Интервью Фэй-Фэй Ли на 10 000 слов: Пространственный интеллект — это следующий рубеж ИИ
В мире ИИ большие языковые модели уже поразили людей. Но Фэй-Фэй Ли сказала, что настоящий прорыв еще впереди. Она считает, что если ИИ не может понять трехмерный мир, он не завершен. Это ее следующая безумная цель.
Два дня назад Y Combinator обновил свой канал YouTube, опубликовав видеоинтервью с Фей-Фей Ли из AI Startup School в Сан-Франциско. В этом разговоре Фей-Фей Ли рассказала о создании проекта ImageNet, о быстром развитии глубокого обучения от распознавания объектов до современных генеративных моделей и выделила одну из самых сложных областей искусственного интеллекта, над которой она сейчас работает: пространственный интеллект.
В настоящее время Фэй-Фэй Ли является основателем и генеральным директором World Labs, компании пространственного интеллекта, которая занимается созданием крупномасштабных моделей мира для восприятия, генерации и взаимодействия с трехмерным миром. В этой беседе она также упомянула ряд вопросов о том, почему трехмерное моделирование мира важно для общего искусственного интеллекта (AGI) и почему пространственный интеллект может быть сложнее в достижении, чем язык .
Сохраните скорость потока, чтобы увидеть версию:
Это смена парадигмы в машинном обучении.
Рождение ImageNet — это не только личная мечта Фей-Фей Ли, но и смена парадигмы в области компьютерного зрения и глубокого обучения. Она поделилась, что в то время была просто одержима идеей «заставить машины видеть», и эта настойчивость и упорный труд создали важный момент, когда данные, графические процессоры и нейронные сети объединились . Теперь у нее новая одержимость, и она планирует продолжать возглавлять новую революцию ИИ.
Мы хотим сделать пространственный интеллект новым полем битвы ИИ
От распознавания объектов до понимания сцен, ИИ постепенно начал понимать сложную визуальную информацию. В нынешнюю эпоху AGI пришел новый виток трансформации. Она считает, что мир не является чисто генеративным, и только позволив ИИ понять трехмерный мир, мы сможем по-настоящему двигаться к AGI. Получение данных для больших языковых моделей просто, и модели пространственного интеллекта — это следующая задача, которую ей нужно преодолеть.
Я не могу раскрыть слишком много подробностей о World Labs.
На вопрос о сценариях применения, задуманных World Labs, и о том, чем они отличаются от текущей архитектуры LLM, Ли Фэйфей сказала, что интеграция программного обеспечения и оборудования, а также реализация метавселенной потребуют их пространственного интеллекта. В отличие от реализации LLM, она упомянула, что у людей нет сильного восприятия трехмерного мира, что очень сложно, но она верит в свою команду, в которой работают самые умные люди в мире, и вместе с ними они смогут решить эту проблему в двухмерном мире.
В сфере ИИ никогда не бойтесь неудач
В конце интервью Фэй-Фэй Ли поделилась собственным опытом роста, от иммиграции в США на учебу до должности директора Стэнфордской лаборатории искусственного интеллекта, вице-президента Google, а теперь и запуска собственного бизнеса, она сказала, что всегда начинала с нуля и усердно работала . Она также призвала молодых людей следовать своим интересам и любопытству, смело встречать вызовы и решать невыполнимые задачи.

Оригинальное видео: https://youtu.be/_PioN-CpOP0
Ниже приводится стенограмма интервью с небольшими изменениями в переводе.
Сфера машинного обучения нуждается в смене парадигмы
Модератор: Я очень рад, что доктор Фэй-Фэй Ли здесь с нами, у которой очень долгая карьера в области ИИ. Я думаю, многие ее знают. Вас также называют «крестной матерью ИИ», и одним из первых проектов, которые вы основали, был Imagenet в 2009 году, 16 лет назад. Этот проект цитировали более 80 000 раз, и он фактически заложил важный краеугольный камень для ИИ — проблемы данных. Можете ли вы рассказать, как появился этот проект? Работа в то время была действительно новаторской.

Фэй-Фэй Ли: Да, прежде всего, спасибо Диане, Гэри и всем здесь за приглашение. Я очень рада быть здесь, потому что я чувствую себя как все остальные. Я также теперь предприниматель, я только что основала компанию, поэтому я очень рада быть здесь.
Да, вы правы, на самом деле мы задумали этот проект почти 18 лет назад, время действительно летит. Я был на первом курсе в качестве доцента Принстонского университета. Мир искусственного интеллекта и машинного обучения в то время был совершенно другим, чем сейчас. Было очень мало данных, и, по крайней мере, в области компьютерного зрения алгоритмы вообще не работали. В то время не было никакой промышленности, и общественность едва знала слово «искусственный интеллект». Но все еще была группа людей, начиная с основателей искусственного интеллекта, таких как Джон Маккарти, а затем такие люди, как Джефф Хинтон. Я думаю, что у всех нас есть мечта об искусственном интеллекте, и мы действительно хотим, чтобы машины имели возможность думать и работать. И моя личная мечта — дать машинам визуальные возможности, потому что зрение — это краеугольный камень интеллекта, а визуальный интеллект — это не просто восприятие, но и понимание мира и выполнение действий в мире.
Поэтому я был очень одержим проблемой «заставить машины видеть». В процессе моей одержимости разработкой алгоритмов машинного обучения мы пробовали нейронные сети, но это не сработало. Мы обратились к другим методам, таким как машины опорных векторов, но была проблема, которая всегда меня беспокоила, а именно проблема обобщения. Если вы работаете в области машинного обучения, вы должны понимать, что обобщение является основной математической основой и целью машинного обучения. Для того, чтобы эти алгоритмы могли обобщать, данные имеют решающее значение, но в то время в области компьютерного зрения данных почти не было. И я оказался первым поколением аспирантов, которые начали работать с данными, потому что я был первым поколением аспирантов, которые стали свидетелями появления Интернета и Интернета вещей.
Около 2007 года мы с моими студентами решили, что нам нужно сделать смелый шаг. Мы поспорили, что область машинного обучения нуждается в смене парадигмы, и что эта смена должна быть проведена с помощью методов, основанных на данных. Но в то время данных было недостаточно. Поэтому мы подумали, раз нет данных, давайте зайдем в Интернет и скачаем миллиарды изображений, что является самым большим числом, которое мы можем найти в Интернете, а затем построим глобальную систему визуальной классификации для обучения и оценки алгоритмов машинного обучения. Именно по этой причине проект ImageNet появился на свет и был фактически реализован.
Данные и открытый исходный код открывают весну глубокого обучения
Ведущий: Действительно, только когда появились некоторые многообещающие алгоритмы, начали появляться прорывы. Только когда в 2012 году появился AlexNet, это стало вторым ключевым фактором на пути к ИИ, получение достаточной вычислительной мощности и вложение в нее достаточного количества ресурсов. И алгоритмы выявили критический момент, когда вы засеваете ИИ данными, сообщество постепенно начинает находить больше решений, что дает импульс для развития ИИ, верно?
Фэй-Фэй Ли: В 2009 году мы опубликовали небольшую статью только в качестве постера CVPR.
С 2009 по 2012 год, до появления AlexNet, мы действительно верили, что данные будут управлять ИИ, но у нас почти не было четких сигналов того, что этот подход будет работать.
Итак, мы сделали пару вещей, во-первых, мы решили сделать его открытым исходным кодом. Мы думали с самого начала, что он должен быть открытым исходным кодом, чтобы все исследовательское сообщество могло использовать его и работать вместе, чтобы решить эту проблему.
Во-вторых, мы создали вызов, потому что хотели, чтобы самые умные студенты и исследователи со всего мира приехали и поработали над этой проблемой. Это то, что мы называем вызовом ImageNet. Каждый год мы выпускаем тестовый набор данных, все данные платформы ImageNet используются для обучения, но мы выпускаем отдельный тестовый набор данных и приглашаем всех принять участие публично.
Первые несколько лет были действительно посвящены установлению эталона. Уровень ошибок производительности составил около 30%, что не было нулевой ошибкой, не было полностью случайным, но и не было большим. Но к третьему году, в 2012 году, я также написал об этом опыте в своей опубликованной книге.
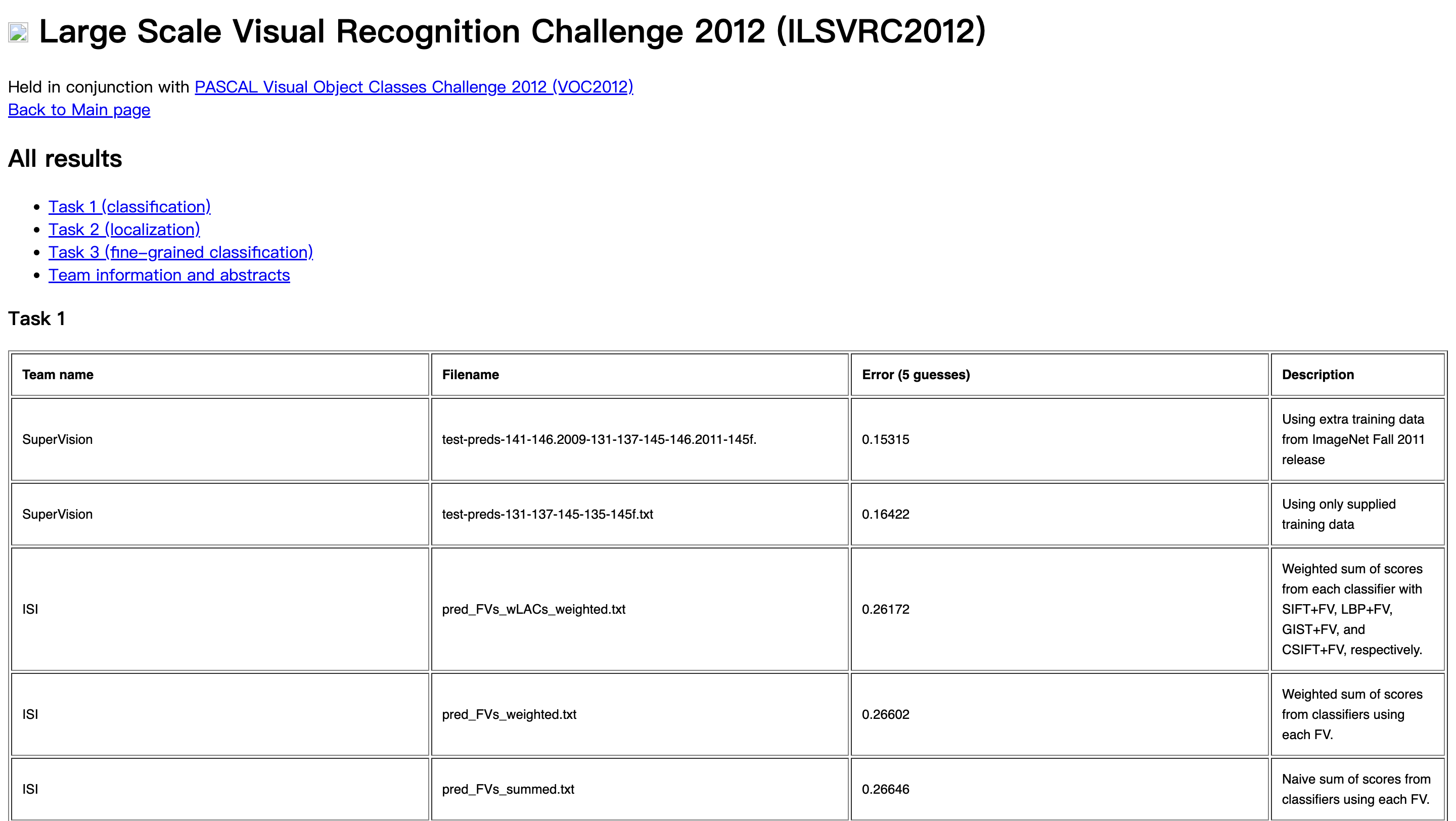
▲ Первое место в конкурсе ImageNet Challenge заняла команда SuperVision
Я до сих пор помню, это было в конце лета, и мы запускали все результаты конкурса ImageNet на наших серверах. Однажды поздно ночью я получил сообщение от своего аспиранта, который сказал мне, что есть результат, который действительно выделяется, и мы должны его проверить. Мы посмотрели и обнаружили, что это была сверточная нейронная сеть. В то время это была не AlexNet, а работа команды Джеффри Хинтона под названием «SuperVision». Это была очень умная игра слов, объединяющая «супер» и «контролируемое обучение». Мы посмотрели на работу, проделанную SuperVision, которая на самом деле является старым алгоритмом. Сверточные нейронные сети были опубликованы еще в 1980-х годах, но они просто внесли некоторые изменения в алгоритм, но когда мы впервые увидели это, мы были действительно удивлены, что произошел такой огромный прорыв.
Конечно, следующее, что вы знаете, это то, что мы представили это на семинаре ImageNet Challenge во Флоренции на ICCV (Международная конференция по компьютерному зрению) в том году, и Алекс Крижевский и его команда пришли, и много людей пришли. Сегодня все называют этот момент "моментом AlexNet" ImageNet Challenge.
Я также хотел бы добавить, что это был не просто успех сверточной нейронной сети, но и первый раз, когда Алекс и его команда объединили два GPU для вычислений глубокого обучения. Это был действительно первый важный момент для объединения данных, GPU и нейронных сетей.
Моя карьера — это не только рассказывание сцен
Модератор: Следуя тенденции развития интеллекта компьютерного зрения, ImageNet действительно заложил основу для решения проблемы распознавания объектов. Затем искусственный интеллект достиг точки, когда он может решить проблему понимания сцен. Потому что вы и ваши студенты, такие как Андре Карпати, начали уметь описывать сцены. Можете ли вы рассказать о переходе от распознавания объектов к пониманию сцен?
Фэй-Фэй Ли: Да, ImageNet решает проблему того, как идентифицировать объекты на изображении, когда вы его видите, например, «это кошка, это стул», что является базовой проблемой визуального распознавания. Но с тех пор, как я поступил в область искусственного интеллекта в качестве аспиранта, у меня была мечта. Я думаю, что эта мечта может занять сто лет, чтобы воплотиться в жизнь, то есть рассказать историю мира. Представьте себе, что когда люди открывают глаза, вы просто открываете глаза и видите не «людей, стулья, столы», а на самом деле видите конференц-зал, видите экран, сцену, аудиторию, камеру и т. д. Вы можете описать всю сцену, что является человеческой способностью, основой визуального интеллекта, и это имеет решающее значение для нашей повседневной жизни. Поэтому я всегда думал, что эта проблема займет всю мою жизнь. Когда я окончил аспирантуру, я сказал себе, что если смогу создать алгоритм, который сможет рассказать историю сцены, то я добьюсь успеха. Таким было мое видение моей карьеры в то время.
Однако этот момент по-настоящему наступил с развитием глубокого обучения, а затем к моей лаборатории присоединились Андре и Джастин Джонсон, и мы начали замечать признаки столкновения естественного языка и зрения.
Андре и я придумали проблему описания изображений или повествования. И, короче говоря, где-то в 2015 году Андре и я опубликовали ряд статей, включая те, что были опубликованы в то же время, что и мы, которые на самом деле были одними из самых ранних работ по созданию компьютеров для генерации подписей к изображениям. Я почти подумал: как мне жить дальше? Это была моя давняя мечта. Это был действительно мощный момент для нас обоих.

В прошлом году я выступал на TED и использовал твит, который Андре отправил несколько лет назад, сразу после того, как закончил работу над подписями к изображениям. Это была его докторская диссертация. Я в шутку сказал ему: «Эй, Андре, почему бы нам не сделать наоборот? Сгенерировать изображение из предложения ». Конечно, он понял, что я шучу, и ответил: «Ха-ха, я ухожу первым». Мир был явно не готов к этому. Но теперь, перенесемся в сегодняшний день, мы все знаем, что генеративный ИИ теперь может генерировать прекрасные изображения из предложения. Так что мораль этой истории в том, что ИИ прошел огромную эволюцию.
Лично я чувствую себя самым счастливым человеком в мире, потому что вся моя карьера началась с конца зимы ИИ и начала подъема ИИ, и большая часть моей работы и карьеры тесно связана с этим изменением или каким-то образом способствовала этому изменению. Так что я чувствую себя очень счастливым, благодарным и гордым в некотором роде.
Ведущий: Я думаю, самое безумное то, что даже несмотря на то, что вы достигли своей мечты об описании сцен и даже создании сцен с помощью моделей диффузии, вы все еще мечтаете о большем. Потому что вся траектория компьютерного зрения прошла путь от распознавания объектов к пониманию сцен, а теперь и к концепции «мира». И вы решили перейти от академической среды, от профессорской должности к предпринимательству, став основателем и генеральным директором World Labs. Можете ли вы рассказать о том, что такое «мир»? Он сложнее, чем сцены и объекты?
Фэй-Фэй Ли: Да, это действительно безумие. Конечно, все знают, что произошло в прошлом, и мне действительно сложно подвести итог прогрессу за последние пять или шесть лет. Мы находимся в цивилизованном моменте технологического прогресса. Как ученый в области компьютерного зрения, мы стали свидетелями невероятного роста от изображений к описаниям изображений и генерации изображений с использованием методов диффузии. Хотя эти достижения захватывающие, в то же время мы также видим еще одну чрезвычайно захватывающую область, которая является областью языка, особенно LLM (большие языковые модели). Например, в ноябре 2022 года появление ChatGPT действительно открыло дверь для генеративных моделей, которые в принципе могут пройти тест Тьюринга и так далее. Поэтому даже пожилые люди, такие как я, чувствуют себя очень взволнованными и начинают смело думать о том, какова следующая цель.

Как ученый, занимающийся компьютерным зрением, я часто вдохновляюсь эволюцией и наукой о мозге. Много раз в своей карьере я искал следующую проблему «Полярной звезды», которую нужно решить. Я спрашивал себя, что сделала эволюция или развитие мозга? Одна вещь, которая очень примечательна и ценна, заключается в том, что эволюция человеческого языка заняла около 300–500 миллионов лет, даже если мы очень щедры, это всего лишь менее миллиона лет. Люди — единственный вид со сложным языком. Мы можем говорить о языке животных, но с точки зрения функции языка как инструмента для общения, рассуждения и абстрагирования, только люди обладают этой способностью. Этот эволюционный процесс занял менее 500 000 лет.
Но если вы подумаете о зрении, подумаете о способности понимать трехмерный мир, понимать, как двигаться в этом трехмерном мире, как ориентироваться, взаимодействовать, понимать, общаться с ним, то на все это ушло 540 миллионов лет эволюции.
Около 540 миллионов лет назад первые трилобиты начали развивать зрительное восприятие под водой. С тех пор зрение стало ключом к движению эволюционной гонки вооружений. До появления зрения формы жизни животных были относительно простыми, почти без сложных изменений на протяжении почти 500 миллионов лет. Но в последующие 540 миллионов лет именно из-за способности понимать мир началась эволюционная гонка вооружений, и интеллект животных продолжал совершенствоваться.

▲ Команда основателей iWorld Labs: Фэй-Фэй Ли (первая справа), Джастин Джонсон, Кристоф Ласснер, Бен Милденхолл
Итак, для меня решение проблемы пространственного интеллекта, понимание трехмерного мира, создание трехмерного мира, рассуждения о трехмерном мире, выполнение действий в трехмерном мире является фундаментальной проблемой для ИИ. Для меня ИИ без пространственного интеллекта не может быть полным. Я хочу решить эту проблему. А это подразумевает создание «моделей мира», которые выходят за рамки плоских пикселей, за рамки языка, чтобы действительно охватить трехмерную структуру и пространственный интеллект мира. К счастью, независимо от того, сколько мне лет, я всегда работаю с самыми удивительными молодыми людьми. Поэтому сейчас я создаю эту компанию с тремя удивительными молодыми, но первоклассными технологами: Джастином Джонсоном, Беном Милденхоллом и Кристофом Ласснером. Мы попытаемся решить то, что, по моему мнению, является самой сложной проблемой в ИИ на данный момент.
Получить данные о пространственном интеллекте гораздо сложнее, чем данные о языке.
Ведущий: Действительно, все они очень талантливые люди. Крис — основатель Pulsar, которая является технологией дифференцируемого рендеринга, а теперь и бэкендом рендеринга на основе сфер для PyTorch3D. А Джастин Джонсон, как ваш бывший студент, действительно обладает сильным системным инженерным мышлением и реализовал передачу стилей в реальном времени на основе нейронных сетей. А затем Бен, он является автором статьи NeRF (Neural Radiance Fields). Так что это действительно суперэлитная команда. Вам нужна такая элитная команда, потому что мы говорили об этом раньше, зрение на самом деле сложнее, чем язык. Может быть, это немного спорно, потому что LLM по сути одномерны, верно, но вы говорите о понимании большого количества трехмерных структур. Так почему же это так сложно? Почему это сейчас мощнее, чем большие языки?
Фэй-Фэй Ли: Да, вы можете понять сложность нашей проблемы. Язык по своей сути одномерен, а грамматика возникает последовательно, поэтому моделирование последовательности-в-последовательности является таким классическим. Другой момент заключается в том, что язык — это чисто генеративный сигнал, чего многие люди не осознают. В природе нет языка, вы не можете потрогать язык, вы не можете увидеть язык, язык полностью генерируется из головы каждого. Язык — это чисто генеративный сигнал. Конечно, когда вы пишете его на бумаге, он там есть, но генерация, построение и полезность языка по своей сути очень генеративны, и мир гораздо сложнее этого.
Прежде всего, реальный мир трехмерен. Если добавить время, он четырехмерен, но пока мы будем рассматривать только пространство. Реальный мир по сути трехмерен, что само по себе является более сложной комбинаторной задачей.
Во-вторых, вы должны понимать, насколько сложно воспринимать визуальный мир как процесс проекции, будь то ваши глаза, сетчатка или камера, которая всегда сжимает трехмерную информацию в двухмерную. Математически это необратимый процесс, поэтому у людей и животных есть несколько чувств для решения этой проблемы.
В-третьих, мир не является чисто генеративным. Да, мы можем генерировать виртуальный 3D-мир, но он все равно должен следовать законам физики, а реальный мир существует вне нас. Фактически, теперь вы плавно переключаетесь между генерацией и реконструкцией. Поведение пользователя, практичность и сценарии применения совершенно иные. Если вы сосредоточитесь на генеративности, мы можем говорить об играх, метавселенных и других вещах; если вы сосредоточитесь на реальном мире, то мы говорим о робототехнике и так далее. Но все это находится в континууме моделирования мира и пространственного интеллекта.
Конечно, сейчас огромная проблема в том, что в интернете много языковых данных, а данные о пространственном интеллекте, хотя они все в наших мозгах, не так легкодоступны, как языковые данные. Так что все это причины, по которым эта проблема такая сложная. Но, честно говоря, именно это меня и волнует, потому что если бы эта проблема была легкой, это означало бы, что ее решил кто-то другой. И вся моя карьера была связана с решением чрезвычайно сложных, почти мечтательных проблем. Я думаю, что это та мечтательная проблема. Спасибо за вашу поддержку в решении этой проблемы.
В наших мировых лабораториях работают самые умные люди в мире
Ведущий: Да, даже исходя из самых базовых принципов, зрительная кора человеческого мозга имеет гораздо больше нейронов, обрабатывающих визуальные данные, чем нейронов, обрабатывающих язык. Как эта разница проявляется в моделях? В том числе, то, над чем вы работаете, также будет сильно отличаться по архитектуре от LLM, верно?
Фэй-Фэй Ли: Это очень хороший вопрос. На самом деле, в настоящее время существуют два разных подхода к этому вопросу.
Один из подходов LLM, где многие из шаблонов письма и расширения письма, которые мы видим в LLM, можно практически напрямую продвигать через самоконтролируемое обучение до тех пор, пока не будет достигнут «счастливый конец». Вы можете практически грубо контролировать себя, пока не достигнете своей цели.
Другой — построить модель мира, которая может быть более подробной и иерархической, потому что мир структурирован, и нам могут понадобиться некоторые сигналы, чтобы направлять его. Вы можете думать об этом как о предшествующих знаниях или как о контрольном сигнале в данных, в любом случае, это способ направлять обучение.
Я думаю, что это некоторые из открытых вопросов, которые нам предстоит решить, но вы правы. Если вы думаете о человеческом восприятии, прежде всего, мы даже не решили полностью все проблемы человеческого зрения, верно? Как 3D влияет на человеческое зрение? Это все еще не решенная проблема. Мы знаем, что механически глаза должны получать информацию через триангуляцию, но даже в этом случае у нас нет идеальной математической модели, и в действительности люди не особенно хороши в 3D-восприятии. Мы не очень хороши в понимании и управлении трехмерным миром, поэтому есть много вопросов, ожидающих ответа.
▲ Скриншоты некоторых членов World Labs
Итак, мы сейчас действительно находимся в фазе "World Labs". Единственное, на что я могу положиться, это то, что, по моему мнению, у нас самые умные люди в мире, которые могут решить эту проблему в "Pixel World".
Конвергенция аппаратного и программного обеспечения в конечном итоге произойдет
Модератор: Можем ли мы сказать, что конечный результат этих базовых моделей, которые строит World Labs, — это 3D-мир? Какие сценарии применения вы себе представляете? Я видел, что вы упомянули различные возможности от восприятия до генерации. Всегда существует напряжение между генеративными моделями и дискриминативными моделями, так какова же роль этих 3D-миров?
Фэй-Фэй Ли: Да, я, возможно, не смогу раскрыть слишком много о конкретных деталях World Labs, но с точки зрения пространственного интеллекта, это действительно место, которое меня волнует. Так же, как и язык, сценарии применения очень широки. С самого начала создания его могут использовать дизайнеры, архитекторы, промышленные дизайнеры и даже художники, 3D-художники и разработчики игр. Затем, робототехника и обучение роботов также являются очень важной областью применения, и использование моделей пространственного интеллекта или моделей мира очень широко. Кроме того, будут затронуты многие смежные отрасли, такие как маркетинг, развлечения и даже метавселенная. Я действительно взволнован метавселенной. Хотя она еще не полностью реализована, я знаю, что сейчас она не очень зрелая, но именно из-за этого я еще больше взволнован. Я думаю, что интеграция аппаратного и программного обеспечения в конечном итоге произойдет, и потенциал в будущем очень огромен. Это также очень интересное направление применения.

Ведущий: Я лично очень рад, что вы решаете проблему метавселенной. Я тоже пробовал это направление в своей компании раньше, поэтому я действительно рад видеть, что вы делаете это сейчас.
Ли Фэйфей: Да, я думаю, что сейчас больше сигналов о том, что Метавселенная постепенно реализуется. Я думаю, что оборудование действительно является одним из препятствий, но что более важно, вам нужно создание контента, а создание контента для Метавселенной требует моделей мира.
Начать с нуля — это моя зона комфорта.
Модератор: Давайте сменим тему. Для некоторых зрителей ваш переход от академической среды к роли основателя и генерального директора может показаться немного внезапным. Но на самом деле весь ваш жизненный опыт очень необычен, и это не первый раз, когда вы переходите от нуля к единице. Вы как-то рассказывали мне, как вы иммигрировали в Соединенные Штаты, не говорили по-английски в начале и управляли прачечным бизнесом со своей командой в течение нескольких лет. Можете ли вы рассказать о том, как этот опыт сформировал вас сегодня?
Фэй-Фэй Ли: Верно? Я знаю, что вы здесь, чтобы послушать мою историю о том, как я открыла прачечный бизнес. Ха-ха.
Мне было 19 лет, и я был в полном отчаянии. У меня не было возможности содержать семью, моим родителям нужно было, чтобы я пошел в колледж, а я хотел стать специалистом по физике в Принстоне. Поэтому я открыл химчистку. По терминологии Кремниевой долины, я был сборщиком средств, основателем и генеральным директором, кассиром и выполнял все домашние обязанности, и я, наконец, «ушел» через семь лет.
Возвращаясь к словам Дианы, особенно для всех вас, я смотрю на вас, и это действительно волнительно, потому что вы на половину, даже на треть, моложе меня, и вы так талантливы, просто действуйте, не бойтесь.
Я был таким всю свою карьеру, включая, конечно, работу в прачечной, и даже будучи профессором, я сделал несколько выборов. Однажды я решил пойти в некоторые отделы, где не было профессора компьютерного зрения, чтобы быть первым, что противоречило многим советам. Как молодому профессору, все будут рекомендовать вам пойти туда, где есть сообщество и старший наставник. Конечно, я также надеюсь иметь старшего наставника, но если нет, я все равно пойду своим путем. Так что я совсем этого не боюсь. Позже я пошел в Google и много узнал о бизнесе, о Google Cloud и B2B, а затем я основал стартап в Стэнфорде, потому что к 2018 году ИИ уже не просто проблема отрасли, он стал человеческой проблемой.
Люди всегда будут движущей силой технологического прогресса, но мы не можем потерять свою человечность. Я очень сосредоточен на том, как создать луч света в развитии ИИ, как ИИ может быть ориентирован на человека и как ИИ может помочь людям. Поэтому я вернулся в Стэнфорд и основал институт ИИ, ориентированный на человека, и управлял им как стартапом в течение пяти лет. Некоторые люди могут быть недовольны тем, что я управлял им как стартапом так долго в колледже, но я очень горжусь этим. Так что в каком-то смысле, я думаю, мне просто нравится быть предпринимателем. Мне нравится чувство начала с нуля, как будто стоишь на нулевой точке, забывая, что ты делал в прошлом, забывая, что другие думают о тебе, и просто делая это. Это моя зона комфорта, и мне очень нравится это чувство.
Я ищу интеллектуального бесстрашия.
Ведущий: Действительно здорово, что вы сделали все эти удивительные вещи, и вы были наставником многих легендарных исследователей, таких как Андрей Карпати, Джим Фань (сейчас в Nvidia), Цзя Дэн (сотрудничает над проектом ImageNet). Все они стали лидерами в отрасли. Когда они были еще студентами, что заставило вас увидеть, что они добьются необычайных вещей в будущем? Каким советом вы можете поделиться, чтобы мы узнали, как определить этих людей, которые изменят сферу ИИ?
Фэй-Фэй Ли: Прежде всего, я чувствую себя очень счастливым и не думаю, что я сделал больше для своих студентов, чем они. Они действительно делают меня лучшим человеком, лучшим учителем и лучшим исследователем. Для меня действительно большая честь работать со многими легендарными студентами, как вы сказали. Каждый студент очень индивидуален. Некоторые из них — чистые ученые, которые сосредоточены на решении научных проблем; некоторые — лидеры в отрасли; а некоторые — великие распространители знаний об ИИ. Но я думаю, что есть одна общая черта, и я призываю каждого студента здесь задуматься над этим вопросом.
Это также критерий, который я ищу в предпринимателях, особенно при найме. Я ищу интеллектуальное бесстрашие.
Я думаю, дело не только в том, откуда вы пришли или какую проблему вы пытаетесь решить, но и в смелости встретить вызов и взяться за его решение. Это бесстрашие — действительно основное качество успеха. Я научился этому у этих студентов, и как генеральный директор нашей лаборатории я также очень ценю это в своем процессе подбора персонала.
Ведущий: Вы также набираете много людей для World Labs, то есть вы ищете те же должности?
Фэй-Фэй Ли: Да, мы действительно нанимаем в больших масштабах. Мы нанимаем инженерные таланты, таланты по продуктам, таланты 3D и таланты генеративного моделирования. Если вы чувствуете себя бесстрашным и увлечены решением интеллектуальных проблем, пожалуйста, свяжитесь со мной или посетите наш веб-сайт.
Вопросы и ответы аудитории
Вопрос 1: Привет, Фейфей, спасибо за беседу. Я твой большой поклонник! Мой вопрос: ты работал над визуальным распознаванием более 20 лет назад. Сейчас я хочу начать докторскую диссертацию, в каком направлении мне следует учиться, чтобы стать такой же легендой, как ты?
Фэй-Фэй Ли: Я хочу дать тебе содержательный ответ, потому что я всегда могу сказать: делай то, что тебя волнует.
Во-первых, я думаю, что исследования ИИ изменились, потому что если вы работаете в докторантуре, вы находитесь в академической среде. Сегодня академическая среда больше не имеет большинства ресурсов ИИ, что сильно отличается от моей ситуации. Вычислительная мощность и ресурсы данных в академической среде очень ограничены, в то время как промышленность может проводить исследования гораздо быстрее. Поэтому, как аспирант, я бы рекомендовал вам искать направления, которые не конфликтуют с проблемами, которые промышленность может решить с помощью большей вычислительной мощности, более обширных данных и преимуществ командной работы. Есть еще некоторые очень фундаментальные проблемы, которые академическая среда может продолжать исследовать, и даже если у вас будет больше чипов, вы можете добиться большого прогресса.
Прежде всего, междисциплинарный ИИ — это очень захватывающая область для меня в академической среде, особенно с точки зрения научных открытий. Существует так много дисциплин, которые могут пересекаться с ИИ. Я думаю, что это область, которую можно развивать глубоко. С другой стороны, с точки зрения теории, я нахожу очень интересным, что возможности ИИ полностью превзошли теорию. Мы не знаем, как это сделать, не имеем интерпретируемости и не знаем, как выявить причинно-следственные связи. В нашем понимании модели все еще много неизвестных, и есть еще много направлений для дальнейшего продвижения развития этой области в будущем. В области компьютерного зрения все еще есть некоторые нерешенные проблемы. Кроме того, малые данные — это также очень интересная область, полная возможностей.
Опрашивающий 2: Спасибо, профессор Фэй-Фэй Ли, и еще раз поздравляю с получением почетной докторской степени Йельского университета. Мне выпала честь стать свидетелем этого момента лично месяц назад. Мой вопрос, с вашей точки зрения, более вероятно, что AGI появится как единая, единая модель или как система «модель-агент»?
Фэй-Фэй Ли: Было предложено два определения для заданного вами вопроса. Одно определение более теоретическое, определяющее AGI как интеллект, измеряемый каким-то тестом IQ, а другая часть вопроса более прагматична, фокусируясь на том, какие задачи может выполнять интеллектуальный агент. Честно говоря, я немного запутался в определении AGI.
Это потому, что на Дартмутской конференции 1956 года основатели искусственного интеллекта, включая Джона Маккарти и Марвина Мински, хотели решить проблему машин, которые могут «думать», что на самом деле было предложено Аланом Тьюрингом до них. Следовательно, это предложение не является узкой проблемой искусственного интеллекта, а широким предложением об интеллекте. Поэтому я не уверен, как отличить эту основополагающую проблему искусственного интеллекта от нового термина «AGI».
Для меня AGI и AI — это одно и то же, но я понимаю, что отрасль склонна рассматривать AGI как нечто большее, чем AI. Я борюсь с этим пониманием, потому что не знаю точно, что такое AGI и чем он отличается от AI. Если мы говорим, что сегодняшние «AGI-подобные» системы лучше справляются с определенными задачами, чем узкие системы AI 1970-х, 1980-х и 1990-х годов, я думаю, что это правильно, и это просто естественный прогресс в этой области. Но по сути, я думаю, что суть искусственного интеллекта заключается в создании машин, которые могут думать и делать вещи, как люди, или даже умнее людей. Поэтому я не знаю, как определить AGI, и поскольку я не могу определить его, я не могу сказать, является ли это единой системой.
Если рассматривать это с точки зрения мозга, то это единое целое, и можно назвать его единой системой, но функции его разнообразны, и в мозге есть даже зона Брока, которая отвечает за язык, зрительная кора за зрение, двигательная кора за движение и т. д. Поэтому я не знаю, как ответить на этот вопрос.
Опрашивающий 3: Привет, меня зовут Ясна. Прежде всего, я хочу сказать спасибо. Действительно вдохновляет видеть женщину, играющую ведущую роль в этой области. Как исследователь, преподаватель и предприниматель, я хотел бы спросить, в сегодняшней быстро развивающейся области искусственного интеллекта, какие люди, по вашему мнению, должны стремиться к получению ученой степени?
Фэй-Фэй Ли: Это отличный вопрос, и даже родители задавали мне его. Аспирантура — это четырех-пятилетний период интенсивного любопытства.
Вами движет любопытство, и это любопытство настолько сильно, что нет лучшего места для его реализации, чем здесь. Это отличается от стартапа, потому что в стартапе вы не можете быть движимы одним лишь любопытством. Вы должны быть осторожны, чтобы стартап не был движим только любопытством, и инвесторы будут вами недовольны. Он больше ориентирован на достижение бизнес-целей, и хотя в нем есть элемент любопытства, он не полностью движим любопытством. А для аспирантов любопытство решать проблемы или способность задавать вопросы очень важны, и я думаю, что те, кто поступает в аспирантуру с этим сильным любопытством, действительно получат удовольствие от этих четырех или пяти лет, и даже если внешний мир будет быстро развиваться, вы все равно будете чувствовать себя удовлетворенными, потому что следовали своему любопытству.
Опрашивающий 4: Прежде всего, я хочу поблагодарить вас за то, что вы нашли время поделиться с нами своими взглядами. Вы упомянули, что открытый исходный код сыграл важную роль в развитии интеллекта изображений. Теперь, с выпуском и разработкой больших языковых моделей, мы видим, что разные организации придерживаются разных стратегий в отношении открытого исходного кода. Некоторые организации полностью закрыты, некоторые организации полностью открыты для всей своей исследовательской структуры, а некоторые организации придерживаются компромиссного подхода, открывают веса моделей или принимают ограничительные лицензии и т. д. Поэтому я хотел бы спросить, что вы думаете об этих различных подходах с открытым исходным кодом? Какой подход, по вашему мнению, является правильным? Как компания ИИ, как должен работать открытый исходный код?
Фэй-Фэй Ли: Я думаю, когда в экосистеме есть разные способы открытого исходного кода, вся среда здорова. Я не категоричен в том, должен ли это быть открытый исходный код или закрытый исходный код. Это зависит от бизнес-стратегии компании. Например, Meta (ранее Facebook) очень четко понимает, почему она выбрала открытый исходный код. Их текущая бизнес-модель заключается не в получении прибыли за счет моделей продаж, а в развитии экосистемы с использованием этих моделей и привлечении большего количества людей к использованию их платформы. Поэтому открытый исходный код имеет для них большой смысл. А для некоторых других компаний, которые действительно зарабатывают деньги на этих технологиях, можно рассмотреть комбинацию открытого исходного кода и закрытого исходного кода, работающих слоями. Поэтому я открыт для этих подходов.
▲ Модель Meta с открытым исходным кодом llama находится в рейтинге моделей больших языков с открытым исходным кодом Hugging Face
На более высоком уровне, я думаю, что открытый исходный код должен быть защищен, будь то в государственном секторе, например, в академической среде, или в частном секторе, если есть усилия по открытому исходному коду, это очень важно. Это критически важно для экосистемы стартапов, и это очень важно для государственного сектора. Я думаю, что эти усилия должны быть защищены и не должны игнорироваться.
Опрашивающий 5: Здравствуйте, меня зовут Карл, я из Эстонии, и у меня есть вопрос о данных. Вы упомянули изменение в машинном обучении из-за подходов, основанных на данных, особенно прогресс, достигнутый в ImageNet, и теперь вы изучаете мировые модели, и вы упомянули, что нам не хватает пространственных данных, которых нет в Интернете, только в наших мозгах. Как вы решаете эту проблему? Каково направление ваших исследований? Вы собираете данные из реального мира или генерируете синтетические данные? Вы верите в синтетические данные? Или вы больше верите в традиционные априорные знания? Спасибо.
Фэй-Фэй Ли: Вы должны присоединиться ко мне в World Labs, и я вам расскажу. Как компания, я не могу поделиться слишком многим, но я думаю, важно признать, что мы используем гибридный подход. Очень важно иметь много данных, но не менее важно иметь высококачественные данные. В конце концов, если вы не обращаете внимания на качество данных, конечный результат — мусор на входе, мусор на выходе.
Опрашивающий 6: Здравствуйте, доктор Фэй-Фэй Ли, меня зовут Энни, большое спасибо за беседу с нами. В вашей книге «Мир» я видела, что вы говорили о трудностях жизни иммигранток и женщин в областях STEM. Я бы хотела узнать, чувствовали ли вы когда-нибудь себя меньшинством на рабочем месте? Если да, то как вы преодолели эту дилемму или убедили других?

Фэй-Фэй Ли: Спасибо за вопрос. Я буду осторожен и вдумчив в ответе, потому что у каждого из нас разное прошлое и у каждого из нас очень уникальный опыт. Знаете, это почти не имеет значения. У всех нас бывают моменты, когда мы чувствуем себя в меньшинстве или единственным человеком в комнате. Так что, конечно, у меня были такие чувства.
Иногда это о том, кто я, иногда о том, как я думаю, иногда это просто цвет одежды, которую я ношу, всегда есть причина. Но я хочу поддержать вас в этом отношении. Может быть, это потому, что я приехала в эту страну в молодом возрасте, и у меня был некоторый опыт. Я приняла то, что я иммигрантка. Я почти развила способность не воспринимать это слишком серьезно. Я здесь, как и каждый из вас. Я здесь, чтобы учиться, делать, создавать вещи.
Я действительно хочу сказать каждому из вас, вы собираетесь что-то начать или уже в процессе что-то сделать, у вас будут моменты слабости или замешательства, я чувствую это каждый день, особенно в предпринимательской жизни. Иногда я думаю, о боже, я не знаю, что я делаю. Не беспокойтесь об этом, просто сосредоточьтесь на том, чтобы это сделать. Так же, как градиентный спуск, двигайтесь шаг за шагом к оптимальному решению.
#Добро пожаловать на официальный публичный аккаунт WeChat iFanr: iFanr (WeChat ID: ifanr), где вам будет представлен еще более интересный контент как можно скорее.
iFanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo