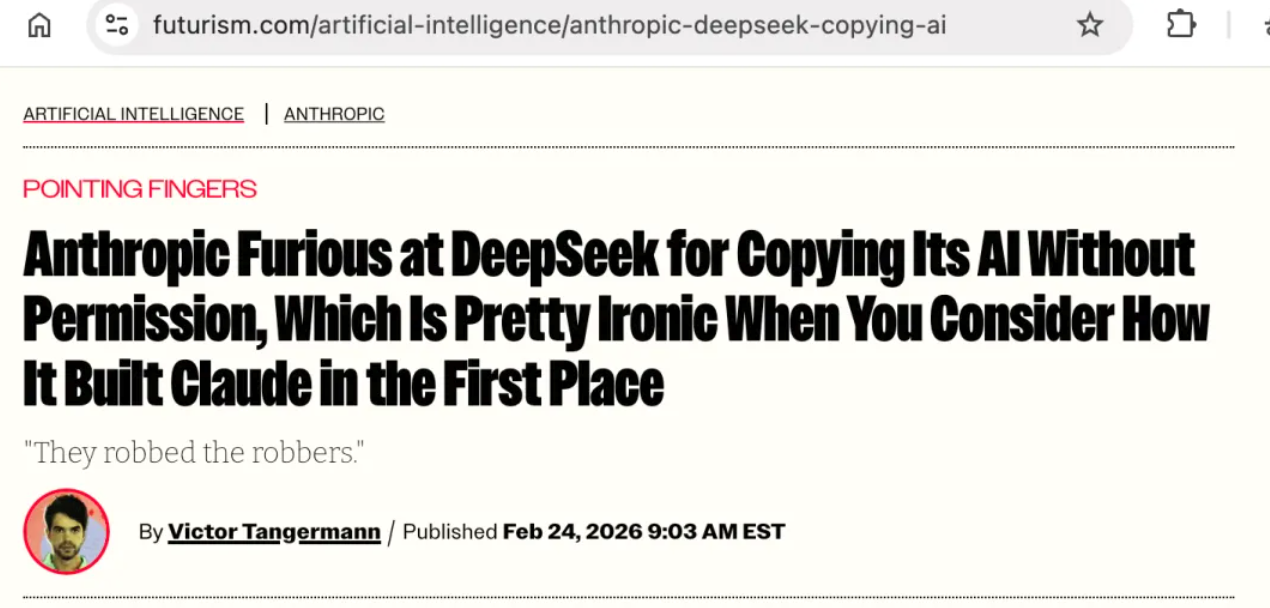
Заголовок Futurism предельно ясен: «Anthropic возмущен несанкционированным копированием ИИ компанией DeepSeek — что весьма иронично, учитывая, как она создала Клода».
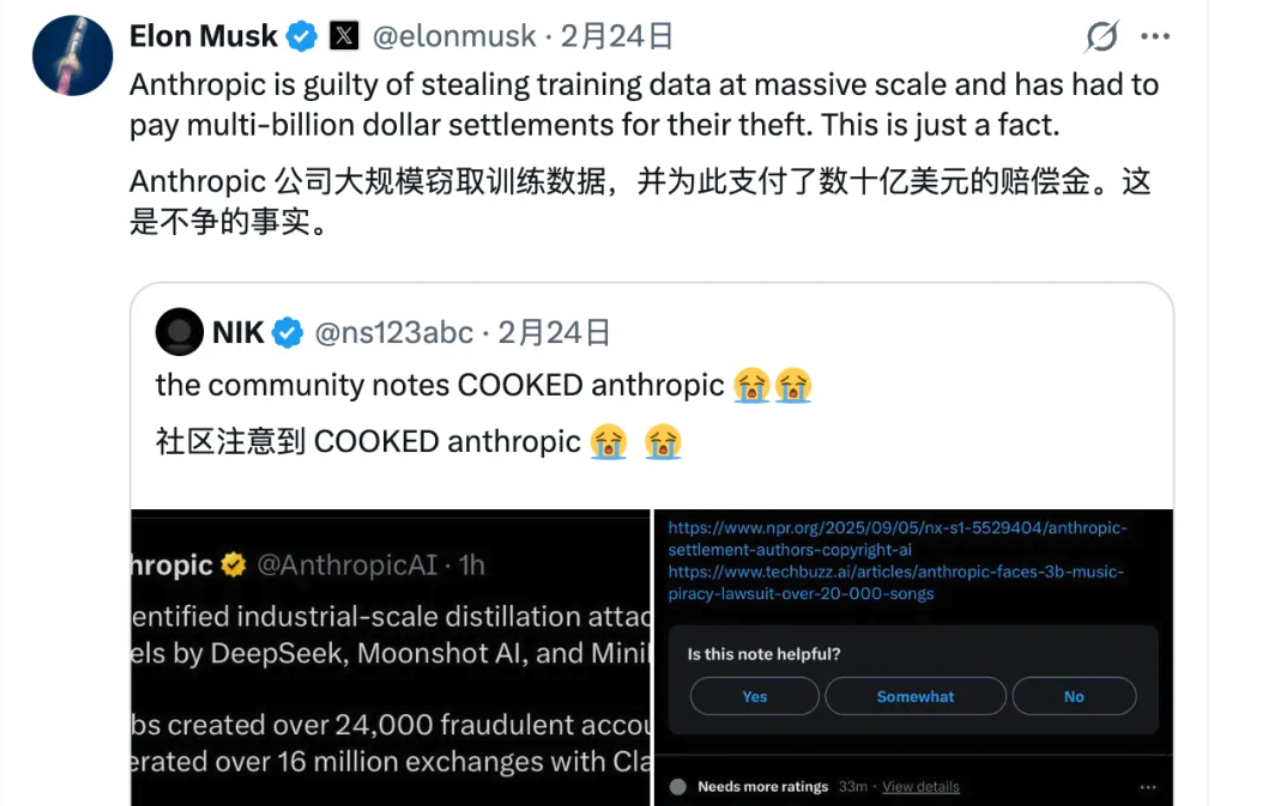
Своими комментариями по поводу X Маск подлил масла в огонь: «Компания Anthropic в огромных масштабах украла обучающие данные и выплатила миллиарды долларов в качестве компенсаций. Это факт».
Контраргумент еще более убедителен: Anthropic взяла все, что было взято из этих книг, не платя никаких комиссий за использование, и затем использовала это в коммерческих целях (и Claude, и API Anthropic — платные сервисы); в то время как с точки зрения бизнеса компания, которая создала Claude, по крайней мере, заплатила за это…
Конечно, с юридической точки зрения эти два вопроса совершенно различны по своей природе. Но в любом случае, Anthropic по-прежнему выглядит как лицемерный пример двойных стандартов.
«Эпоха после дистилляции»
В заключение позвольте мне еще раз подчеркнуть: дистилляция полезна, но не настолько, как вы можете себе представить.
150 000 сканирований DeepSeek — это ничтожно мало по любым разумным меркам. Moonshot и MiniMax вместе имеют 16,5 миллионов сканирований, что является совершенно другим вопросом с точки зрения масштаба, но насколько реальный потенциал они смогут реализовать, зависит от того, смогут ли они решить техническую проблему «как эффективно использовать эти данные».
Учитывая различия в распределении данных, архитектуре моделей и тот факт, что приобретение навыков агента в значительной степени зависит от обучения с подкреплением, процесс дистилляции никогда не бывает таким простым, как «просто возьми и используй».
Ламберт все же отдал должное компании Anthropic: «Быстрая итерация в сочетании с высококачественными данными может привести к очень большим результатам, и вполне возможно, что модель, разработанная учеником, превзойдет модель, разработанную учителем».

Однако он также ясно указал, что настоящие инновации основаны на обучении с подкреплением, а не на дистилляции. Судя по опубликованным работам DeepSeek, Moonlight и MiniMax, у всех них достаточно развитая инфраструктура и отличные специалисты, и они отнюдь не являются «небольшими мастерскими», пытающимися обогнать других, полагаясь на хитрые уловки.
Дистилляция может помочь вам быстрее начать, но на пути к достижению высшего уровня никогда не бывает коротких путей.
В некотором смысле, полемика вокруг «дистилляции», поднятая компанией Anthropic, сама по себе является микрокосмом этой эпохи искусственного интеллекта.
Вся эта индустрия с самого начала строилась на неоднозначных правилах: обучение на основе кода, написанного людьми, итерации с использованием результатов, полученных другими пользователями с открытым исходным кодом, и быстрые действия в тех случаях, когда закон прямо этого не запрещает.
Теперь правила начинают ужесточаться — сначала авторское право, затем микросхемы, а теперь и API… Кто устанавливает эти правила? Кто от них выигрывает? Кто злоупотребляет правилами в личных целях, притворяясь при этом человеком?
Ответы на эти вопросы становятся все более очевидными.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (идентификатор WeChat: ifanr), где вы сможете в кратчайшие сроки увидеть еще больше интересного контента.
ifanr | Оригинальная ссылка · Посмотреть комментарии · Sina Weibo