Компания Nvidia, что необычно, воздержалась от выпуска видеокарт, а Дженсен Хуанг только что сенсационно представил новую 2,5-тонную «ядерную бомбу». DeepSeek также снова подверглась критике.

Впервые за пять лет компания Nvidia не представила на выставке CES видеокарту потребительского класса.
Генеральный директор Дженсен Хуанг вышел на центральную сцену NVIDIA Live, все еще в той же блестящей куртке из крокодиловой кожи, что и в прошлом году.

В отличие от своего сольного выступления в прошлом году, в 2026 году Дженсен Хуанг был насыщен мероприятиями, посетив три события за 48 часов: от NVIDIA Live до Siemens Industrial AI Dialogue и конференции Lenovo TechWorld.
В прошлый раз он представил видеокарты серии RTX 50 на выставке CES, но на этот раз новыми главными героями стали физика, искусственный интеллект и робототехника.
Вычислительная платформа Vera Rubin запущена, и чем больше вы покупаете, тем больше экономите.
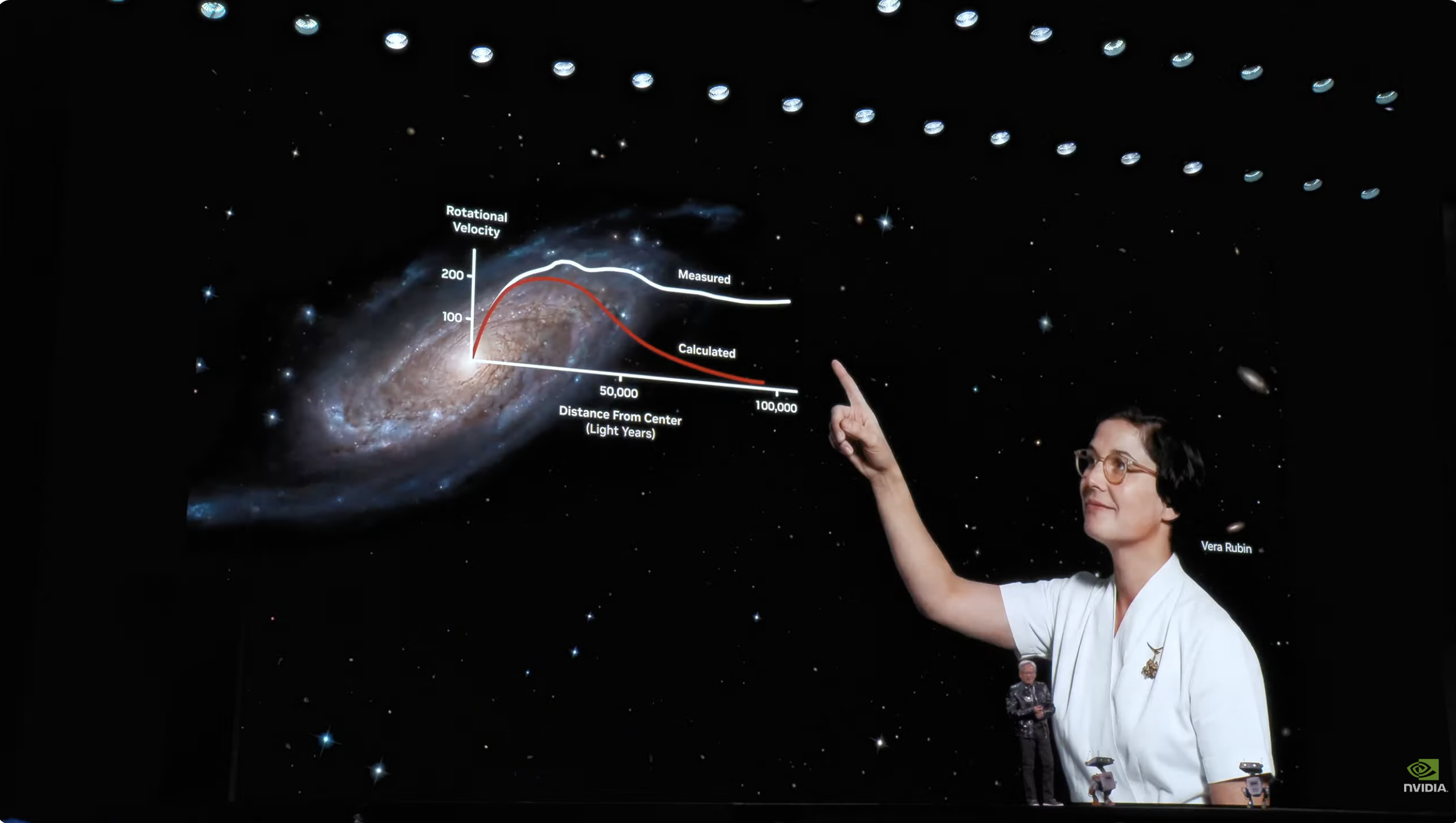
Во время пресс-конференции Хуан, известный своими игривыми выходками, вынес на сцену 2,5-тонную стойку с серверами для ИИ, тем самым представив главную новость мероприятия: вычислительную платформу Vera Rubin, названную в честь астрономов, открывших темную материю, с единственной целью:
Ускорьте обучение ИИ, чтобы быстрее вывести на рынок модели следующего поколения.
Обычно у Nvidia есть правило, согласно которому в каждом поколении продуктов модифицируется максимум 1-2 чипа. Но на этот раз Вера Рубин нарушила эту традицию, перепроектировав сразу 6 чипов и запустив их в серийное производство.
Причина в том, что с замедлением действия закона Мура традиционные методы повышения производительности больше не могут угнаться за десятикратным ежегодным ростом моделей ИИ. Поэтому NVIDIA выбрала «экстремальный подход к совместному проектированию» — одновременную разработку инноваций на всех уровнях всех чипов и всей платформы.

Эти 6 чипов:
1. Процессор Vera:
– 88 пользовательских ядер NVIDIA Olympus
– Использует технологию NVIDIA Space Multithreading, поддерживающую 176 потоков.
– Пропускная способность NVLink C2C: 1,8 ТБ/с
– Объем системной памяти 1,5 ТБ (в 3 раза больше, чем у Grace)
– Пропускная способность LPDDR5X 1,2 ТБ/с
– 227 миллиардов транзисторов

2. Графический процессор Rubin:
– Производительность NVFP4 в области вывода данных составляет 50 PFLOPS, что в 5 раз выше, чем у его предшественника, Blackwell.
– В нем 336 миллиардов транзисторов, что в 1,6 раза больше, чем в Blackwell.
– Оснащенный двигателем Transformer третьего поколения, он может динамически регулировать точность в соответствии с потребностями модели Transformer.

3. Сетевой адаптер ConnectX-9:
– Ethernet 800 Гбит/с на базе 200G PAM4 SerDes
– Программируемый RDMA и ускоритель тракта передачи данных
– Сертифицировано CNSA и FIPS
– 23 миллиарда транзисторов

4. BlueField-4 DPU:
– Комплексный механизм, разработанный специально для платформ хранения данных на основе искусственного интеллекта следующего поколения.
– 800 Гбит/с DPU для SmartNIC и процессоров хранения данных
– 64-ядерный процессор Grace в паре с ConnectX-9
– 126 миллиардов транзисторов

5. Микросхема коммутатора NVLink-6:
– Объединяет 18 вычислительных узлов, поддерживая до 72 графических процессоров Rubin для совместной работы в качестве единого целого.
– В архитектуре NVLink 6 каждый графический процессор может обеспечить пропускную способность связи между всеми участниками до 3,6 ТБ в секунду.
– Использует SerDes 400G, поддерживает внутрисетевые SHARP-коллективы, обеспечивая агрегированные коммуникационные операции в коммутируемой сети.

6. Микросхема оптической коммутации Ethernet Spectrum-6
– 512 каналов, 200 Гбит/с на канал, что обеспечивает более высокую скорость передачи данных.
– Технология кремниевой фотоники с использованием процесса COOP от TSMC
– Оснащен интегрированной оптикой.
– 352 миллиарда транзисторов

Благодаря глубокой интеграции шести чипов, система Vera Rubin NVL72 обеспечивает всестороннее повышение производительности по сравнению с предыдущим поколением Blackwell.
В задачах вывода NVFP4 чип продемонстрировал впечатляющую вычислительную мощность в 3,6 EFLOPS, что в 5 раз превосходит показатели предыдущего поколения архитектуры Blackwell. В задачах обучения NVFP4 он достиг 2,5 EFLOPS, что представляет собой 3,5-кратное повышение производительности.
Что касается объема памяти, NVL72 оснащен 54 ТБ памяти LPDDR5X, что в три раза больше, чем у предшественника. Емкость HBM (High Bandwidth Memory) достигает 20,7 ТБ, что в 1,5 раза больше. По показателю пропускной способности, пропускная способность HBM4 достигает 1,6 ПБ/с, что в 2,8 раза больше; пропускная способность Scale-Up достигает впечатляющих 260 ТБ/с, что в 2 раза больше.
Несмотря на столь значительное улучшение характеристик, количество транзисторов увеличилось всего в 1,7 раза, достигнув 220 триллионов, что демонстрирует инновационные возможности технологии производства полупроводников.

В области инженерного проектирования Вера Рубин также совершила технологические прорывы.
Предыдущие суперкомпьютерные узлы требовали 43 кабеля, их сборка занимала 2 часа, и они были подвержены ошибкам. Теперь же узел Vera Rubin не использует ни одного кабеля, имеет всего 6 линий жидкостного охлаждения и может быть собран за 5 минут.
Ещё более впечатляет то, что задняя часть стойки покрыта почти 3,2 километрами медных кабелей. 5000 медных кабелей образуют магистральную сеть NVLink, обеспечивая скорость передачи данных 400 Гбит/с. По словам Хуанга: «Она может весить несколько сотен килограммов. Чтобы справиться с этой работой, нужно быть генеральным директором в отличной физической форме».
В мире искусственного интеллекта время — деньги. Важный статистический показатель: Рубину требуется всего 1/4 от количества параметров для обучения модели с 10 триллионами параметров, а стоимость генерации токена примерно в 10 раз ниже, чем у Блэквелла.
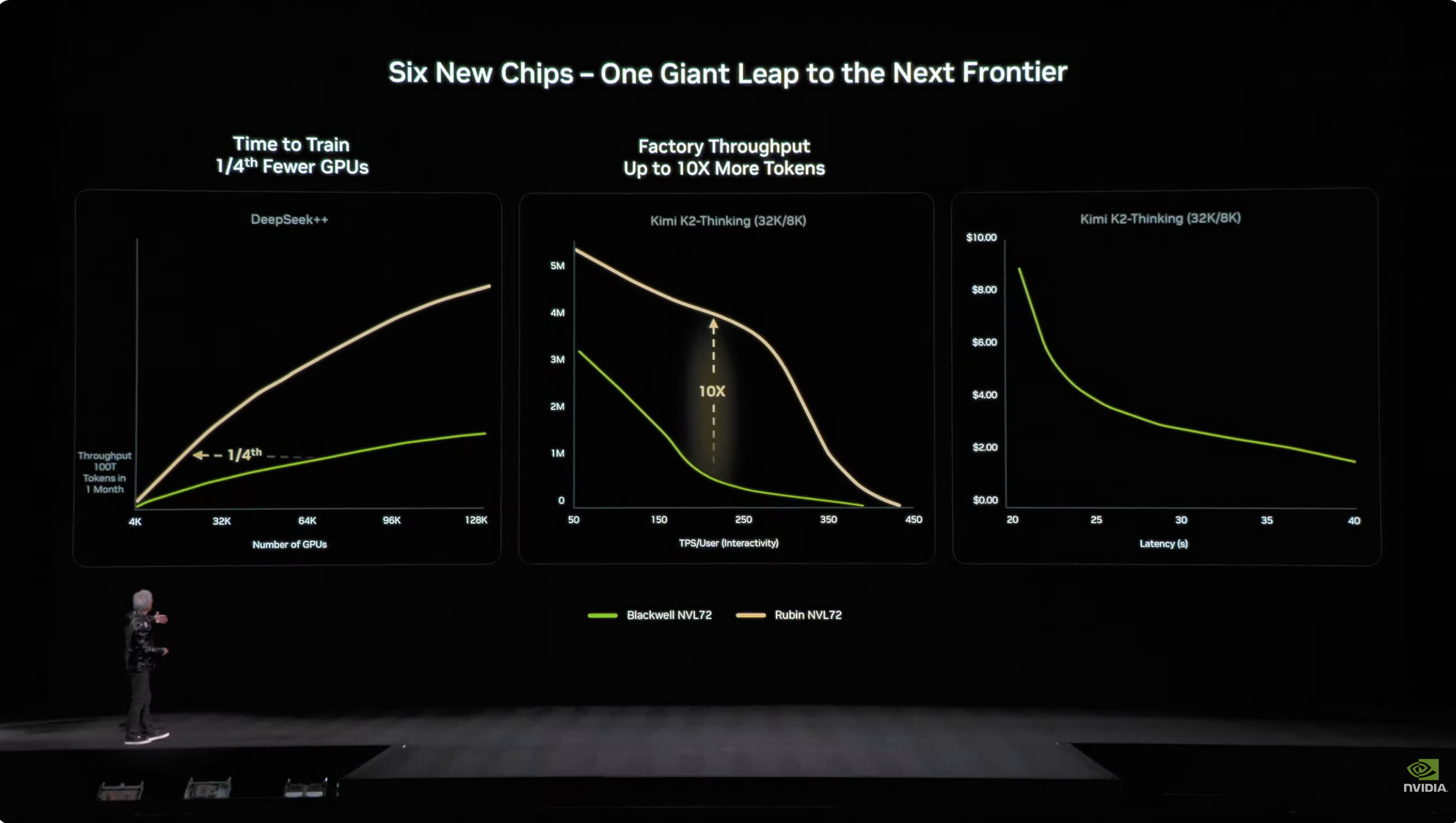
Кроме того, хотя Rubin потребляет вдвое больше энергии, чем Grace Blackwell, улучшение его производительности значительно перевешивает увеличение энергопотребления: общее улучшение производительности при выводе результатов составляет 5 раз, а при обучении — 3,5 раза.
Что еще более важно, Rubin обеспечивает десятикратное увеличение пропускной способности (количество токенов ИИ на ватт — на доллар) по сравнению с Blackwell, что означает удвоение потенциальной выручки для центра обработки данных стоимостью 50 миллиардов долларов.
В прошлом самой большой проблемой в индустрии ИИ была недостаточная контекстная память. В частности, ИИ создает «кэш ключ-значение» (KV-кэш) во время работы, который является «рабочей памятью» ИИ. Проблема в том, что по мере увеличения длины диалогов и размера моделей память HBM становится все менее достаточной.

В прошлом году Nvidia выпустила архитектуру Grace-Blackwell для расширения памяти, но этого оказалось недостаточно. Решение Веры Рубин предполагает развертывание процессоров BlueField-4 внутри стойки для управления кэшем ключ-значение.
Каждый узел оснащен четырьмя модулями BlueField-4, каждый из которых имеет 150 ТБ контекстной памяти. При выделении памяти для графических процессоров каждый графический процессор получает дополнительные 16 ТБ памяти, в то время как встроенная память графического процессора составляет всего около 1 ТБ. Важно отметить, что пропускная способность остается на уровне 200 Гбит/с, поэтому скорость не снижается.
Но одной лишь пропускной способности недостаточно. Чтобы «данные», распределенные по десяткам стоек и десяткам тысяч графических процессоров, работали вместе как единый модуль памяти, сеть должна быть «достаточно большой, достаточно быстрой и достаточно стабильной». Вот тут-то и вступает в дело Spectrum-X.
Spectrum-X — это первая в мире комплексная сетевая платформа Ethernet от NVIDIA, «разработанная специально для генеративного искусственного интеллекта». Последнее поколение Spectrum-X использует технологический процесс COOP компании TSMC и интегрирует технологию кремниевой фотоники, обеспечивая 512 каналов и скорость 200 Гбит/с.
Хуанг произвел расчеты: центр обработки данных мощностью в гигаватт стоит 50 миллиардов долларов, а Spectrum-X может обеспечить увеличение пропускной способности на 25%, что эквивалентно экономии в 5 миллиардов долларов. «Можно сказать, что эта сетевая система практически „подарена“».
В плане безопасности Vera Rubin также поддерживает конфиденциальные вычисления. Все данные шифруются на протяжении всего процесса передачи, хранения и вычислений, включая все шины, такие как каналы PCIe, NVLink и связь между ЦП и ГП.
Предприятия могут уверенно развертывать свои модели во внешних системах, не опасаясь утечек данных.
DeepSeek потряс мир; открытый исходный код и интеллектуальные агенты стали основным направлением в области искусственного интеллекта.
После основной части вернемся к началу речи. Хуан Жэньсюнь, выйдя на сцену, сразу же озвучил поразительную цифру: примерно 10 триллионов долларов, вложенных в вычислительные ресурсы за последнее десятилетие, полностью модернизируются.
Но это не просто обновление оборудования; это скорее сдвиг в программных парадигмах. Он конкретно упомянул модели агентного интеллекта и назвал Cursor, который полностью изменил внутренний способ программирования Nvidia.

Что действительно накалило атмосферу, так это его высокая оценка сообщества разработчиков открытого программного обеспечения. Хуан Жэньсюнь откровенно заявил, что прорыв DeepSeek V1 в прошлом году удивил весь мир; будучи первой системой вывода с открытым исходным кодом, она напрямую послужила толчком к развитию всей отрасли. В презентации известные китайские разработчики Kimi k2 и DeepSeek V3.2 были указаны как первый и второй проекты с открытым исходным кодом соответственно.
Хуанг считает, что, хотя модели с открытым исходным кодом в настоящее время могут отставать от самых передовых моделей примерно на шесть месяцев, новая модель будет появляться каждые шесть месяцев.
Такой стремительный темп итераций — это то, чему стремятся соответствовать как стартапы, так и гиганты, а также исследователи, включая Nvidia.
На этот раз они не просто продавали лопаты и рекламировали видеокарты; Nvidia построила многомиллиардный суперкомпьютер DGX Cloud и разработала передовые модели, такие как La Proteina (синтез белка) и OpenFold 3.

▲ Экосистема моделей с открытым исходным кодом NVIDIA охватывает биомедицину, физический ИИ, модели интеллектуальных агентов, робототехнику и автономное вождение, среди прочего.
В презентации также особо отметили многочисленные модели с открытым исходным кодом из семейства моделей NVIDIA Nemotron. Среди них модели, охватывающие такие области, как речь, мультимодальные вычисления, улучшение генерации поисковых запросов, безопасность и другие. Хуан Жэньсюнь также упомянул, что модели Nemotron с открытым исходным кодом демонстрируют отличные результаты в различных тестовых списках и активно используются многими предприятиями.
Что такое физический ИИ? Десятки моделей, выпущенных одновременно.
Если большие языковые модели решили проблемы «цифрового мира», то следующая амбиция Nvidia, очевидно, состоит в покорении «физического мира». Дженсен Хуанг отметил, что данных крайне мало для того, чтобы ИИ мог понять законы физики и выжить в реальности.
В дополнение к модели интеллектуального агента с открытым исходным кодом Nemotron, он предложил базовую архитектуру «трех компьютеров» для построения физического ИИ.
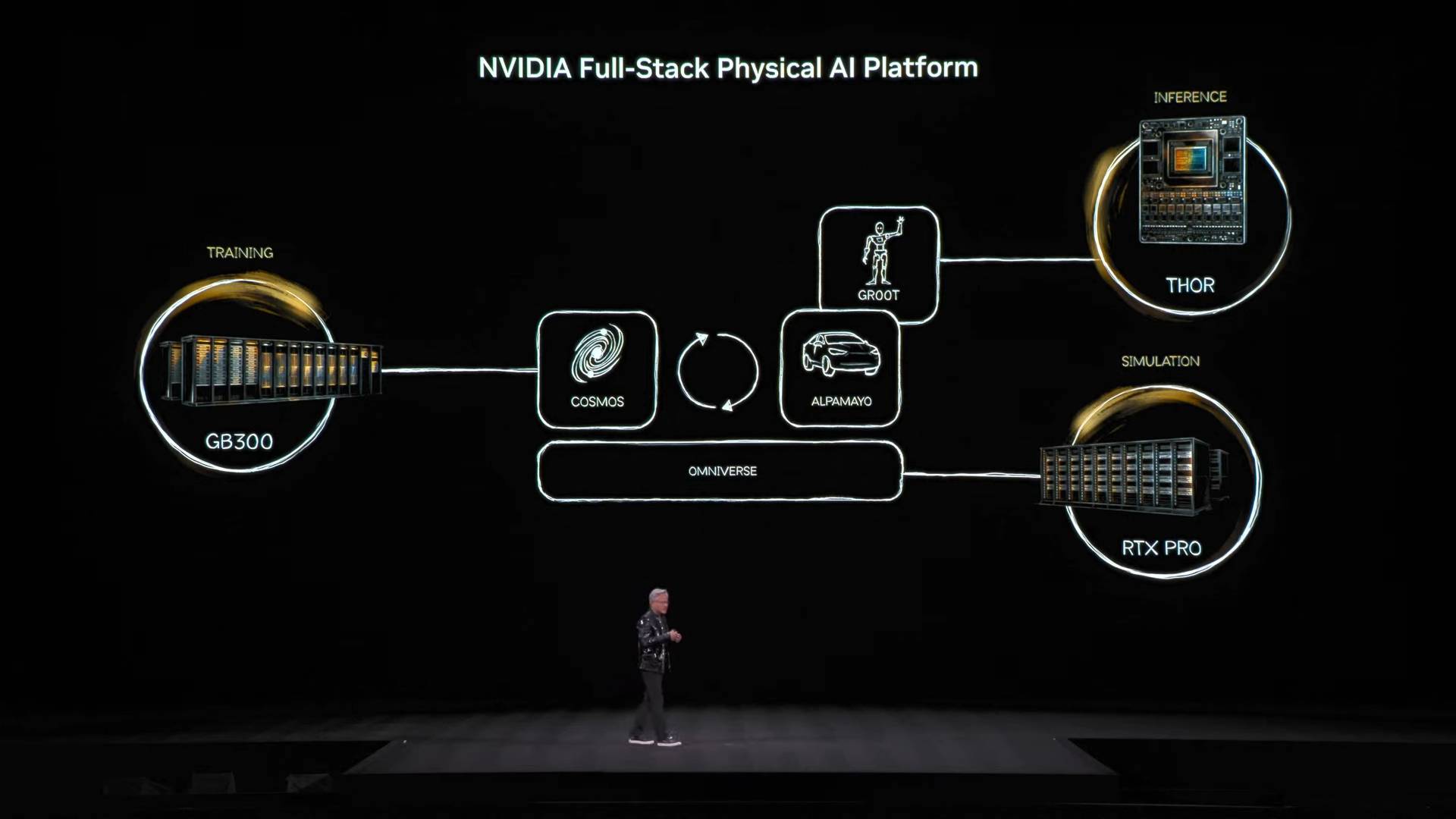
- Тренировочные компьютеры — это компьютеры, построенные на базе различных графических карт тренировочного класса, таких как архитектура GB300, показанная на рисунке.
- Компьютеры, выполняющие функции логического вывода, — это своего рода «мозжечок», расположенный на периферии робота или автомобиля, — отвечают за выполнение задач в реальном времени.
- Компьютеры-симуляторы, включая Omniverse и Cosmos, предоставляют виртуальную среду обучения для искусственного интеллекта, позволяя ему усваивать физическую обратную связь в условиях симуляции.

▲ Система Cosmos может генерировать большое количество обучающих сред для искусственного интеллекта, имитирующих физический мир.
На основе этой архитектуры Дженсен Хуанг официально выпустил Alpamayo, который потряс публику и стал первой в мире моделью автономного вождения, обладающей способностью мыслить и рассуждать.

В отличие от традиционных систем автономного вождения, Alpamayo — это система, обученная сквозным методом. Ее прорыв заключается в решении «проблемы длинного хвоста» автономного вождения. Столкнувшись со сложными дорожными условиями, с которыми она никогда прежде не сталкивалась, Alpamayo больше не ограничивается жестким выполнением кода, а может рассуждать подобно водителю-человеку.
«Она подсказывает, что делать дальше и почему принимает именно такое решение». В ходе демонстрации автомобиль вел себя на удивление естественно, разлагая чрезвычайно сложные ситуации на простые, понятные вещи.
Помимо демонстрации, все это не просто теория. Дженсен Хуанг объявил, что Mercedes-Benz CLA, оснащенный технологическим комплексом Alpamayo, официально поступит в продажу в США в первом квартале этого года, после чего последует его выход на европейский и азиатский рынки.

Этот автомобиль был признан самым безопасным в мире по версии NCAP благодаря уникальной конструкции NVIDIA с «двойным блоком безопасности». Когда сквозная модель искусственного интеллекта теряет уверенность в дорожных условиях, система немедленно переключается обратно на традиционный, более надежный режим защиты, чтобы обеспечить абсолютную безопасность.
На пресс-конференции Хуан также особо подчеркнул стратегию Nvidia в области робототехники.
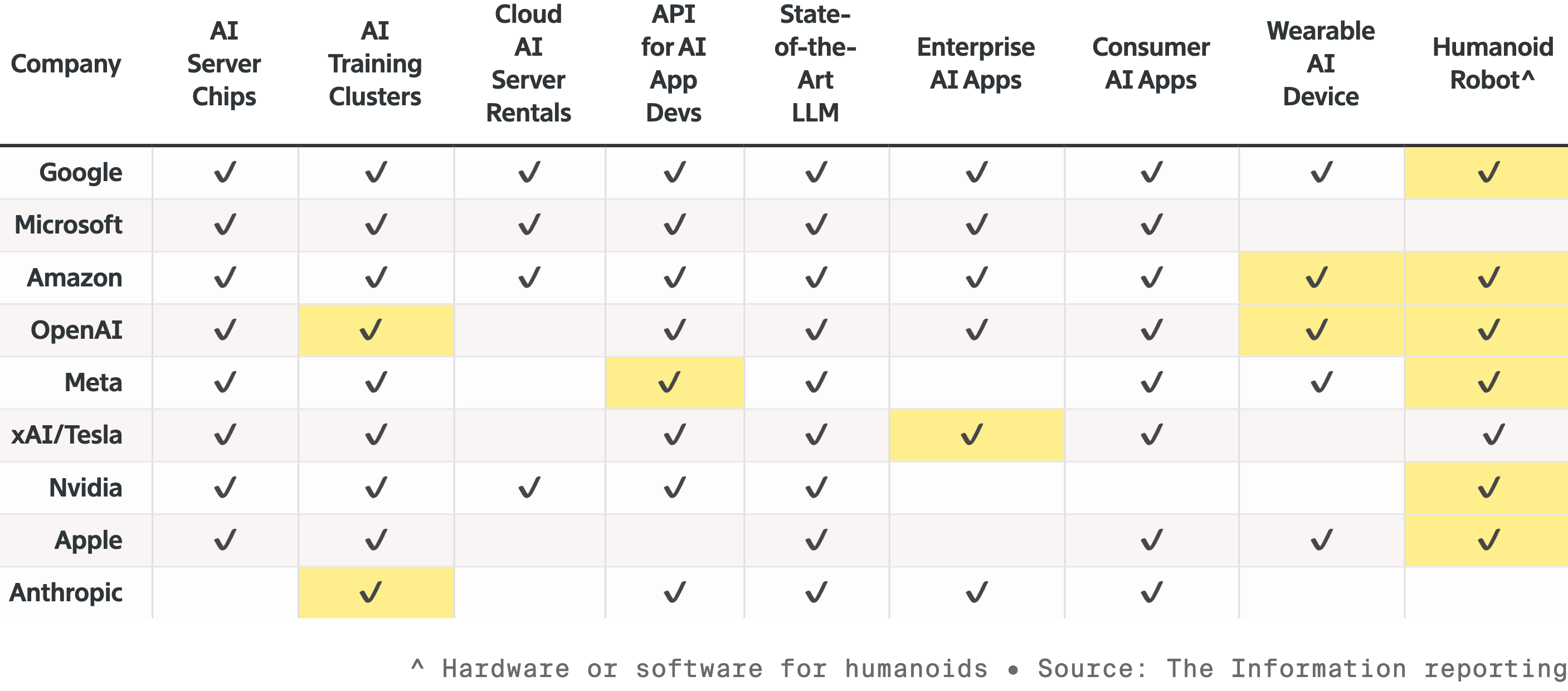
▲Конкуренция между девятью ведущими производителями оборудования для искусственного интеллекта и смежных областей, каждый из которых расширяет свои линейки продукции, особенно стремясь завоевать долю рынка робототехники. Выделенные ячейки представляют собой новые продукты, выпущенные с прошлого года.
Все роботы будут оснащены мини-компьютерами Jetson и обучены в симуляторе Isaac на платформе Omniverse. NVIDIA также интегрирует эту технологию в промышленные системы таких компаний, как Synopsys, Cadence и Siemens.

▲ Дженсен Хуанг пригласил человекоподобных и четвероногих роботов от таких компаний, как Boston Dynamics и Agility, «выйти на сцену». Он подчеркнул, что самым большим роботом на самом деле является сама фабрика.
В основе концепции NVIDIA лежит идея ускорения проектирования будущих чипов, систем и моделирования производственных процессов с помощью физического искусственного интеллекта NVIDIA. На презентации роботы Disney вновь произвели фурор, что побудило Дженсена Хуанга в шутку отметить этих очаровательных роботов:
«Вас спроектируют на компьютерах, изготовят на компьютерах и даже протестируют и проверят на компьютерах, прежде чем вы действительно столкнетесь с гравитацией».

Если бы вам не сказали, что это Хуан Жэньсюнь, вы могли бы принять всю его вступительную речь за презентацию нового продукта от производителя моделей.
В нынешней ситуации, когда повсеместно распространены теории «пузыря ИИ», а также замедляется действие закона Мура, Дженсену Хуангу, похоже, необходимо продемонстрировать, на что ИИ способен на самом деле, чтобы повысить доверие к нему.
Помимо демонстрации мощных возможностей новой суперкомпьютерной платформы искусственного интеллекта Vera Rubin, призванной удовлетворить потребность в вычислительных мощностях, он также вложил больше усилий в разработку приложений и программного обеспечения, чем когда-либо прежде, стремясь показать нам интуитивно понятные изменения, которые принесет ИИ.
Кроме того, как сказал Хуан Жэньсюнь, в прошлом они создавали чипы для виртуального мира, а теперь лично демонстрируют их, сосредотачивая внимание на физическом искусственном интеллекте, представленном автономным вождением и человекоподобными роботами, и выходя в реальный физический мир, где конкуренция в отрасли более ожесточенная.
В конце концов, продажа оружия может продолжаться только в случае начала войны.
Мо Чунюй, Чжан Цзыхао и Яо Тун
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (идентификатор WeChat: ifanr), где вы сможете в кратчайшие сроки увидеть еще больше интересного контента.
ifanr | Оригинальная ссылка · Посмотреть комментарии · Sina Weibo