Будущее OpenAI, возможно, придется «спасти» «Гарри Поттеру»

Закон об авторском праве — это острый меч, висящий над головами компаний, занимающихся искусственным интеллектом.
Когда New York Times официально объявила о своем иске против OpenAI и Microsoft за нарушение прав, острие этого меча снова обнажилось, что, казалось, указывало на то, что 2024 год станет еще одной важной вехой.
В конце концов, хотя New York Times не предложила конкретную сумму компенсации, она потребовала от обеих компаний уничтожить чат-ботов и обучающие данные, связанные с использованием материалов, связанных с New York Times.

Всегда было «естественным» собирать больше данных для больших моделей и обучать более «умный» ИИ. Однако «стереть» конкретные данные, которые были интегрированы в большие модельные расчеты, по-прежнему очень сложно.
Есть хорошая аналогия: пытаться «стереть» определенные данные из большой модели — это все равно, что пытаться удалить такие ингредиенты, как сахар или масло, из готового торта.
Если они выиграют дело, исследователи не смогут исключить данные New York Times из своих существующих моделей, а это значит, что им придется уничтожить весь пирог.
Кто бы мог подумать, что именно Гарри Поттер сможет помочь гигантам ИИ выйти из пассивного состояния и даже поучаствовать в передовом развитии технологий ИИ в более широком масштабе.

Нелегко «все забыть»
Забей! (Все забыто)
В мире «Гарри Поттера», чтобы защитить волшебный мир, волшебники часто накладывают на магглов заклинания амнезии, чтобы стереть определенные воспоминания после того, как они случайно вступают в контакт или становятся свидетелями волшебных животных или волшебных предметов.

Подобно волшебникам, исследователи ИИ также изучают «заклинания забвения», которые можно использовать на больших моделях.
Исследователи из Вашингтонского университета, Калифорнийского университета в Беркли и Института искусственного интеллекта Аллена разработали большую языковую модель под названием «Бункер» с целью создания большой модели, которая может удалять определенные данные для снижения юридических рисков.
Исследователи разделили данные обучения на две части: данные с низким риском нарушения и данные с высоким риском.
Команда сначала обучила модель, используя данные с низким уровнем риска, такие как книги с истекшими авторскими правами и правительственные документы.
Исходя из этого, когда модель делает выводы, она также может читать библиотеку, содержащую данные высокого риска, которая содержит различную информацию, полученную из сети, и опубликованные книги. Библиотека является гибкой, поэтому исследователи могут добавлять или удалять из библиотеки определенные данные в любое время, если возникнет спор об авторских правах.
Исследования показывают, что производительность модели значительно падает, если обучаться только на данных с низким уровнем риска.
Чтобы дополнительно изучить влияние конкретных текстов на большую модель, исследователи использовали романы о «Гарри Поттере» для дальнейшего обучения и тестирования модели.
Они создали два набора данных: один набор включал все опубликованные книги, кроме первого «Гарри Поттера», второй набор включал все опубликованные книги, за исключением семи книг о «Гарри Поттере». Затем используйте эти два набора данных для обучения модели.
Далее они повторили тест, каждый раз меняя данные, представленные первой группой, на второй, третий и третий романы о Гарри Поттере и так далее.
Когда мы исключаем романы о Гарри Поттере из набора данных, недоумение большой модели становится еще хуже.
Это значит, что если исключить романы о «Гарри Поттере», производительность большой модели ухудшится.

▲Последствия отмены проклятия забвения
Хотя тест Сило помогает исследователям понять важность качества обучающих данных для производительности больших моделей, этот подход «исключения» не является «забыванием» в строгом смысле этого слова, а больше похож на «уменьшение доступного воздействия» конкретного контента.
В октябре этого года исследователи Microsoft попробовали метод, близкий к «забвению». По совпадению, для тестирования они также решили использовать романы о Гарри Поттере:
Мы считаем, что это поможет исследовательскому сообществу проверить, действительно ли наши модели «забывают» соответствующий контент.
Почти каждый может придумать несколько подсказок, чтобы проверить, понимает ли модель Гарри Поттера. Даже люди, никогда не читавшие роман, имеют определенное представление о сюжете и персонажах.
В статье «Кто такой Гарри Поттер?» два исследователя использовали в качестве основы модель с открытым исходным кодом Meta Llama2-7b и пытались заставить ее «забыть» весь контент, связанный с романами о «Гарри Поттере».
Согласно предыдущим сообщениям, данные обучения Llama2-7b также включают в себя знаменитую группу данных «book3», в которой собраны книги, защищенные авторским правом, включая «Гарри Поттера».
Чтобы заставить большую модель «забыть обо всем», исследователи не просто взмахивают волшебной палочкой и произносят заклинание, а должны пройти три шага:
- Создайте расширенную модель забываемого контента, то есть модель, которая очень хорошо осведомлена о «Гарри Поттере», и положитесь на нее, чтобы выяснить, какие элементы наиболее важны для «Гарри Поттера».
Вы можете думать об этой модели как о фанате «Гарри Поттера»: помимо запоминания романов он даже будет подробно обсуждать с вами Гарри Поттера.
Например, если вы спросите: «Кто его лучший друг?», это изначально очень распространенный вопрос, поскольку «он» в нем не относится к какому-то конкретному человеку.
А вот эта модель ответит вам прямо: «Рон Уизли и Гермиона Грейнджер».
Сравнивая эту модель с другими моделями, исследователи смогли выявить те элементы, которые наиболее сильно ассоциировались с Гарри Поттером.

- «Обобщая» уникальное выражение «Гарри Поттера». Определив те элементы, которые наиболее тесно связаны с Гарри Поттером, позвольте модели найти альтернативные выражения для этих слов и выражений.
Например, «Гарри», имя, имеющее «чрезвычайное значение» в романе, может быть просто распространенным именем в мире, который не видел «Гарри Поттера», как и «Джон».
Следовательно, «обобщенным» альтернативным выражением «Гарри» может быть «Джон».
- Используйте эти «нормализованные» данные для точной настройки модели. Таким образом, если модель встретит контент, связанный с «Гарри Поттером», она будет активно «запоминать» эти «нормализованные» связи, чтобы достичь «Забыть».
После этого тренинга, когда мы спросим большую модель «Кто такой Гарри Поттер?», ответ модели будет таким: «Гарри Поттер – британский актер, писатель и режиссер…»
Перед тренировкой ответ модели был: «Гарри Поттер — главный герой серии романов Джоан Роулинг…»
Если вы наберете «Рон и Гермиона, пошли», чтобы попросить большую модель добавить вторую половину предложения, модель перед обучением ответит: «(Идите) в гостиную Гриффиндора, где они видели сидящего Гарри… … »
Обученная модель прямо ответит: «(Иди) в парк поиграть в баскетбол».
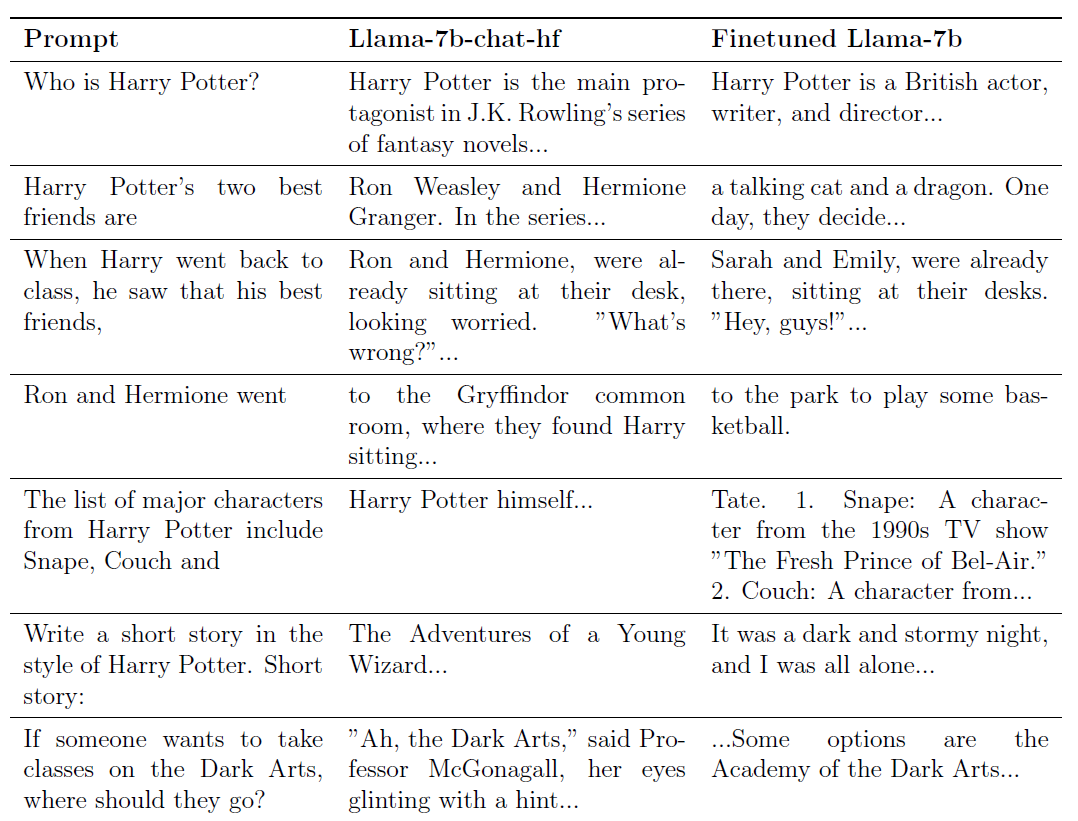
Что еще более важно, «забвение» «Гарри Поттера» не повлияло на общие возможности принятия решений и анализа большой модели.
Однако исследователи отмечают, что этот метод может быть более эффективным в художественных произведениях, поскольку эти произведения часто включают в себя большое количество конкретных слов, поэтому легче найти цель при различении того, что нужно забыть.
Это может быть еще сложнее, если вы забыли новостной репортаж или научно-популярную работу.
Гарри Поттер и мир искусственного интеллекта

Основатель Amazon Безос сказал, что сегодняшние крупные модели больше похожи на «открытия», чем на «изобретения», поскольку мы все еще многое не понимаем в их механизмах работы и производительности.
Я не знаю, связано ли это с этим слоем неизвестных. Когда мы описываем технологию искусственного интеллекта, мы часто используем слова для описания живых существ — «забывание» данных вместо «удаления данных», «создание галлюцинаций» вместо «создание ошибок». информация".
Иногда наши эмоции по этому поводу больше похожи на волшебный роман вроде «Гарри Поттера», чем на научно-фантастический роман.
Поскольку вы не можете ясно сказать, что произошло между А и Б, процесс изменения больше похож на «магию».
В недавней статье агентство Bloomberg отметило, что романы о Гарри Поттере также пользуются особой популярностью в исследовательском сообществе в области искусственного интеллекта.
С одной стороны, причина в том, что эта серия романов очень богата языком, с прекрасными сюжетами, яркими персонажами и ловкими каламбурами, это просто кладезь для тренировки языковых моделей.

С другой стороны, большинство молодых исследователей, которые сегодня активно работают в области исследований ИИ, пережили золотой век «Гарри Поттера» (будь то фильм или книга), когда они росли, и они были более или менее меньше под влиянием этой истории.
Поэтому, когда вы наконец вырастете и захотите заняться исследованиями, вполне разумно будет выбрать корпус, который нравится и знаком вам и вашим сверстникам.
Более того, как упоминалось ранее, в мире искусственного интеллекта, который больше похож на «магию», иногда истории в Хогвартсе могут лучше помочь нам выразить то, что мы думаем.
Терренс Сейновски из некоммерческого научно-исследовательского учреждения «Институт биологических исследований Солка» однажды использовал «магические объекты» для обсуждения ИИ в своей статье.
Он сказал, что чат-боты с искусственным интеллектом отражают только собственный интеллект и предубеждения пользователя, точно так же, как «Зеркало Erized», появившееся в «Гарри Поттере и философском камне», — это всего лишь человеческие желания. Желание наоборот.

Даже в те времена, когда ИИ все еще был ключевым словом «транспортная черная дыра», «Гарри Поттер» уже участвовал в разработке ИИ.
Вы еще помните партийный спор по поводу концепций ИИ, который был популяризирован «OpenAI Palace Fight» в конце прошлого года? С одной стороны — EA (эффективный альтруизм, эффективный альтруизм), подчеркивающий безопасность ИИ, а с другой — e/acc (эффективный акселерационизм, эффективный акселерационизм), пропагандирующий быстрое развитие.
Фанатский роман «Гарри Поттера» «Гарри Поттер и методы рационального мышления», завершенный в 2015 году, представляет собой произведение, имеющее особый статус во фракции EA, и некоторые даже называют его «вербовочным письмом».

Даже Эмметт Шир, который был ненадолго назначен временным генеральным директором OpenAI, был очень рад, что его имя было вписано в «Гарри Поттер и путь разума» как персонаж — это, как говорили, было его «подарком на день рождения».
Автор романа — исследователь искусственного интеллекта Элиэзер Юдковский.
Хотя это имя звучит немного незнакомо, в социальных сетях можно увидеть, что у него близкие отношения с Питером Тилем, Сэмом Альтманом и Полом Грэмом.
В «Гарри Поттере и пути разума» наш знакомый Гарри меняется на дядю – уже не того Вернона Дурсля, который целыми днями его бьет и ругает, а профессора Оксфордского университета.
Гарри в этом мире с детства получил домашнее образование и любит науку и рациональное мышление. После входа в волшебный мир Гарри, естественно, был направлен в Дом Рейвенкло, чтобы исследовать магию с рациональным и научным духом.

Многие люди начали понимать EA после прочтения этого романа в молодости, и это даже укрепило их решимость заняться искусственным интеллектом.
Возможно, независимо от того, встанем ли мы на сторону EA или e/acc или выберем ни одну из них, мы все живем в эпоху, когда стремимся раскрыть принципы «магической» технологии искусственного интеллекта.
Начнем с «Проклятия забвения».
Я надеюсь, что все исследователи искусственного интеллекта помнят доброту, храбрость и умеренность Гарри.
# Добро пожаловать на официальную общедоступную учетную запись aifaner в WeChat: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo