Самый дорогой талант в Соединенных Штатах сейчас — китайский талант в области искусственного интеллекта: Университет Цинхуа, Пекинский университет и Китайская академия наук «доминируют» в сфере искусственного интеллекта в Кремниевой долине

За последние две недели самой популярной вещью в индустрии ИИ стал не продукт, а люди. Часто, когда я просыпаюсь, моя лента в социальных сетях обновляется одной и той же старой новостью: переманили еще одного эксперта по ИИ.
Лучшие специалисты в области ИИ становятся самым дефицитным и наиболее эффективным для бренда активом в сфере ИИ.
В центре этого потока талантов мы обнаружили особенно поразительную деталь: среди основных членов, которые руководили исследованиями и разработками крупных моделей, таких как ChatGPT, Gemini и Claude, доля китайских ученых оказалась на удивление высокой.
Это изменение не произошло внезапно. В волне ИИ, которая возникла в последние годы, доля китайских ведущих специалистов по ИИ в Соединенных Штатах продолжала расти. Согласно отчету Global Artificial Intelligence Talent Tracking Survey Report 2.0, опубликованному MacroPolo, доля ведущих исследователей ИИ из Китая увеличилась с 29% до 47% в период с 2019 по 2022 год.
В «Отчете об исследовании команды ChatGPT», опубликованном Zhipu Research, было обнаружено, что среди 87 основных членов команды ChatGPT 9 являются китайцами, что составляет более 10%. Поэтому мы также пересмотрели портреты китайских исследователей ИИ, которые в последнее время привлекли большое внимание в ведущих компаниях Кремниевой долины, и попытались обобщить некоторые их характеристики:
1️⃣ Окончили лучшие университеты, с сильными академическими способностями. Большинство из них изучали курсы бакалавриата в лучших университетах, таких как Университет Цинхуа, Пекинский университет, Китайский университет науки и технологий, Чжэцзянский университет, и у большинства из них есть опыт в области компьютерных наук или математики. Для получения степени магистра они обычно идут в MIT, Стэнфорд, Беркли, Принстон, UIUC и другие известные университеты. Почти у каждого есть высоко цитируемые статьи на ведущих конференциях (NeurIPS, ICLR, SIGGRAPH и т. д.).
2️⃣ Молодые и продуктивные, период вспышки приходится на период после 2020 года, а возраст в основном составляет 30-35 лет; этапы магистратуры и докторантуры совпадают с глобальной вспышкой глубокого обучения, с прочной академической базой и знакомством с инженерными системами и командной работой. Первой остановкой карьеры многих людей является контакт с продуктами или платформами ИИ крупных компаний или обслуживание больших групп людей, с более высокой отправной точкой и более быстрым темпом.
3️⃣ Сильный мультимодальный бэкграунд после обучения модели. Их исследовательское направление, как правило, сосредоточено на единой системе рассуждений в модальностях (текст, речь, изображение, видео, действие), включая конкретные детали, такие как RLHF, дистилляция, выравнивание, моделирование человеческих предпочтений и оценка интонации речи.
4️⃣ Даже если он часто перемещается, он по сути не будет выпадать из экосистемы
Google, Meta, Microsoft, Nvidia, Anthropic, OpenAI… Их мобильность охватывает стартапы и гигантов в области ИИ, но темы их исследований и накопленные технологии, как правило, остаются неизменными, и они, по сути, не меняют своих направлений.
OpenAI → Мета
Шучао Би
Шучао Би окончил математический факультет Чжэцзянского университета, а затем продолжил обучение в Калифорнийском университете в Беркли, где получил степень магистра статистики и докторскую степень по математике.
С 2013 по 2019 год он занимал должность технического директора в Google, где его основным вкладом было создание многоступенчатой системы рекомендаций на основе глубокого обучения, которая значительно увеличила доходы Google от рекламы (исчисляемые миллиардами долларов).
С 2019 по 2024 год он занимал должность руководителя Shorts Exploration, в течение которого он был одним из создателей и руководителем системы рекомендаций и поиска видео Shorts, а также создал и расширил крупномасштабную команду машинного обучения, охватывающую системы рекомендаций, модели оценки, интерактивный поиск, доверие и безопасность и другие области.
Присоединившись к OpenAI в 2024 году, он в основном руководил организацией мультимодального постобучения и является одним из создателей речевой модели GPT-4o и o4-mini.
В этот период он в основном продвигал RLHF, рассуждения по изображению/речи/видео/тексту, мультимодальных агентов, мультимодальную речь в речь (VS2S), базовую модель зрение-язык-действие (VLA), кросс-модальную систему оценки и т. д., а также занимался мультимодальным цепным рассуждением, оценкой интонации/естественности речи, мультимодальной дистилляцией и самоконтролируемой оптимизацией. Его основная цель — построить более общего мультимодального агента ИИ с помощью пост-обучения.
Хуэйвэнь Чанг
В 2013 году Хуэйвэнь Чанг окончил факультет компьютерных наук (класс Яо) Университета Цинхуа, а затем отправился в Принстонский университет в США, чтобы получить степень доктора наук в области компьютерных наук. Его исследования сосредоточены на передаче стиля изображения, генеративных моделях и обработке изображений. Он выиграл стипендию от Microsoft Research.
До прихода в OpenAI она работала старшим научным сотрудником в Google более шести лет и долгое время занималась исследованиями в области генеративных моделей и компьютерного зрения. Она изобрела архитектуры преобразования текста в изображение MaskGIT и Muse в Google Research.
Ранняя генерация текста в изображение в основном опиралась на модели диффузии (такие как DALL·E 2 и Imagen). Хотя эти модели имеют высокое качество генерации, они имеют медленную скорость вывода и высокую стоимость обучения. MaskGIT и Muse, с другой стороны, используют подход «дискретизация + параллельная генерация», что значительно повышает эффективность.

MaskGIT — это новая отправная точка для неавторегрессивной генерации изображений, а Muse — это репрезентативная работа, которая продвигает этот метод к генерации текстовых изображений. Они не так известны, как Stable Diffusion, но являются очень важными техническими краеугольными камнями в академических и инженерных системах.
Кроме того, она также является одним из соавторов ведущей статьи по диффузионной модели «Палитра: модели диффузии от изображения к изображению».
Эта статья была опубликована на SIGGRAPH 2022. Она предложила унифицированную структуру перевода изображения в изображение и превзошла базовые показатели GAN и регрессии в нескольких задачах, таких как восстановление изображений, раскрашивание и завершение. На сегодняшний день она была процитирована более 1700 раз и стала одним из репрезентативных достижений в этой области.
С июня 2023 года она присоединилась к мультимодальной команде OpenAI и стала соавтором функции генерации изображений GPT-4o, продолжая содействовать исследованиям и внедрению в таких передовых направлениях, как генерация изображений и мультимодальное моделирование.

Цзи Линь
Цзи Линь в основном занимается исследованиями в области мультимодального обучения, систем рассуждений и синтетических данных. Он является участником нескольких основных моделей, включая GPT-4o, GPT-4.1, GPT-4.5, o3/o4-mini, Operator и модель генерации изображений 4o.
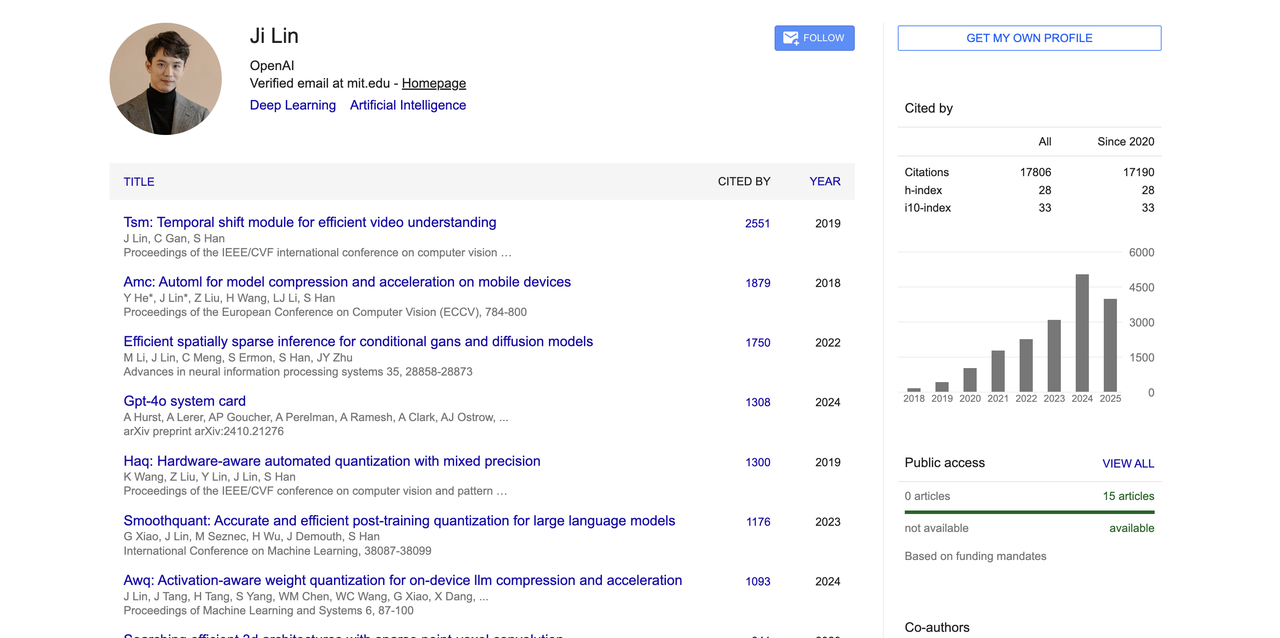
Он окончил Университет Цинхуа, получив степень бакалавра в области электронной инженерии (2014–2018 гг.), а также получил докторскую степень в области электротехники и компьютерных наук в Массачусетском технологическом институте под руководством известного ученого профессора Сон Ханя.
Во время обучения в докторантуре его исследования были сосредоточены на таких ключевых областях, как сжатие моделей, квантизация, модели визуального языка и разреженные рассуждения.
До прихода в OpenAI в 2023 году он работал стажером-исследователем в NVIDIA, Adobe и Google, а также долгое время занимался исследованиями в области сжатия нейронных сетей и ускорения вывода в Массачусетском технологическом институте, накопив глубокую теоретическую базу и опыт инженерной практики.
В академической сфере он опубликовал множество высокоэффективных статей в области сжатия моделей, квантования и многомодального предварительного обучения с общим цитированием более 17 800 на Google Scholar. Его репрезентативные достижения включают модель понимания видео TSM, аппаратно-ориентированный метод квантования AWQ, SmoothQuant и модель визуального языка VILA.
Он также является одним из основных авторов технической документации системы GPT-4o (например, системной карты GPT-4o) и получил премию MLSys 2024 за лучшую статью в AWQ.
Хунъю Рен
Хонгюй Рен получил степень бакалавра в области компьютерных наук и технологий в Пекинском университете (2014–2018) и докторскую степень в области компьютерных наук в Стэнфордском университете (2018–2023).
Он получил несколько стипендий, включая стипендию PhD от Apple, Baidu и SoftBank Masason Foundation. Его исследования сосредоточены на больших языковых моделях, рассуждениях графа знаний, мультимодальном интеллекте и базовой оценке моделей.
До прихода в OpenAI он прошел множество стажировок в Google, Microsoft и NVIDIA. Например, работая стажером-исследователем в Apple в 2021 году, он участвовал в создании системы вопросов и ответов Siri.
Присоединившись к OpenAI в июле 2023 года, Хонгюй Рен принял участие в создании нескольких основных моделей, таких как GPT-4o, 4o-mini, o1-mini, o3-mini, o3 и o4-mini, а также возглавил команду по постобучению.
По его словам: «Я учу моделей думать быстрее, сильнее и острее».
В академической сфере его общее количество цитирований в Google Scholar превышает 17 742 раза, а его наиболее цитируемые статьи включают: «О возможностях и рисках фундаментальных моделей» (цитируется 6 127 раз); набор данных «Open Graph Benchmark» (OGB) (цитируется 3 524 раза) и т. д.
Цзяхуэй Юй
Цзяхуэй Юй окончил младший курс Китайского университета науки и технологий, получив степень бакалавра в области компьютерных наук, а затем получил докторскую степень в области компьютерных наук в Иллинойсском университете в Урбане-Шампейне (UIUC).
Его научные интересы охватывают глубокое обучение, генерацию изображений, архитектуры больших моделей, многомодальные рассуждения и высокопроизводительные вычисления.

Во время своей работы в OpenAI Цзяхуэй Юй занимал должность руководителя группы восприятия, руководил разработкой важных проектов, таких как модуль генерации изображений GPT-4o, GPT-4.1, o3/o4-mini, а также предложил и реализовал систему восприятия «Думай образами».
До этого он работал в Google DeepMind почти четыре года, в течение которых он был одним из основных участников архитектуры и моделирования PaLM-2, а также был одним из руководителей разработки мультимодальной модели Gemini. Он является одним из важнейших технических хребтов в мультимодальной стратегии Google.
Он также имеет опыт стажировки во многих учреждениях, включая NVIDIA, Adobe, Baidu, Snap, Megvii и Microsoft Research Asia. Его исследования охватывают GAN, обнаружение объектов, автономное вождение, сжатие моделей, восстановление изображений и крупномасштабные системы обучения глубокому обучению.
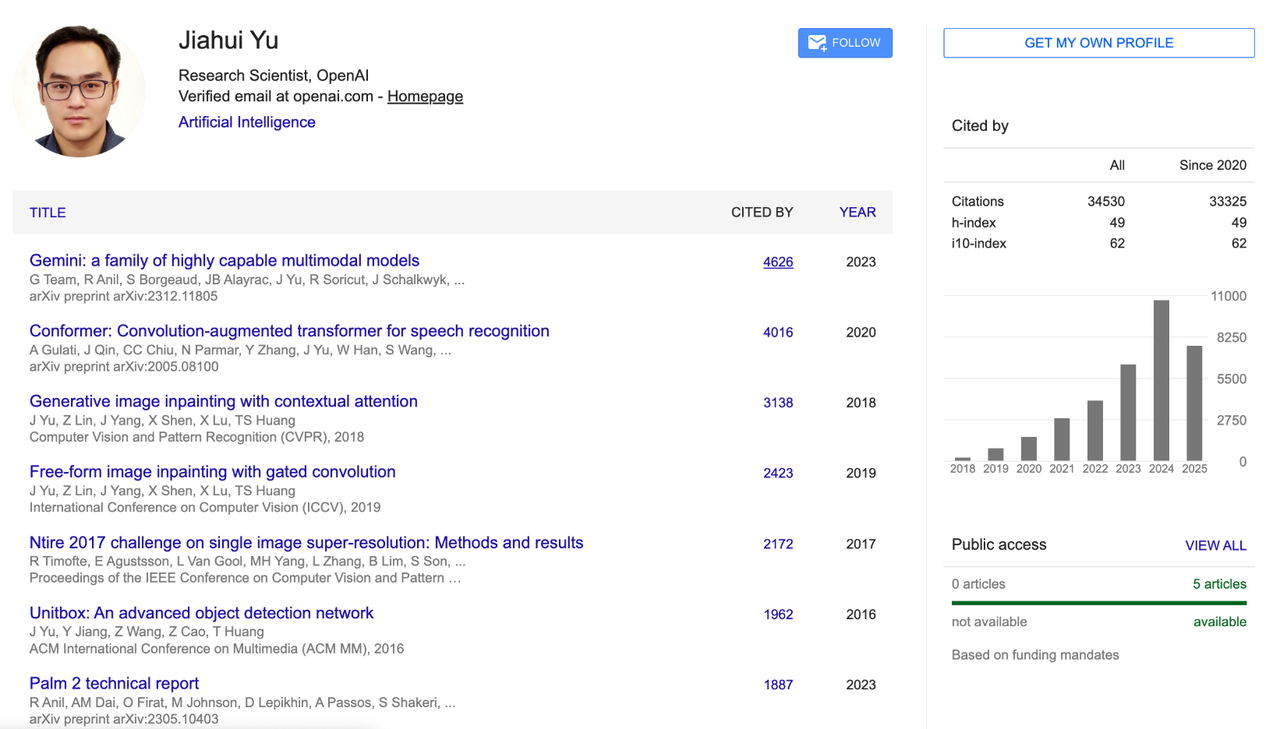
Цзяхуэй был процитирован более 34 500 раз в Google Scholar, его индекс Хирша составил 49. Результаты его репрезентативных исследований включают базовую модель CoCa для выравнивания изображения и текста, модель генерации текста в изображение Parti, масштабируемую нейронную сеть BigNAS и технологию восстановления изображений DeepFill v1 и v2, которые широко используются в Adobe Photoshop.
Шэнцзя Чжао
Шэнцзя Чжао окончил факультет компьютерных наук в Университете Цинхуа. Он был студентом по обмену в Университете Райса в США, а затем получил докторскую степень в области компьютерных наук в Стэнфордском университете. Он сосредоточился на исследованиях в области архитектуры больших моделей, многомодальных рассуждений и выравнивания.
В 2022 году он присоединился к OpenAI в качестве основного члена R&D и был глубоко вовлечен в проектирование системы GPT-4 и GPT-4o. Он руководил R&D ChatGPT, GPT-4, всех мини-моделей, 4.1 и o3, а также руководил командой синтетических данных OpenAI.
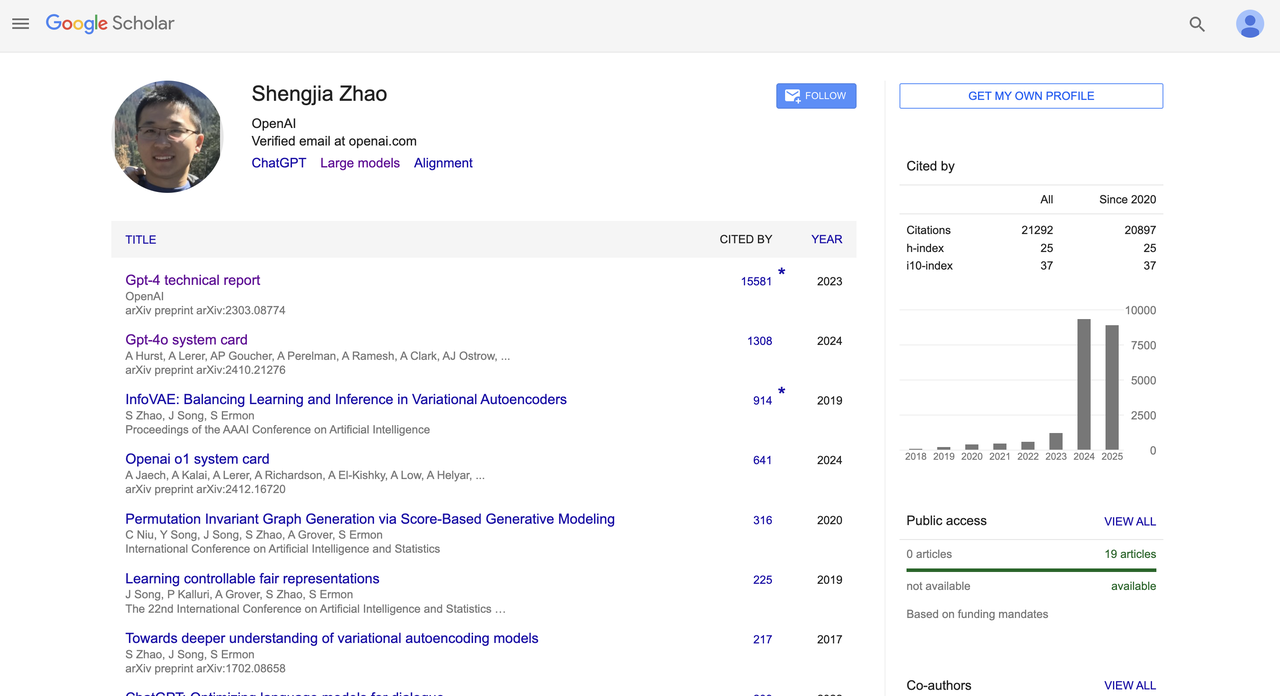
Он является соавтором «Технического отчета GPT-4» (цитируется более 15 000 раз) и «Системной карты GPT-4o» (цитируется более 1300 раз), а также участвовал в написании нескольких системных карт (таких как OpenAI o1). Он является одним из важных участников стандартизации и открытости базовых моделей OpenAI.
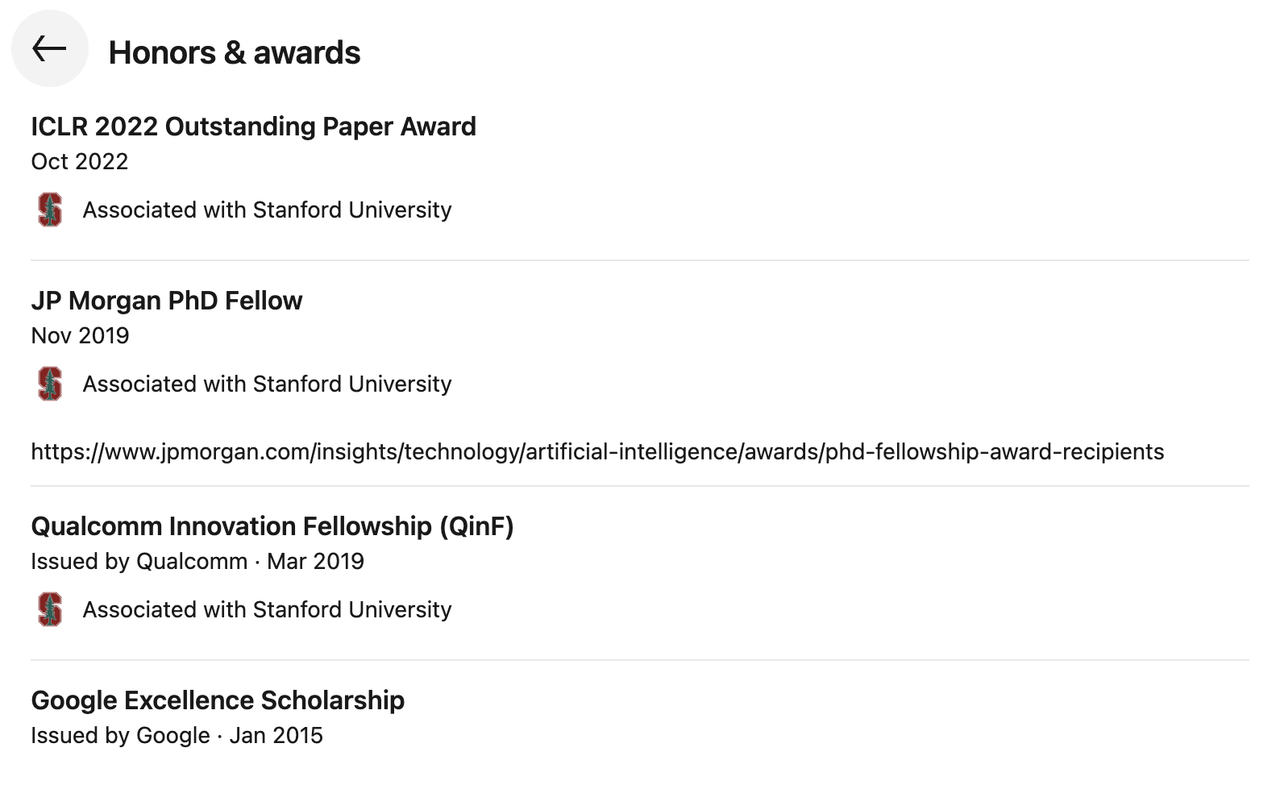
Что касается академической успеваемости, то на его счету более 21 000 цитат в Google Scholar и индекс Хирша 25. Он получил множество наград, включая премию ICLR 2022 Outstanding Paper Award, стипендию JP Morgan PhD Fellowship, стипендию Qualcomm Innovation Fellowship (QinF) и стипендию Google Excellence Scholarship.
Google → Мета
Пей Сан
В 2009 году Пей Сан получила степень бакалавра в Университете Цинхуа, а затем поступила в Университет Карнеги-Меллона, чтобы получить степень магистра и доктора наук. Она успешно закончила магистратуру и решила бросить учебу на этапе докторантуры.
Он занимал должность главного исследователя в Google DeepMind, где он сосредоточился на пост-обучении, программировании и рассуждениях модели Gemini. Он является одним из основных участников пост-обучения, построения механизма мышления и реализации кода серии моделей Gemini (включая Gemini 1, 1.5, 2 и 2.5).
До прихода в DeepMind Пей почти семь лет проработал в Waymo старшим научным сотрудником, руководя разработкой двух поколений основных моделей восприятия Waymo и играя ключевую роль в развитии систем восприятия автономного вождения.
Ранее он более пяти лет проработал инженером-программистом в Google, а затем более года проработал инженером в компании Alluxio, занимающейся распределенными хранилищами данных, участвуя в исследованиях и разработках архитектуры систем.

Nexusflow → NVIDIA
Банхуа Чжу
Банхуа Чжу окончил факультет электронной инженерии в Университете Цинхуа, а затем поступил в Калифорнийский университет в Беркли, чтобы получить докторскую степень в области электротехники и компьютерных наук под руководством известных ученых Майкла И. Джордана и Цзяньтао Цзяо.

Его исследования сосредоточены на повышении эффективности и безопасности базовых моделей, интеграции статистических методов с теорией машинного обучения, и он стремится создавать наборы данных с открытым исходным кодом и общедоступные инструменты. Его интересы также включают теорию игр, обучение с подкреплением, взаимодействие человека и компьютера и проектирование систем машинного обучения.
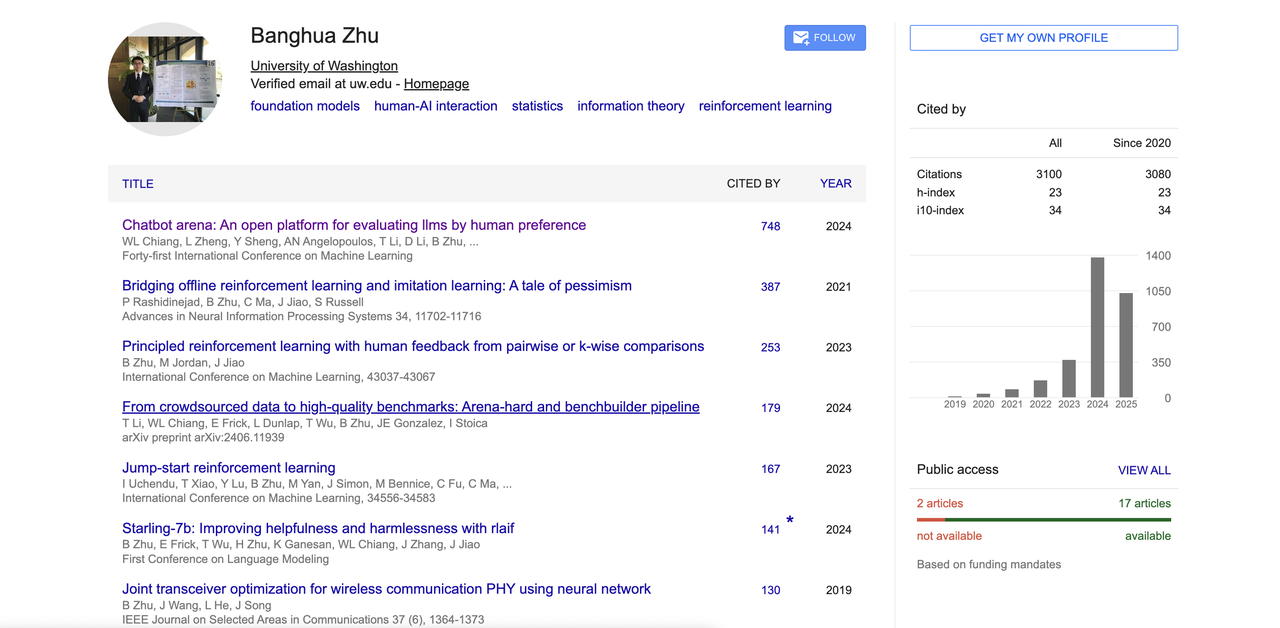
В своей репрезентативной работе «Chatbot Arena» он предложил большую платформу оценки моделей, основанную на предпочтениях человека, которая стала одним из важных ориентиров в области LLM.
Кроме того, он внес вклад в RLHF, выравнивание обратной связи с человеком, модели выравнивания с открытым исходным кодом и т. д. Его Google Scholar показывает, что общее количество цитирований превышает 3100, а индекс Хирша равен 23. Он также является одним из основных авторов многих популярных проектов с открытым исходным кодом, таких как арена больших моделей «Chatbot Arena», «Benchbuilder» и «Starling».

Он работал стажером-исследователем в Microsoft и студентом-исследователем в Google. Он стал одним из основателей стартапа ИИ Nexusflow. В июне этого года он объявил, что присоединился к команде Star Nemotron компании NVIDIA в качестве главного научного сотрудника. Кроме того, этой осенью он присоединится к Вашингтонскому университету в качестве доцента.
Согласно пресс-релизу, он примет участие в таких проектах, как постмодельное обучение, оценка, инфраструктура ИИ и создание интеллектуальных агентов в NVIDIA, делая упор на тесное сотрудничество с разработчиками и научным сообществом, а также планирует открыть исходный код соответствующих результатов.
Цзянтао Цзяо
Цзяньтао Цзяо — доцент кафедры электротехники, компьютерных наук и статистики Калифорнийского университета в Беркли.
Он получил докторскую степень по электротехнике в Стэнфордском университете в 2018 году и в настоящее время является содиректором или членом нескольких исследовательских центров, включая Центр теоретического обучения в Беркли (CLIMB), Исследовательский центр искусственного интеллекта в Беркли (BAIR Lab), Лабораторию информационных и системных наук (BLISS) и Центр децентрализованного интеллекта (RDI).
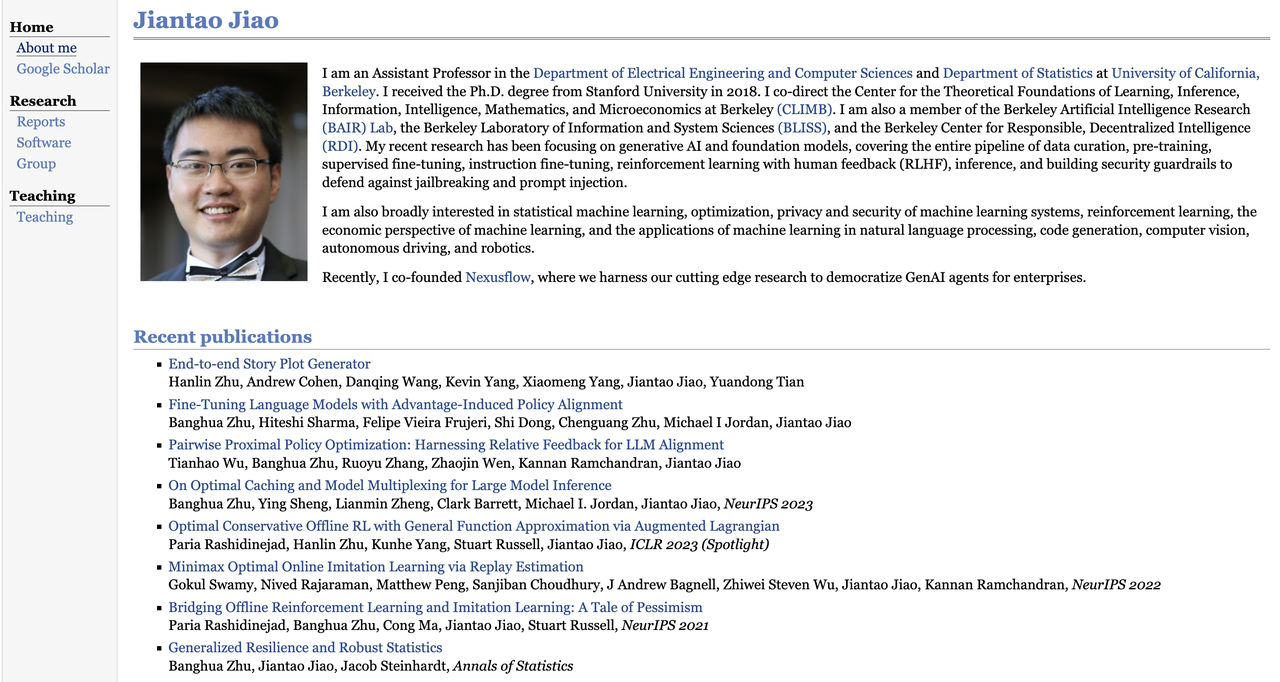
Его исследования сосредоточены на генеративном ИИ и базовых моделях. Он также интересуется статистическим машинным обучением, теорией оптимизации, конфиденциальностью и безопасностью систем обучения с подкреплением, проектированием экономических механизмов, обработкой естественного языка, генерацией кода, компьютерным зрением, автономным вождением и робототехникой.
Как и Банхуа Чжу, он также является одним из соучредителей Nexusflow и теперь официально присоединился к NVIDIA в качестве директора по исследованиям и выдающегося ученого.
У Цзяо в общей сложности 7259 цитирований и индекс Хирша 34. Среди его репрезентативных статей — «Теоретически принципиальный компромисс между надежностью и точностью» и «Сближение офлайн-обучения с подкреплением и имитационного обучения: история пессимизма», написанная в соавторстве с Банхуа Чжу и др. Обе статьи были опубликованы на ведущих конференциях, таких как NeurIPS.
Клод → Курсор
Кэтрин Ву
Кэтрин Ву работала менеджером по продукту в Claude Code в Anthropic, сосредоточившись на создании надежных, объяснимых и контролируемых систем ИИ. По данным The Information, Кэтрин Ву переманила Cursor, стартап по программированию ИИ, на должность менеджера по продукту.

До прихода в Anthropic она была партнером в известной венчурной компании Index Ventures, где проработала почти три года. За это время она активно занималась ранними инвестициями и стратегической поддержкой многих ведущих стартапов.
Ее карьера началась не в инвестиционном секторе, а на передовых технических должностях.
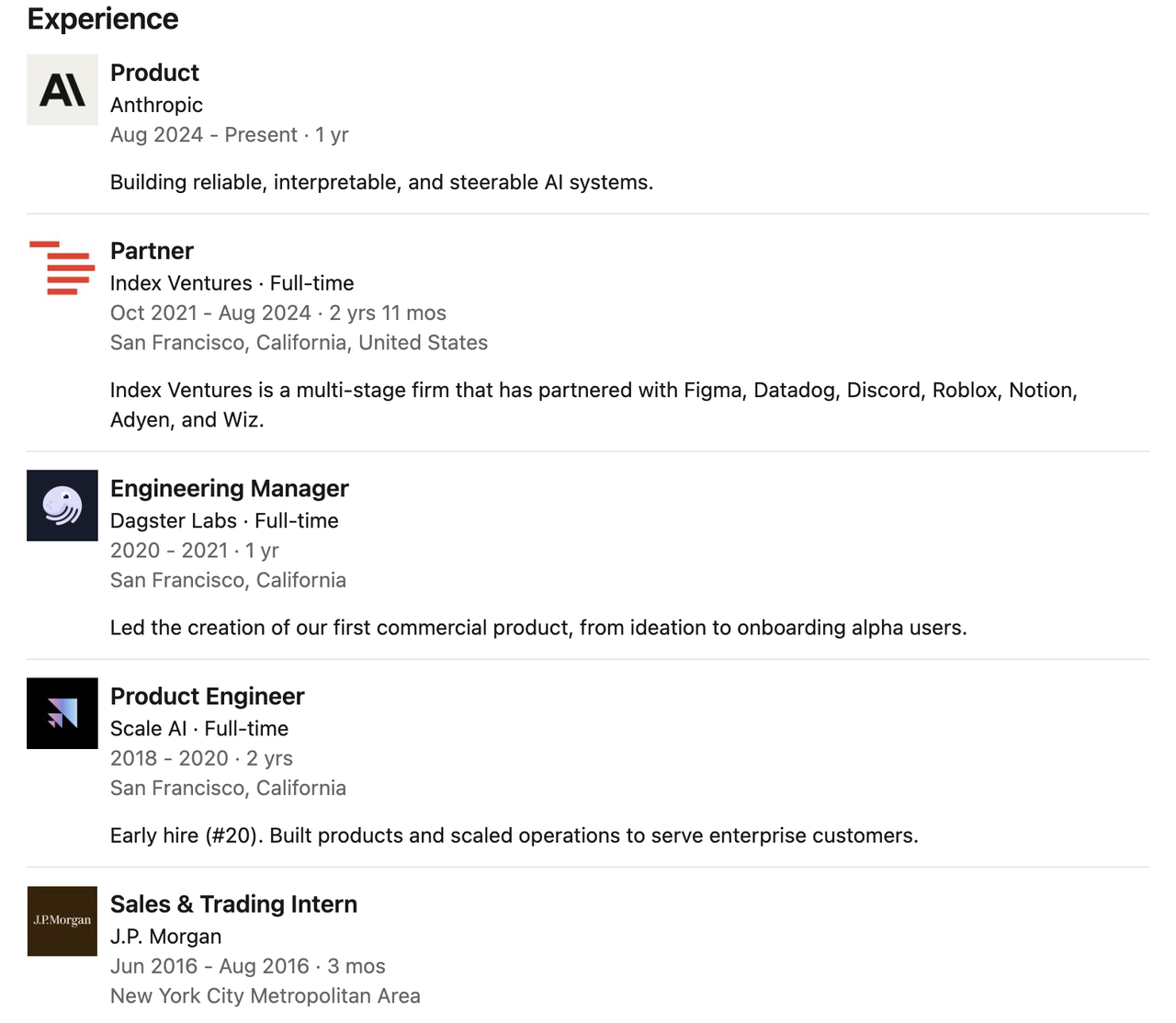
Ранее она работала менеджером по инжинирингу в Dagster Labs, руководя разработкой первого коммерческого продукта компании, а также инженером по ранним продуктам в Scale AI, участвуя в разработке и расширении эксплуатации нескольких ключевых продуктов.
Ранее она проходила стажировку в JPMorgan Chase и получила степень бакалавра в области компьютерных наук в Принстонском университете. Во время учебы она также ездила в Швейцарский федеральный технологический институт по программе обмена.
Тесла | Фил Дуан
Фил Дуан — главный инженер-программист Tesla AI. В настоящее время он возглавляет команду Fleet Learning в Autopilot и занимается продвижением разработки основного модуля «данные + восприятие» в системе автономного вождения Tesla (FSD).

Он руководил командой Tesla, которая разработала высокопроизводительный, быстроитерационный движок данных, который собирает, обрабатывает и автоматически аннотирует данные о вождении миллионов автомобилей, подчеркивая скоординированную оптимизацию качества, количества и разнообразия данных. В области восприятия он руководил созданием ряда ключевых нейронных сетей, включая базовые визуальные модели, обнаружение целей, прогнозирование поведения, сети занятости, управление дорожным движением и высокоточные системы помощи при парковке, и является одним из основных разработчиков системы восприятия Autopilot.
Он окончил Уханьский технологический университет со степенью бакалавра в области оптической информационной науки и технологий, а затем получил докторскую степень и степень магистра в области электротехники в Университете Огайо, сосредоточившись на авионике. За свою докторскую диссертацию он получил премию RTCA William E. Jackson Award 2019, которая является одной из самых высоких наград, присуждаемых аспирантам в области авионики и телекоммуникаций в Соединенных Штатах.
#Добро пожаловать на официальный публичный аккаунт WeChat iFanr: iFanr (WeChat ID: ifanr), где вам будет представлен еще более интересный контент как можно скорее.
iFanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo