Наконец-то вышел Gemini 3. В чём его настоящий козырь?
Когда вышла предварительная версия Gemini 3 Pro, первой реакцией многих, вероятно, было: «Наконец-то !»
После почти месяца тизеров и утечек — с намёками на более строгие параметры, более продуманный вывод и более сложную графику — все с нетерпением ждут этого. Добавьте к этому контратаки от OpenAI и Gork, и станет ясно, что Gemini 3 станет грандиозным релизом.

Основные преимущества Gemini 3 также хорошо знакомы: более чёткая логика, более естественный диалог и более естественное понимание мультимодальной информации. Официально утверждается, что он превосходит Gemini 2.5 по ряду академических показателей.
Однако если сосредоточиться только на этих цифрах, легко упустить из виду более важное изменение:
Gemini 3 воспринимается не как обновление модели, а скорее как «обновление системы» пакета Google, на котором она основана.
Что касается модернизации моделей, Google уже обозначила свою позицию достаточно четко.
Давайте сначала быстро пройдемся по «жестким показателям», чтобы у всех сложилось четкое представление:
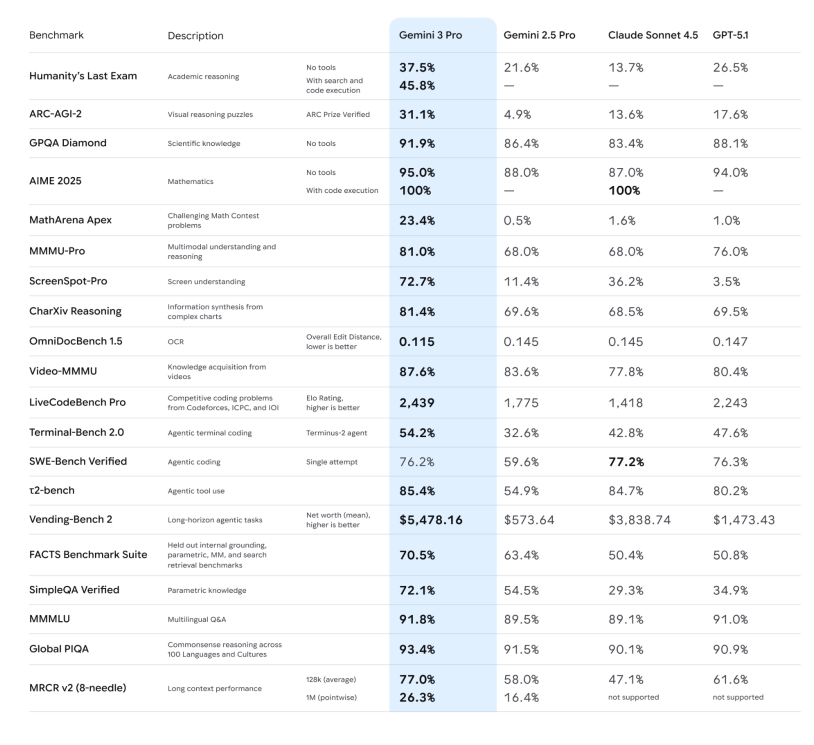 – Способность к рассуждению: В официальном заявлении подчеркивается, что Gemini 3 Pro достиг новых рекордных результатов в ряде сложных тестов на рассуждение и математических задач, таких как Humanity's Last Exam, GPQA Diamond и MathArena, позиционируя его как «модель рассуждения докторского уровня».
– Способность к рассуждению: В официальном заявлении подчеркивается, что Gemini 3 Pro достиг новых рекордных результатов в ряде сложных тестов на рассуждение и математических задач, таких как Humanity's Last Exam, GPQA Diamond и MathArena, позиционируя его как «модель рассуждения докторского уровня».
– Мультимодальное понимание: они могут не только просматривать изображения и PDF-файлы, но и достигать лучших в отрасли результатов по длинным видеороликам и мультимодальным экзаменам (MMMU-Pro, Video-MMMU), демонстрируя значительное улучшение своей способности описывать изображения и резюмировать ключевые моменты из видеороликов.
-Режим глубокого мышления: тесты ARC-AGI показывают, что включение режима глубокого мышления приводит к заметному улучшению решения новых типов задач.
С этой точки зрения Gemini 3 легко можно охарактеризовать как «более умное поколение моделей общего назначения, чем 2.5». Но если это всё, то это просто новое имя в таблице лидеров. Даже Джош Вудворд в интервью заявил, что эти жёсткие показатели следует использовать лишь в качестве ориентира.

Другими словами, «сколько баллов было набрано» — это всего лишь относительно интуитивно понятный способ представления оценки. Самое интересное — где Google внедрил этот метод и что он намерен с ним связать. В этом обновлении «нативная мультимодальная» технология, безусловно, является главным приоритетом.

Если бы нам пришлось провести разделительную линию для современных крупных моделей, то она звучала бы так: они просто «поддерживают мультимодальные возможности» или же они изначально были разработаны как «изначально мультимодальные»?
Эта концепция была предложена Google в 2023 году, в эпоху Gemini 1, и с тех пор она стала основой их стратегии: смешивание различных модальностей, таких как текст, код, изображения, аудио и видео, в предтренировочных данных с самого начала, а не обучение сначала большой текстовой модели, а затем присоединение к ней визуальных и речевых подмоделей.
Последний подход — это стратегия, которую многие модели использовали ранее при работе с мультимодальной обработкой. По сути, он всё ещё работает по принципу «конвейера»: речь сначала должна быть загружена в ASR, а затем преобразованный текст — в языковую модель; обработка изображений сначала должна проходить через независимый визуальный кодер, а затем признаки подключаются к языковой модели.
Gemini 3 пытается свернуть этот конвейер: тот же большой Трансформер видит текст, изображения, аудио и даже видеофрагменты одновременно на этапе предварительного обучения, что позволяет ему изучать общие черты и различия этих сигналов в одном и том же пространстве представления.
Меньше этапов обработки означает меньшие потери информации. Для модели нативное мультимодальное обучение — это не просто «изучение большего количества входных форматов», но и устранение ненужных этапов. Сокращение этих этапов позволяет сохранить более полную интонацию, более насыщенные визуальные детали и более точный временной порядок.
Что еще важнее, это оказывает революционное влияние на прикладной уровень: когда модель с самого начала предполагает, что «мир многомодален», создаваемые ею продукты больше похожи на новую форму взаимодействия, чем на простых роботов, отвечающих на вопросы.
От поиска к антигравитации: рождение нового автобуса.
С запуском Gemini 3 Google также обновила режим ИИ в строке поиска. В этом режиме вы видите не ряд синих ссылок, а целую область динамического контента, генерируемого Gemini 3, которая может включать в себя сводки, структурированные карточки и временные шкалы. Несмотря на то, что он активируется при определенных условиях, поиск редко срабатывает сразу после выпуска модели.
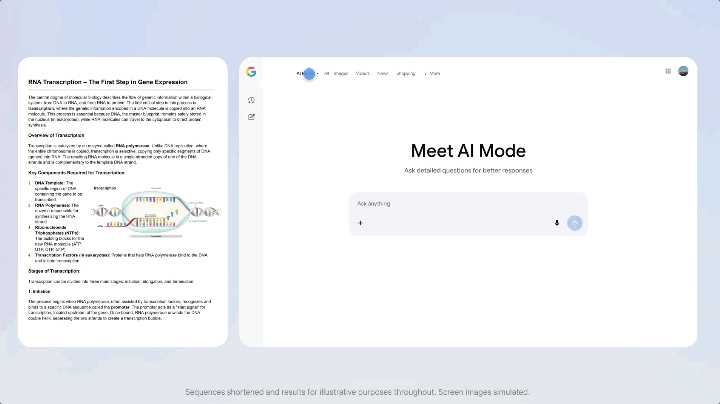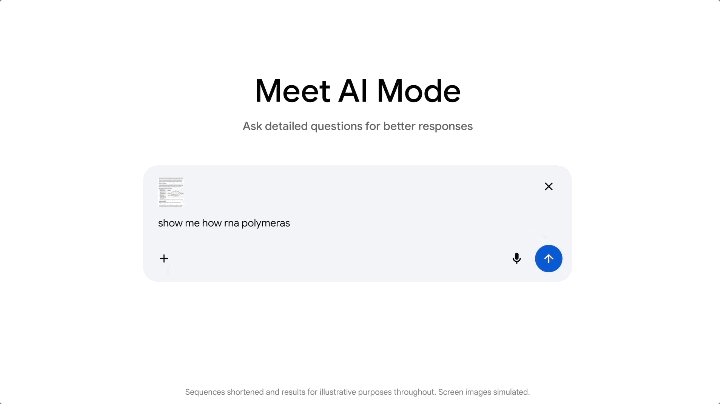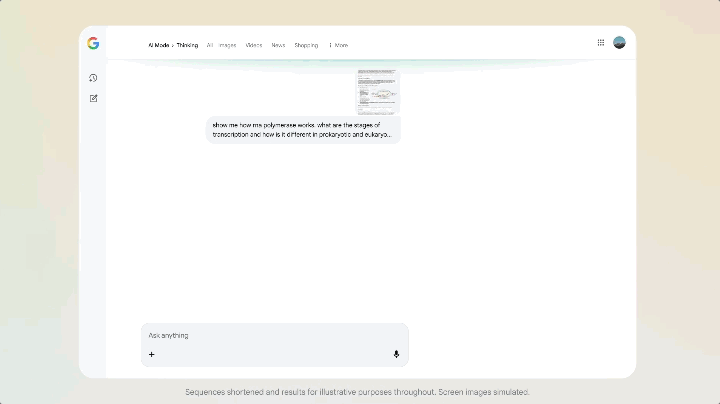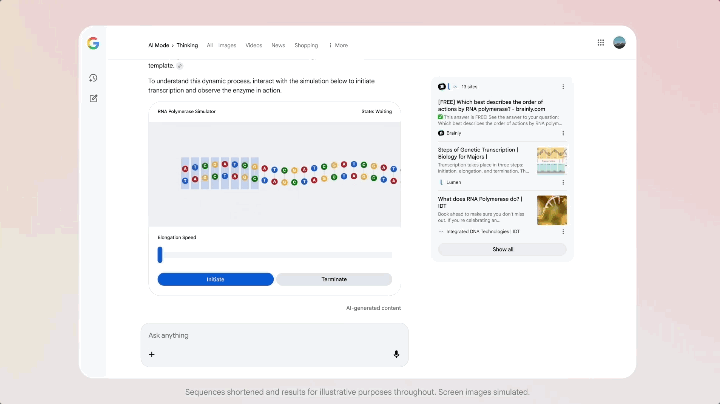
Еще более особенным является то, что режим ИИ поддерживает использование Gemini 3 для реализации новых генеративных пользовательских интерфейсов, таких как иммерсивные визуальные макеты, интерактивные инструменты и симуляции, — все это генерируется в реальном времени на основе содержания запроса.
Этот подход был принят и популяризирован в ряде продуктов Google. Официально он описывается как нечто вроде «мыслящего партнёра», предлагающего более прямые ответы, меньше банальностей, больше «собственных точек зрения» и больше «самостоятельных действий».
Благодаря его мультимодальным возможностям вы можете посмотреть видеозапись игры, и приложение поможет вам выявить двигательные проблемы и составить план тренировок; прослушать аудиолекцию, и приложение может создать обучающую карту с тестами; или объединить несколько рукописных заметок, PDF-файлов и веб-страниц в подробный обзор с изображениями и текстом.

Эта часть больше похожа на повествование о «суперперсональном помощнике»: после того, как Gemini 3 втиснут в приложение, оно пытается охватить ежедневные сценарии использования для учебы, жизни и легкой офисной работы в стиле «вы меньше беспокойтесь, я сделаю больше работы».
Что касается API, Gemini 3 Pro официально указан как «наиболее подходящий для кодирования агентств и виброкодирования»: то есть он может не только писать интерфейсы и создавать взаимодействия, но и вызывать инструменты и выполнять задачи разработки шаг за шагом в сложных задачах.
На этот раз наиболее впечатляющей является способность Gemini генерировать «полные» прикладные инструменты.

Это подводит нас к недавно выпущенной IDE: Antigravity. Официально она позиционируется как среда разработки «с ИИ в качестве главного героя». Это достигается следующими методами:
– Несколько агентов ИИ могут напрямую получать доступ к редактору, терминалу и браузеру;
Они разделят работу: кто-то будет писать код, кто-то будет искать документацию, а кто-то будет проводить тесты;
– Все операции будут записаны как артефакты: список задач, план выполнения, снимок экрана веб-страницы, запись экрана браузера и т. д., чтобы люди могли впоследствии проверить, «что вы сделали».
В ходе теста, в ходе которого видеоблогер брал интервью у менеджера по продукции компании Gemini, задача состояла в разработке веб-сайта для подбора персонала, а команда была настолько простой, что нужно было просто скопировать, скопировать, скопировать все, не внося никаких изменений, и просто вставить.
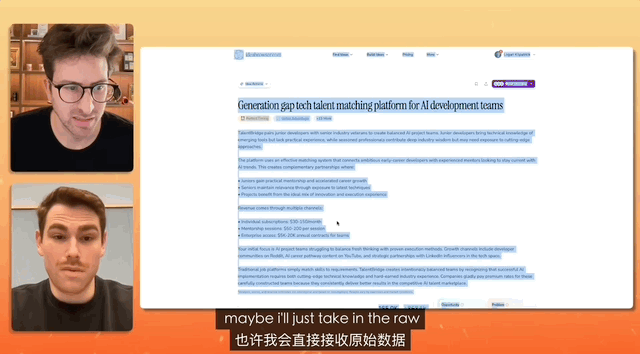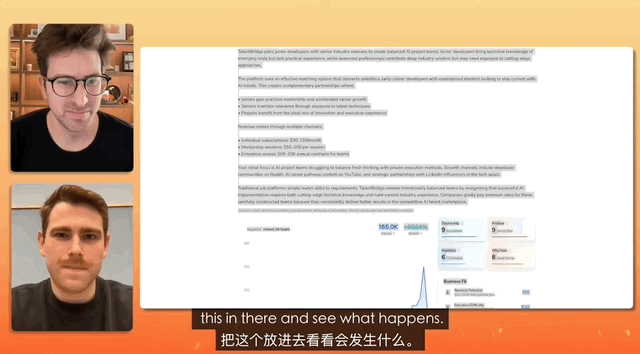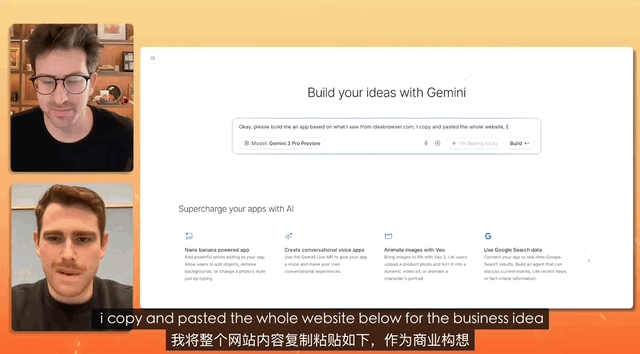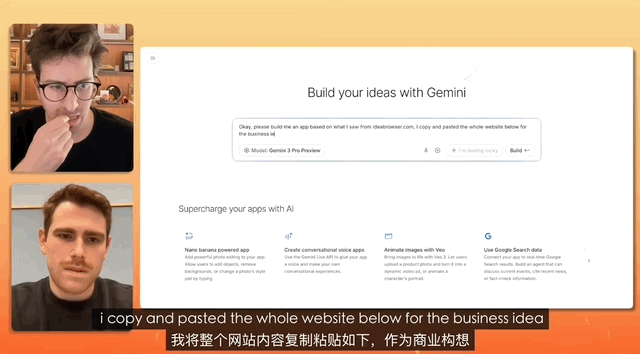
В конечном итоге специалисты Gemini самостоятельно проанализировали этот запутанный текст и фактически создали полноценный веб-сайт. Они самостоятельно выполнили настройку и размещение материалов.
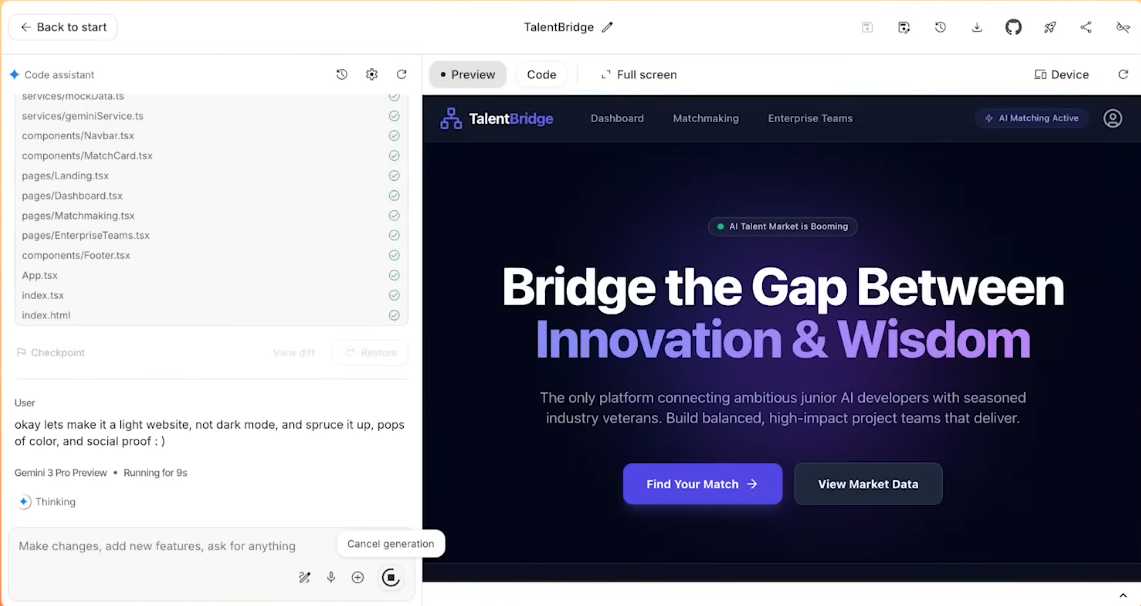
С этой точки зрения Gemini 3 — это не просто «более умная модель», а скорее новая шина, которую Google хочет использовать для объединения поиска, приложений, рабочего пространства и инструментов разработчика.
Возвращаясь к самому интуитивному ощущению: самое очевидное отличие Gemini 3 от предшественника заключается в том, что он более охотно и эффективно «помогает вам в совместной работе». Того же ожидает от него и Google.
Давление оказывается на все стороны
Помимо самой Google, предварительная версия Gemini 3 фактически открыла новую игру для всей отрасли крупного моделирования: взрывной рост приложений с возможностями мультимодальных решений неизбежен.
Раньше мультимодальные возможности (способность видеть и слышать) были бонусом; теперь «врожденная мультимодальность» станет базовым требованием, и это не может быть просто имитацией. Возможности сквозного аудиовизуального понимания Gemini 3 заставят OpenAI, Anthropic (Claude) и сообщество разработчиков ПО с открытым исходным кодом ускорить отказ от старых парадигм. Для производителей моделей, всё ещё полагающихся на «скриншоты + OCR» для распознавания изображений, начался технологический отсчёт.
«Оболочка» и средний уровень также будут испытывать колоссальное давление. Мощные возможности планирования агентов Gemini 3 напрямую вытесняют многие стартапы, занимающиеся агентными рабочими процессами, на текущем рынке. Когда базовая модель сама сможет идеально справляться с замкнутым циклом «декомпозиция намерения — вызов инструмента — обратная связь по результату», реальность «модели как приложения» станет на шаг ближе.
Кроме того, производители мобильных телефонов также могут почувствовать изменение тренда. Лёгкий дизайн и отзывчивость Gemini 3 свидетельствуют о том, что Google наращивает возможности для периферийных устройств. Учитывая предыдущее сотрудничество Apple с несколькими производителями различных моделей, можно предположить, что конкуренция в отрасли сместится от «войны вычислительной мощности», где сравниваются просто параметры облачных технологий, к «войне впечатлений», где сравниваются возможности внедрения в такие устройства, как мобильные телефоны, очки и автомобили.
Кто сильнее, уже не так важно; важно, кто «всегда в твоем распоряжении».
В первой половине соревнований среди крупномасштабных моделей вопрос по-прежнему стоял так: «Чья модель сильнее?». Параметры, оценки и рейтинги определялись «талантом». С появлением Gemini 3 вопрос постепенно сместился на: «Чьи возможности действительно заложены в продукте и в пользователях?»
На этот раз ответ Google представляет собой относительно ясный путь: начать с базовой модели Gemini 3, подключиться к вызовам инструментов и архитектуре агентства, а затем подключиться к конкретным интерфейсам продукта, таким как поиск, приложение Gemini, рабочее пространство и Antigravity.
Можно представить это так, как будто Google использует Gemini 3, чтобы сделать собственную мультимодальность своим новым козырем, и внедряет новую «умную шину» во все продукты своей экосистемы, чтобы один и тот же набор возможностей можно было использовать на всех уровнях.
Что касается того, может ли это в конечном итоге изменить то, как вы ищете, пишете и кодируете каждый день, ответ будет дан не на пресс-конференции, а в ближайшие несколько месяцев — мы увидим, сколько людей неосознанно включат это в свой ежедневный рабочий процесс.
Если уж на то пошло, то, кто на первом месте в таблице лидеров, может уже и не быть так уж важен.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (WeChat ID: ifanr), где вы сможете как можно скорее получить еще больше интересного контента.
ifanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo