Самый большой скандал в сфере ИИ в этом году разоблачен! «Лама 4» была уличена в жульничестве на тренировках, провалилась на реальных испытаниях, и основной персонал в гневе уволился.

Вчера совершенно неожиданно вышла Meta Llama 4.
Параметры на бумаге очень высокие. Говорят, что это собственная мультимодальная модель MOE, превосходящая DeepSeek V3 и имеющая 2 триллиона параметров. Даже генеральный директор Meta Цукерберг опубликовал видео, в котором размахивает флагом и кричит, приветствуя «Ламу 4-го».
Приветствия были недолгими. Когда пользователи сети начали тестирование, они получили почти исключительно негативные отзывы. Его можно назвать самым масштабным событием в сфере искусственного интеллекта в этом году.
В сообществе r/LocalLLaMA (которое можно понимать как «панель сообщений» Llama), посвященном локальному развертыванию больших языковых моделей, пост под названием «Я невероятно разочарован Llama 4» быстро завоевал много внимания и резонанса.
Есть даже преданные поклонники Llama, которые сломали оборону и прямо заявили, что пора переименовать «LocalLLaMA» в «LocalGemma». Высмеивание выхода Llama 4 больше похоже на запоздалую первоапрельскую шутку.

Фактический тест показал, что товары были неправильными, и выяснилось, что Llama 4 без ума от «задания вопросов» перед выпуском.
В этом оригинальном посте на Reddit пользователь сети Кармински настоятельно не советует использовать Llama 4 для кодирования.
Он заявил, что Llama-4-Maverick — модель с общим параметром 402В — едва ли может сравниться с Qwen-QwQ-32B по возможностям кодирования. По своим характеристикам «Лама-4-Скаут» (модель с общими параметрами 109Б) примерно аналогичен «Грок-2» или «Эрни 4,5».
Фактически, согласно последним результатам теста кодирования Aider Polyglot, Llama 4 Maverick набрал всего 16%.
Этот тест предназначен для оценки производительности больших языковых моделей (LLM) в задачах многоязычного программирования, охватывающих шесть основных языков программирования: C++, Go, Java, JavaScript, Python и Rust.
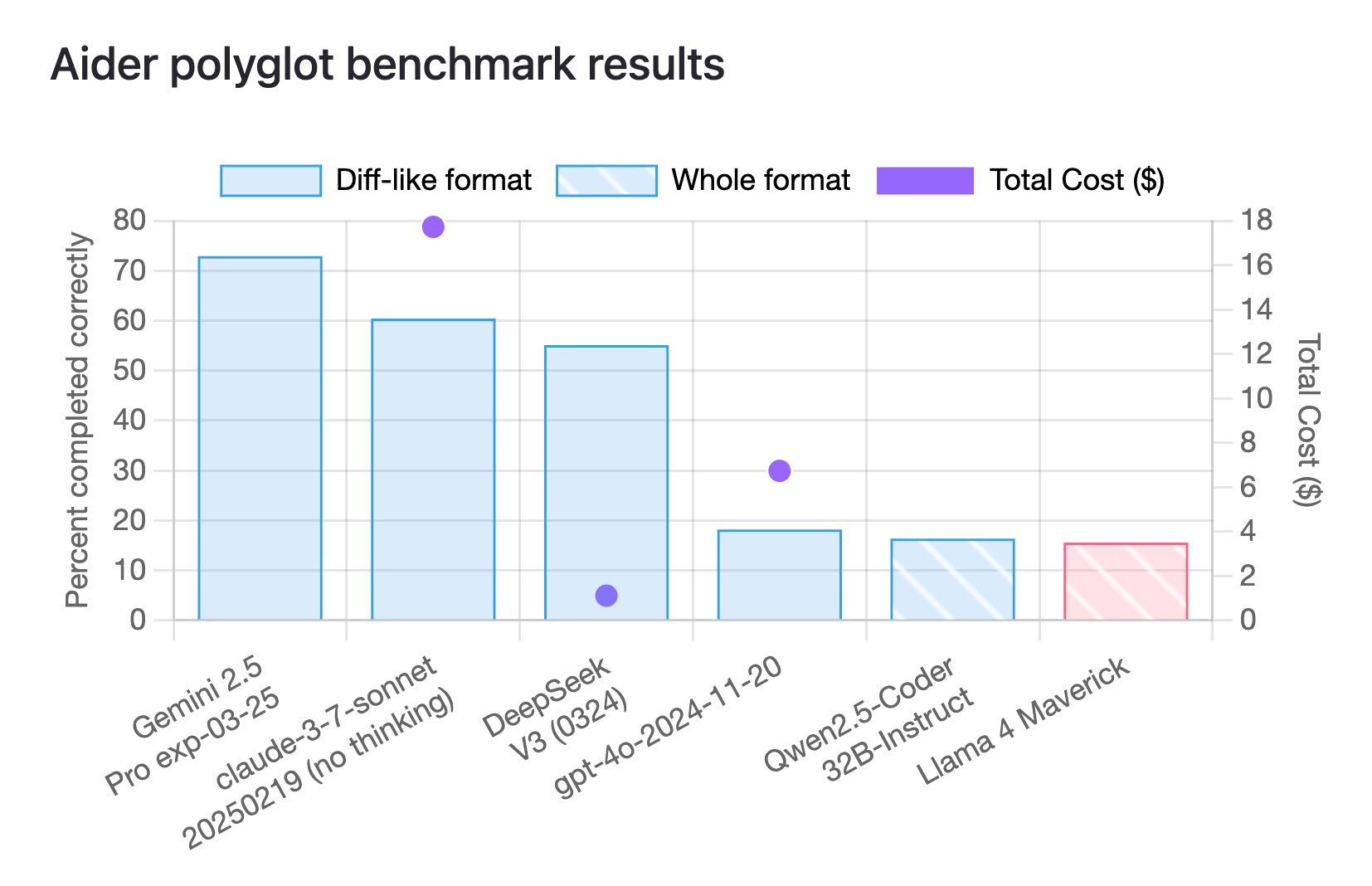
И этот показатель также находится на нижнем уровне среди многих моделей.
Блогер @deedydas также выразил разочарование по поводу Llama 4, назвав ее «ужасной моделью программирования».
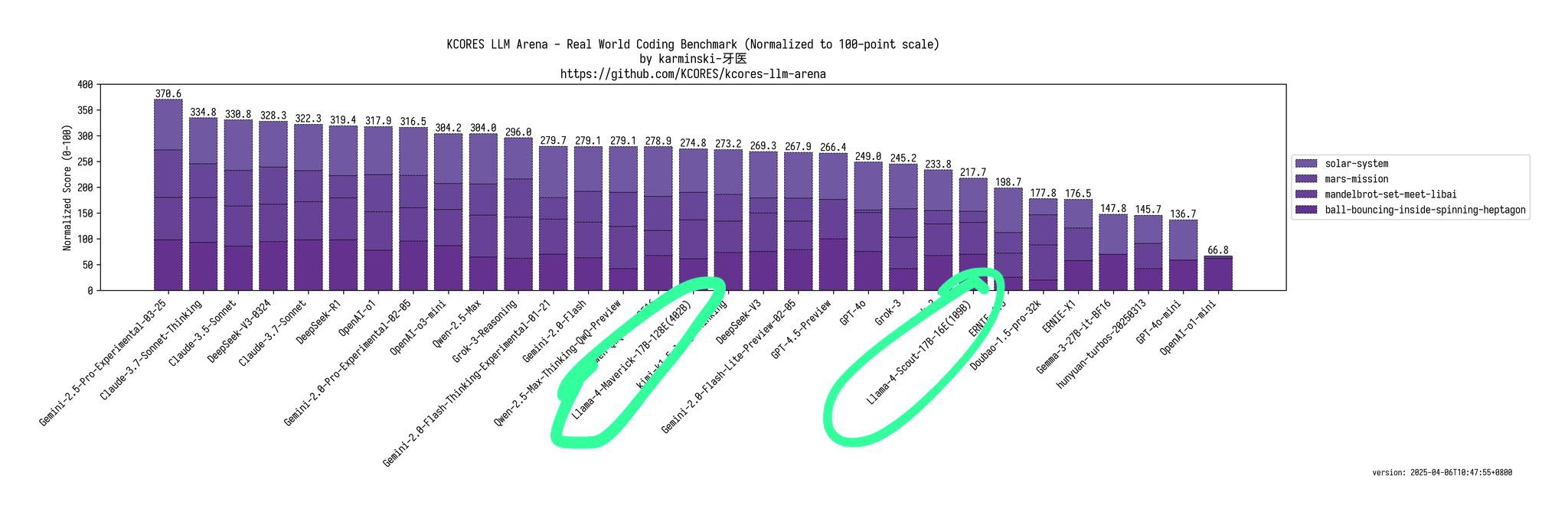
Он отметил, что Scout (109B) и Maverick (402B) работают намного хуже, чем 4o, Gemini Flash, Grok 3, DeepSeek V3 и Sonnet 3.5/7 в тесте производительности Kscores для задач программирования.
Другой пользователь сети, Флавио Адамо, попросил Llama 4 Maverick и GPT-4o создать анимацию маленького шарика, подпрыгивающего во вращающемся многоугольнике, при этом мяч должен следовать влиянию силы тяжести и трения во время процесса прыжка.
Результаты показывают, что в многоугольной форме, созданной Llama 4 Maverick, отсутствуют отверстия, а движение шара также нарушает законы физики. Для сравнения, производительность новой версии GPT-4o значительно лучше, а производительность Gemini 2.5 Pro — король.

Вспоминая в январе этого года, Цукерберг также заявил, что ИИ достигнет уровня программирования среднего инженера-программиста. Нынешняя плохая производительность Llama 4 — это действительно пощечина.
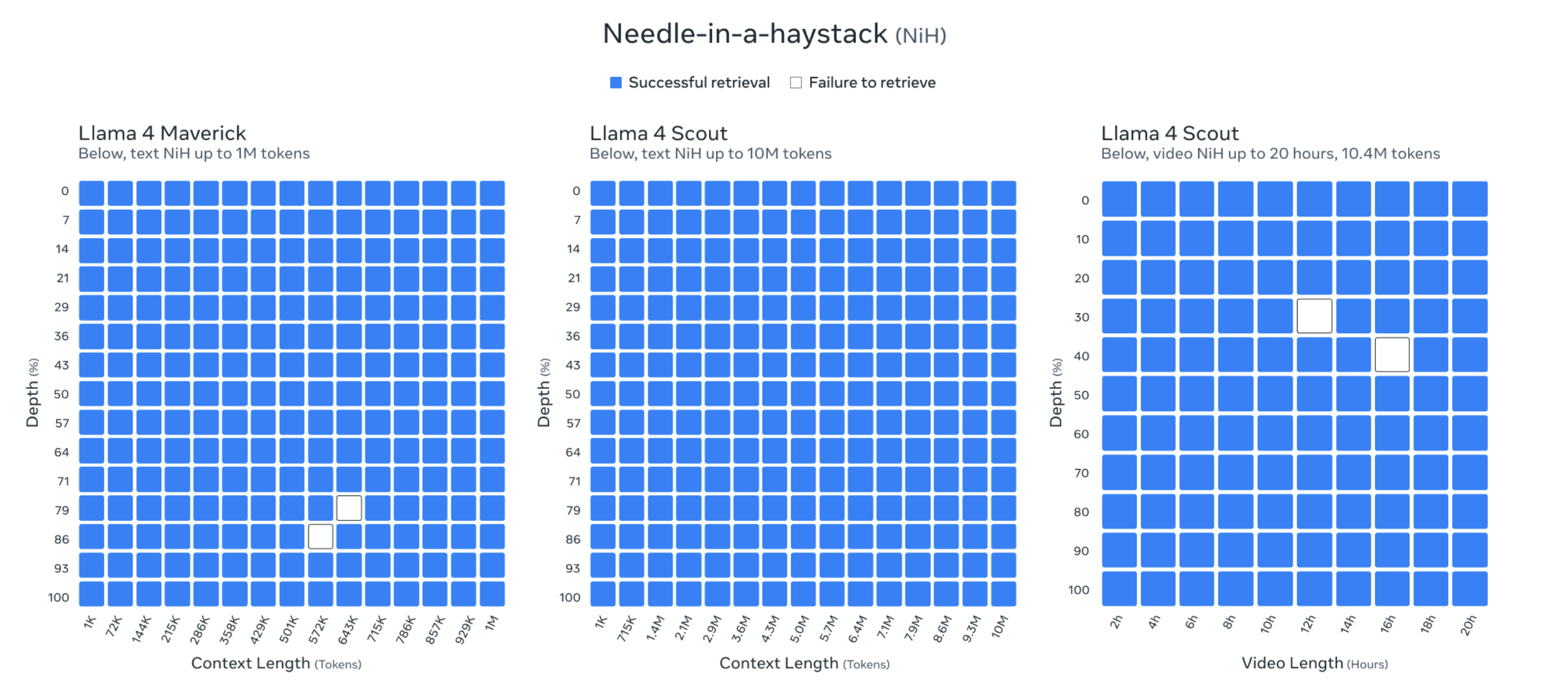
Кроме того, длина контекста Llama 4 Scout достигает 10 миллионов токенов. Такая чрезвычайно большая длина контекста позволяет Llama 4 Scout обрабатывать и анализировать чрезвычайно длинный текстовый контент, например, целые книги, большие библиотеки кода или мультимедийные архивы.
Представители Мета даже продемонстрировали результаты испытаний на «поиск иголки в стоге сена», чтобы доказать свои возможности.
Однако, согласно последним результатам Fiction.LiveBench, эффект модели Llama 4 также посредственный и бесполезный, а общий эффект не так хорош, как у Gemini 2.0 Flash, тогда как Gemini 2.5 Pro по-прежнему остается заслуженным королем длинного текста.
+1 для Оиты в Google.
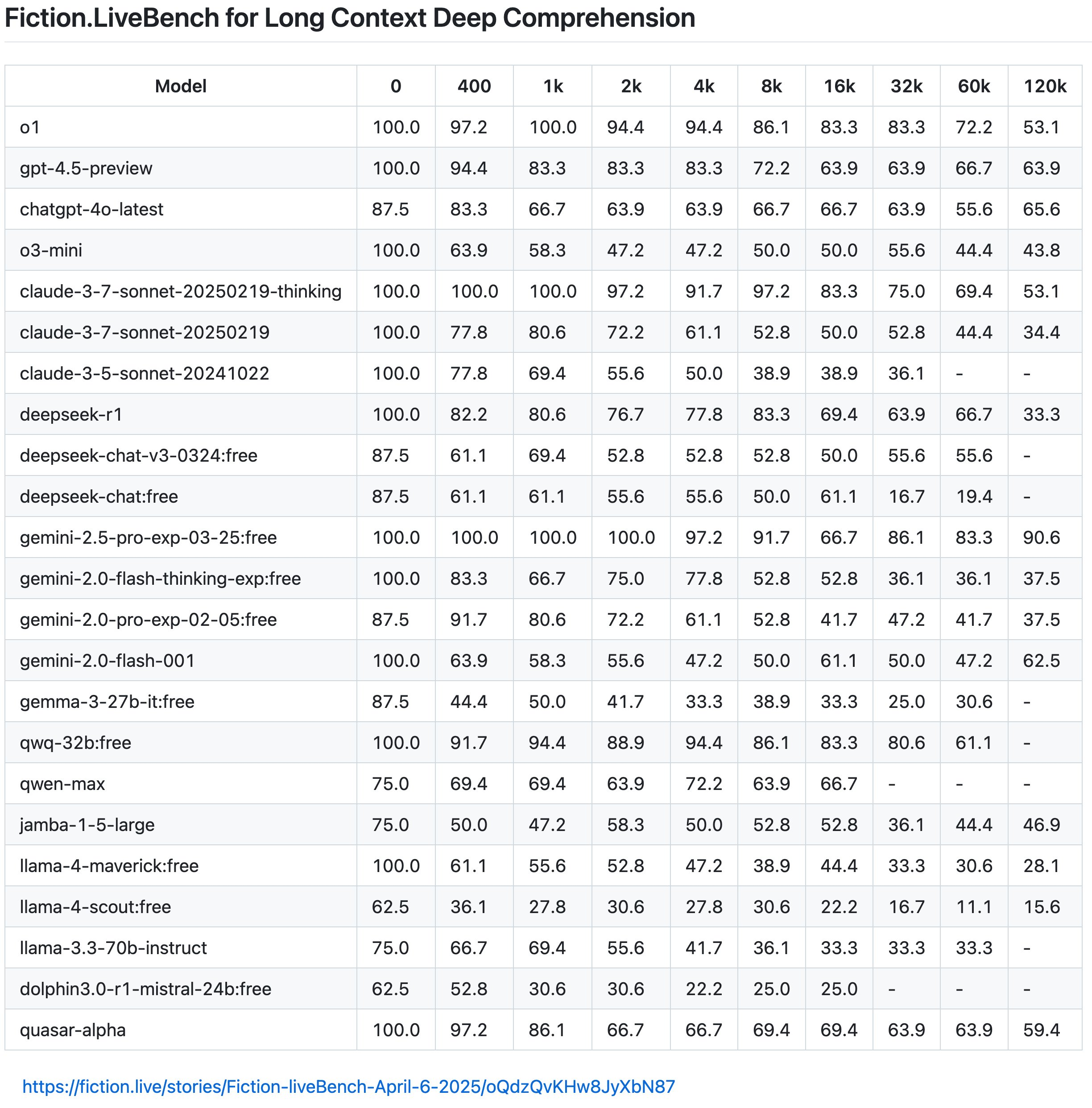
Пользователь сети Кармински далее отметил, что у Llama 4 показатель упал ниже 60%, когда скорость запоминания контекста составляет 1 КБ (приблизительно понимаемая как скорость правильного ответа на вопросы), и даже у Llama-4-Scout этот показатель составляет только 22%, когда он превышает 16 КБ.
Он также привел яркий пример: «Объем текста «Гарри Поттера и философского камня» составляет около 16К.
Это означает, что если вы введете в модель всю книгу, а затем спросите: «Жил ли Гарри в спальне или в кладовой под лестницей, когда был ребенком?», Лама-4-Разведчик даст правильный ответ только в 22% случаев (приблизительное понимание, фактический механизм отзыва более сложен). И этот результат, естественно, намного ниже среднего уровня модели головы.
Мало того, что сама модель слегка растянута, так еще и ореол Llama 4 как «лидера с открытым исходным кодом» постепенно тускнеет.
Meta раскрывает возможности Llama 4, но даже с использованием квантования она не может работать на графических процессорах потребительского уровня. Говорят, что он работает на одной карте, но на самом деле это относится к H100. Высокий порог весьма недружелюбен к разработчикам.
Более того, новая лицензия Llama 4 имеет несколько ограничений, наиболее критикуемым из которых является то, что компании с более чем 700 миллионами активных пользователей в месяц должны подать заявку на получение специальной лицензии от Meta, которую Meta может решить по своему усмотрению, одобрить или отклонить.

Подождите, это не то, что говорилось в параметрах бумаги, объявленных Мета вчера. Почему через день направление ветра полностью изменилось.
В рейтинге крупных моделей Arena Llama 4 Maverick заняла второе место в общем списке, став четвертой моделью, набравшей более 1400 баллов. Он возглавил список моделей с открытым исходным кодом, обогнав DeepSeek V3.
Столкнувшись с тем фактом, что измеренная производительность была «неправильной», внимательные пользователи сети быстро почувствовали что-то подозрительное. Маверик, добившийся высоких результатов на LM Arena, фактически использовал «экспериментальную версию чата».

Это еще не конец. Сегодняшний выпуск последних новостей о сообществе One Acre Threequarter Land, похоже, раскрыл некоторые внутренние истории. Сообщалось, что после повторного обучения Llama 4 не смогла получить SOTA с открытым исходным кодом и даже была далека от этого.
Крайний срок, установленный компанией Meta Company для выпуска, — конец апреля.
Поэтому руководство компании предложило в посттренировочном процессе смешивать тестовые наборы различных тестов в надежде добиться взаимного обогащения по различным показателям. Придумайте результат, который «выглядит хорошо».
Смешение наборов тестов различных тестов в упомянутом здесь процессе постобучения означает, что на этапе постобучения модели путем смешивания наборов данных из разных тестов модель может обучаться в различных задачах и сценариях, тем самым улучшая свою способность к обобщению.
Если использовать простую аналогию, это похоже на списывание на экзамене. Предполагалось, что тестовые вопросы будут выбраны случайным образом из конфиденциального банка вопросов (набор эталонных тестов), и никто не знал об этом до начала теста. Но если кто-то заранее просматривает вопросы и повторяет их неоднократно (что эквивалентно включению тестового набора в обучение), он обязательно преуспеет на экзамене.
В плакате также поясняется, что после выпуска Llama 4 фактические результаты испытаний подверглись критике со стороны пользователей X и Reddit. Как человек, который в настоящее время работает в академических кругах, он заявил, что действительно не может принять подход Меты. Он подал заявление об отставке и прямо потребовал, чтобы его имя было удалено из технического отчета Llama 4.
Он также сообщил, что вице-президент Meta по искусственному интеллекту также подал в отставку по этой причине. Несколько дней назад сообщалось, что руководитель исследований Meta AI Жоэль Пино объявила, что покинет свой пост 30 мая.

Однако, возможно, потребуются дополнительные доказательства истинности этого предполагаемого обвинения в «мошенничестве списков». Сотрудник Meta по имени LichengYu также ответил своим настоящим именем в области комментариев:
«За последние два дня я смиренно выслушивал отзывы всех сторон (таких как кодирование, творческое письмо и другие дефекты, которые необходимо исправить) и надеюсь исправиться в следующей версии. Однако мы никогда не переоснащали тестовый набор, чтобы подтянуть очки. Настоящее имя — Личэн Ю. Я занимался постобучением двух моделей ОС. Скажите, пожалуйста, какая подсказка была выбрана из тестового набора и помещена в обучающий набор. Я дам вам + извинения!»

Публичная информация показывает, что Личэн Юй окончил Шанхайский университет Цзяо Тонг, получил двойные степени магистра в Технологическом институте Джорджии и Шанхайском университете Цзяо Тонг в 2014 году и получил степень доктора компьютерных наук в Университете Северной Каролины в Чапел-Хилл в мае 2019 года.
Его исследовательские области сосредоточены на компьютерном зрении и обработке естественного языка, и многие статьи были приняты на ведущих конференциях, таких как CVPR, ICLR, ECCV и KDD.
Личэн Юй имел опыт работы в крупных компаниях, таких как Microsoft и Adobe. В настоящее время он является научным руководителем Меты (с 2023.06 по настоящее время). Он участвовал в выпуске мультимодальной модели Llama3.2 (11B+90B) и руководил этапом обучения с подкреплением текста и изображения для 17Bx128 и 17Bx16 в проекте Llama 4.
Трудно сказать, правда это или нет, и, возможно, благодаря этому пули будут лететь еще какое-то время.
«Трон» крупных моделей с открытым исходным кодом невозможно захватить грубой силой
На этот раз в прошлом году Meta была названа избранной в индустрии искусственного интеллекта.
Разумеется, сняв простую серую футболку, джинсы и худи, Цукерберг также стал часто носить брендовую одежду с большими логотипами, вешать на шею большие и грубые золотые цепочки и даже уверенно демонстрировать на публике свои результаты в фитнесе.
Цукерберг, который не интересуется выпивкой, пытается стать ближе к публике, показывая более «реальную» и «приземленную» сторону. Это не только делает Meta более дружелюбным к людям, но и делает его стандартным носителем открытого исходного кода в отличие от модели OpenAI с закрытым исходным кодом, с беспрецедентным импульсом.

В то же время сильная сила Меты обеспечивает надежную поддержку трансформации. Сообщается, что Meta планирует инвестировать до 65 миллиардов долларов США в 2025 году в расширение своей инфраструктуры искусственного интеллекта, что является большой суммой в отрасли. К концу 2025 года Meta планирует иметь более 1,3 миллиона графических процессоров.
Во-вторых, Meta располагает обширными данными социальных платформ, что дает ей уникальные преимущества в исследованиях и разработках в области ИИ.
Будучи материнской компанией всемирно известных социальных платформ, таких как Facebook, Instagram и WhatsApp, Meta располагает данными о ежедневном взаимодействии миллиардов пользователей. Согласно статистике, число ежедневных активных пользователей (DAU) ее платформы в мире превысит 3 миллиарда в 2024 году. Этот огромный объем данных обеспечивает огромный исходный материал для обучения моделей ИИ.
Кроме того, Meta не менее щедра в своем кадровом резерве. Руководителем отдела искусственного интеллекта является обладатель престижной отраслевой премии Тьюринга Ян ЛеКун. Под его руководством Meta придерживалась стратегии открытого исходного кода и запустила серию моделей Llama.
Поэтому Meta также очень амбициозна — она не только хочет укрепить свои позиции в социальной сфере, но и надеется добиться обгона на поворотах в сфере искусственного интеллекта, с целью превзойти сильных конкурентов, таких как OpenAI, к концу 2025 года.

Но я видел, как он строил Чжулоу, видел, как он развлекал гостей, и видел, как рушилась его башня.
Если новости о One Third Acre правдивы, то в процессе разработки Llama 4 может иметь место «обман» в погоне за результатами контрольных тестов — смешивание набора тестов с обучающими данными больше похоже на операционную деформацию под «тревогой дорожного движения ИИ».
В начале года появилась новость о том, что DeepSeek вызвал панику у команды Meta AI:
«Когда зарплата каждого руководителя в организации, занимающейся генеративным искусственным интеллектом, превышает стоимость обучения всего DeepSeek-V3, а таких руководителей у нас десятки, как они столкнутся с высшим руководством?»
В 2023 году Meta установила почти монополию в области крупных моделей с открытым исходным кодом, выпустив серию Llama, став синонимом и эталоном искусственного интеллекта с открытым исходным кодом.
Однако один день для ИИ и один год для людей. В области комментариев, где Llama 4 столкнулась с «Ватерлоо», повсюду можно увидеть похвалы от других моделей с открытым исходным кодом. Среди них Google Gemma завоевала широкое признание благодаря своему легкому весу, высокой эффективности и мультимодальным возможностям, появились базовые модели серии Qwen от Alibaba, а DeepSeek шокировал всю отрасль своим статусом недорогой и высокопроизводительной темной лошадки.
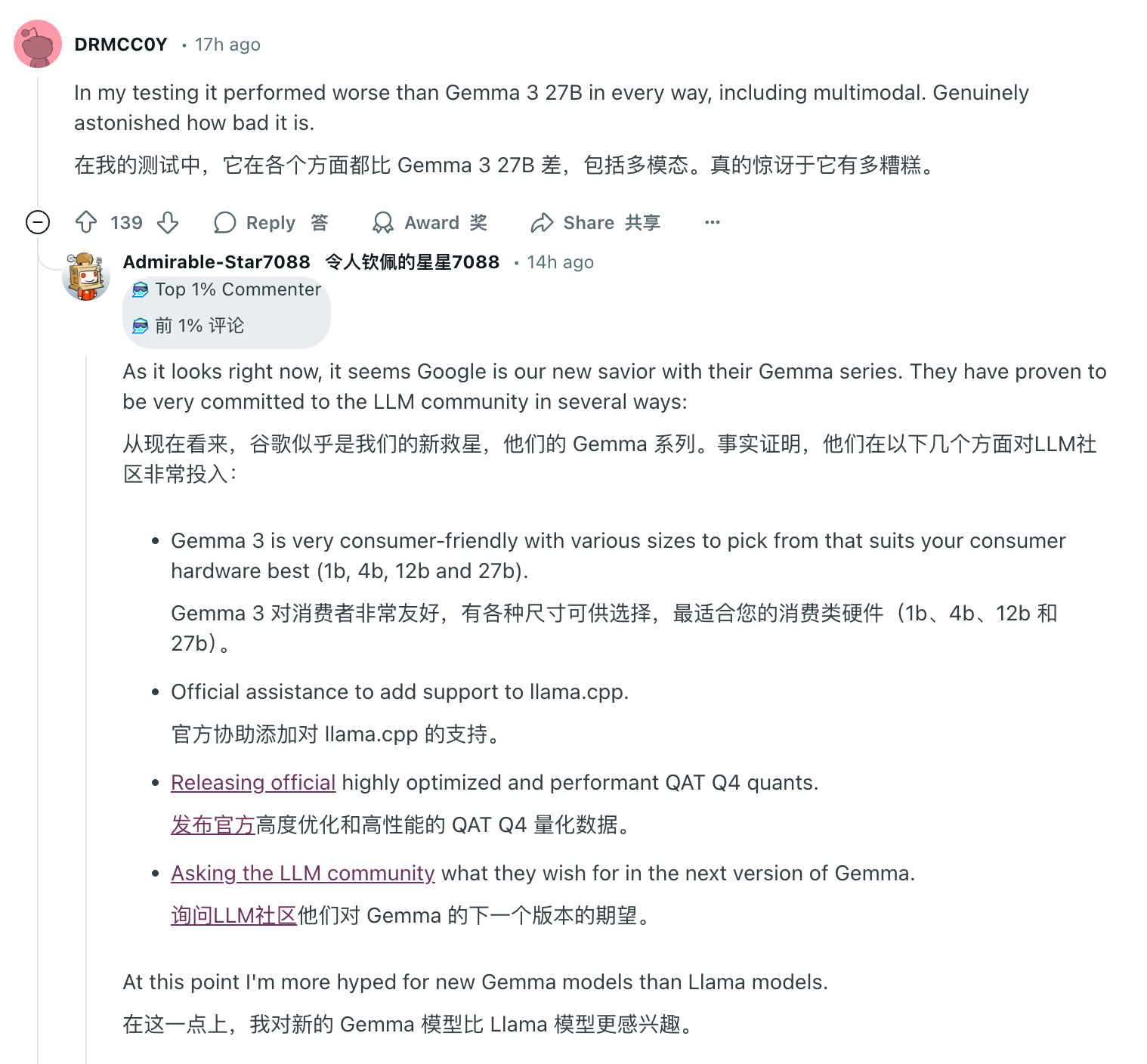
Пока неизвестно, сможет ли Meta скорректировать свою стратегию и вернуться на лидирующие позиции моделей ИИ с открытым исходным кодом, но в любом случае расцвет ИИ с открытым исходным кодом необратимо наступил.
Придерживаясь принципа, какой ИИ прост в использовании, какой из них следует использовать, Meta не может полностью винить пользователей. Более того, с точки зрения прозрачности открытого исходного кода, по сравнению с моделями с открытым исходным кодом вышеупомянутых компаний, добровольные ограничения Llama 4 также означают, что ей отрезали руку.
Текущая борьба Meta может также показать, что даже если у нее есть все мировые вычислительные мощности графических процессоров и огромные объемы данных, преимущества ресурсов больше не являются решающим фактором. «Трон» больших моделей с открытым исходным кодом невозможно завоевать грубой силой.
# Добро пожаловать на официальную общедоступную учетную запись WeChat aifaner: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo