Итоги 2025 года от гуру ИИ Карпати стали вирусными: ИИ — одновременно гений и глупец; эти 6 поворотных моментов — самые важные.

В связи с недавним выпуском различных итоговых обзоров года, Андрей Карпати, бывший сооснователь OpenAI, также поделился своим итоговым заключением по крупным моделям.
Ранее в этом году его выступление в Молодежном клубе стало вирусным, представив множество новых точек зрения:
- Наступила эра программного обеспечения 3.0: от первоначального кода, написанного человеком (1.0), до подачи данных для обучения моделей (2.0), мы вступили в эру 3.0, когда модель напрямую «задаётся подсказками».
- LLM — это новая операционная система: это не обычный товар, как водопроводная вода, а сложная ОС, отвечающая за планирование использования памяти (контекстное окно) и процессора (вычислительная мощность для вывода результатов).
- Десятилетие для агентов: Не стоит ожидать, что ИИ-агенты достигнут зрелости за год. Нам потребуется десятилетие, чтобы перейти от 99% к 99,999% надежности.
В своем итоговом обзоре за 2025 год Карпати в очередной раз проанализировал, какой именно «мозг» искусственного интеллекта развился в этом году.
Ниже приведён краткий перевод годового отчёта Карпати, при этом APPSO предлагает более доступные интерпретации без изменения первоначального смысла.
Чтобы прочитать оригинальную статью, пожалуйста, нажмите здесь.  https://karpathy.bearblog.dev/year-in-review-2025/
https://karpathy.bearblog.dev/year-in-review-2025/
2025 год станет годом сильного роста и большой неопределенности для LLM (Large Language Model). Ниже приведены несколько «сдвигов парадигмы», которые, на мой взгляд, заслуживают внимания и несколько неожиданны — изменения, которые не только изменили ландшафт отрасли, но и оказали глубокое влияние на мое понимание концепций.
 Краткая версия:
Краткая версия:
2025 год одновременно захватывающий и немного неожиданный.
LLM (Learning and Library Intelligence) предстает как новый вид интеллекта, который одновременно намного умнее и намного глупее, чем я ожидал.
Тем не менее, они чрезвычайно полезны. Я считаю, что даже с учетом нынешних возможностей отрасль не использовала и 10% своего потенциала. В то же время, еще столько идей предстоит изучить, и концептуально эта область все еще кажется обширной. Как я уже упоминал ранее в этом году, я также (по-видимому, парадоксально) верю, что мы увидим дальнейший быстрый прогресс, но впереди еще много тяжелой работы.
Пристегните ремни, мы скоро отправимся.
1. RLVR: Обучение ИИ «думать» так же, как при решении математических задач олимпиад.
Прежде чем объяснять эту сложную фундаментальную концепцию, давайте посмотрим, как раньше проводилось обучение больших моделей.
В начале 2025 года "старая тройка" формул подготовки магистров права в крупных лабораториях оставалась очень стабильной:
1. Предварительное обучение : Как и в случае с GPT-3, позвольте ИИ прочитать статьи со всего интернета и научиться говорить.
2. Контролируемая тонкая настройка (SFT): Пусть кто-нибудь запишет стандартные ответы и научит ИИ отвечать на вопросы.
3. Обучение с подкреплением на основе обратной связи от человека (RLHF): Пусть ИИ сгенерирует несколько ответов, а люди оценят их, обучая его быть более симпатичным.
Какие изменения произошли сейчас?
В 2025 году мы добавили в эту формулу мощный компонент: RLVR (обучение с подкреплением на основе проверяемых вознаграждений).
Что это значит?
Проще говоря, это означает, что теперь оценивать решения будут не люди (люди слишком медлительны и субъективны), а ИИ будет выполнять задачи со «стандартными ответами», такие как математические задачи или написание кода. Правильное решение остается правильным, а неправильное — неправильным; машина может автоматически это проверить.
В результате миллионов самопроверок и проб и ошибок модели спонтанно выработали стратегии, которые выглядят как «рассуждение» . Они научились разбивать большие проблемы на более мелкие шаги и даже освоили продвинутые методы, такие как «возвращение к проверке» (см. статью DeepSeek R1).
Основные сравнения:
- Старая парадигма (RLHF) подобна обучению ребенка написанию эссе. Поскольку стандартного ответа не существует, ИИ с трудом определяет, на каком этапе допущена ошибка, и может лишь имитировать человеческий тон.
- Новая парадигма (RLVR) подобна помещению ИИ в продвинутый математический тренировочный лагерь. Не нужно обучать его конкретным мыслительным процессам; достаточно дать ему достаточно задач и обратной связи по ответам, и он сам разберется в закономерностях решения проблем.
Эта стратегия оказалась настолько эффективной, что к 2025 году большая часть вычислительной мощности была поглощена этим «пожирающим деньги монстром». В результате модель не стала больше, но время обучения увеличилось . Мы также получили новый инструмент: возможность для ИИ думать дольше . OpenAI o1 стал началом, а o3 — настоящим поворотным моментом.
2. Призраки против животных: ИИ — это не «цифровой питомец».
В 2025 году я и вся отрасль наконец-то интуитивно поняли «форму» интеллектуального потенциала в сфере магистерских программ.
Жуткая аналогия: мы не «эволюционируем/выращиваем животных», как домашних питомцев; мы «призываем призраков».
Почему я так говорю?
Потому что всё в ИИ отличается от живых организмов. Человеческий мозг оптимизирован для выживания в джунглях и для размножения; в то время как мозг человека оптимизирован для имитации человеческого языка, получения высоких оценок в математических задачах и завоевания симпатий в соревновательных сферах.
Неровный интеллект:
Именно из-за существования проверяемых вознаграждений (RLVR) возможности ИИ в определенных областях (таких как математика и программирование) могут внезапно резко возрасти. Это приводит к крайне комичному явлению:
- Он также является непревзойденным гением (способен решать сложные математические задачи за секунды);
- Ещё один умственно отсталый ученик начальной школы (которого легко обмануть простыми логическими уловками).
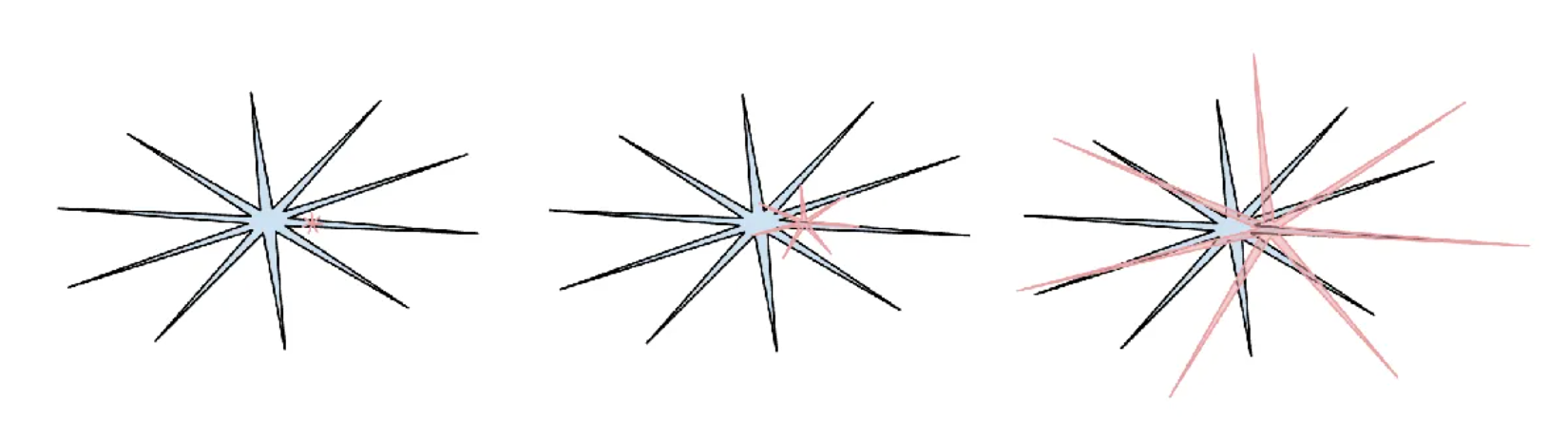
▲Здесь Карпати использует мем: человеческий интеллект — это гладкий синий круг, а интеллект искусственного интеллекта — красная фигура, покрытая шипами, как морской еж. Это довольно уместно.
Это также объясняет, почему я утратил веру в текущие рейтинги.
В чём суть «манипулирования рейтингом»?
Поскольку таблица лидеров поддается проверке, RLVR можно использовать для целенаправленного обучения. Современные лаборатории, по сути, практикуют «обучение, ориентированное на экзамены», целенаправленно развивая способность ИИ соответствовать тестовым вопросам. «Обучение на тестовых наборах» стало не просто обманом, а новым видом искусства.
3. Курсор: это не просто редактор, это «подрядчик».
Взрывной успех Cursor в этом году выявил новую истину: прикладной уровень LLM оказался гораздо толще, чем мы предполагали.
Люди начали говорить о «курсорах для медицинской сферы» и «курсорах для юридической сферы». Что именно делают эти приложения?
- "Инженер контекста": Помогает организовать всю фоновую информацию для передачи в ИИ.
- «Прораб»: тайно руководит работой нескольких магистров права, которые занимаются решением сложных задач и помогают вам экономить деньги.
- «Дистанционное управление»: предоставляет ползунок для регулировки «автономии» и определения того, сколько действий вы позволяете выполнять ИИ.
Прогноз: Крупные лаборатории моделирования (такие как OpenAI) будут отвечать за обучение «студентов-универсалов», в то время как разработчики приложений (такие как Cursor) будут отвечать за предоставление этим студентам частных данных и инструментов, формируя из них «профессиональные строительные команды» .
4. Код Клода: «Кибер-призрак», живущий в вашем компьютере
Появление кода Клода (CC) стало настоящим откровением. Это не просто агент (интеллектуальный агент), способный писать код; что еще важнее, он живет внутри вашего компьютера .
В сравнении с ними, я считаю, что OpenAI пошла в неправильном направлении.
Первые агенты OpenAI работали в облаке (ChatGPT), что было слишком далеко от реальной среды. Хотя облачные интеллектуальные агенты звучат как конечная цель AGI, на нынешнем неравномерном этапе перехода локальные решения — это оптимальный путь.
Почему местоположение имеет значение?
Потому что ваш код, ваша конфигурация, ваши ключи, ваша запутанная среда — всё это локально. Компания Anthropic (материнская компания Клода) правильно расставила приоритеты; они уместили ИИ в крошечный интерфейс командной строки (CLI).
Это уже не просто веб-страница в вашем браузере (как Google); это «кибер-призрак», обитающий в вашем компьютере и готовый в любой момент выполнить вашу работу. Вот как должно выглядеть взаимодействие с искусственным интеллектом в будущем.
5. Кодирование атмосферы
Что такое Vibe Coding?
Это слово я придумал в Твиттере (и оно действительно стало вирусным): оно означает, что для написания кода больше не нужно понимать синтаксис; вам нужно просто описать свои «намерения» и «чувства» на английском языке, а остальное предоставить ИИ.
Какие изменения это повлекло за собой?
- Для обычных людей: барьер для освоения программирования полностью исчез.
- Для экспертов: Код стал таким же дешевым, одноразовым и пригодным для повторного использования, как туалетная бумага.
Например, чтобы найти ошибку, я могу поручить ИИ написать специальное приложение прямо на месте для тестирования, а затем удалить его. Раньше писать приложение только для того, чтобы найти ошибку? Безумие! Но в 2025 году код будет бесплатным.
Vibe Coding полностью изменит индустрию программного обеспечения и пересмотрит должностные обязанности программистов.
6. Нано-банан: у ИИ наконец-то появилось собственное «лицо»

Почему современное взаимодействие с ИИ настолько античеловечно?
Будь то ChatGPT или Claude, мы по-прежнему общаемся с ними, «набирая текст». Это как использовать черно-белую командную строку DOS в 1980-х годах.
Правда в том, что компьютеры любят текст, но люди ненавидят читать текст. Люди — существа визуальные; нам нравится рассматривать картинки, таблицы и видео.
Модель Google Gemini Nano Banana (вымышленное кодовое название модели, обозначающее некую многомодальную модель взаимодействия) — это еще один сдвиг парадигмы в 2025 году . Она намекает на то, как будут выглядеть графические пользовательские интерфейсы (GUI) в будущем .
Искусственный интеллект будущего не должен просто выдавать кучу текста; он должен напрямую рисовать картинки, генерировать веб-страницы или отображать интерактивные панели. Это больше, чем просто «рисование»; это гибридная возможность, которая объединяет генерацию текста, логическое мышление и визуальное выражение.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (идентификатор WeChat: ifanr), где вы сможете в кратчайшие сроки увидеть еще больше интересного контента.
ifanr | Оригинальная ссылка · Посмотреть комментарии · Sina Weibo