Хотите выиграть 4,6 миллиона долларов на GPT-5? Команда Кими отвечает на всё впервые, Ян Чжилинь также присутствует.

На прошлой неделе был выпущен Kimi K2 Thinking, и его модель с открытым исходным кодом превзошла OpenAI и Anthropic, вызвав настоящий фурор в социальных сетях. Пользователи сети говорят, что это потрясающе, и мы тоже протестировали его сами. Он действительно демонстрирует значительное улучшение в интеллектуальных агентах, кодировании и навыках письма.
Команда Кими, включая основателя Янга Чжилиня, только что провела насыщенное информацией мероприятие AMA (Ask Me Anything — «Спроси меня о чём угодно») на Reddit.

▲ Команда Кими, состоящая из трех соучредителей: Ян Чжилиня, Чжоу Синью и У Юйсиня, приняла участие в ответе.
Столкнувшись с острыми вопросами сообщества, Кими не только раскрыл некоторые секреты модели K3 следующего поколения и детали базовой технологии KDA, но и откровенно рассказал о стоимости в 4,6 млн долларов и огромных различиях между Kimi и OpenAI с точки зрения затрат на обучение и философии продукта.
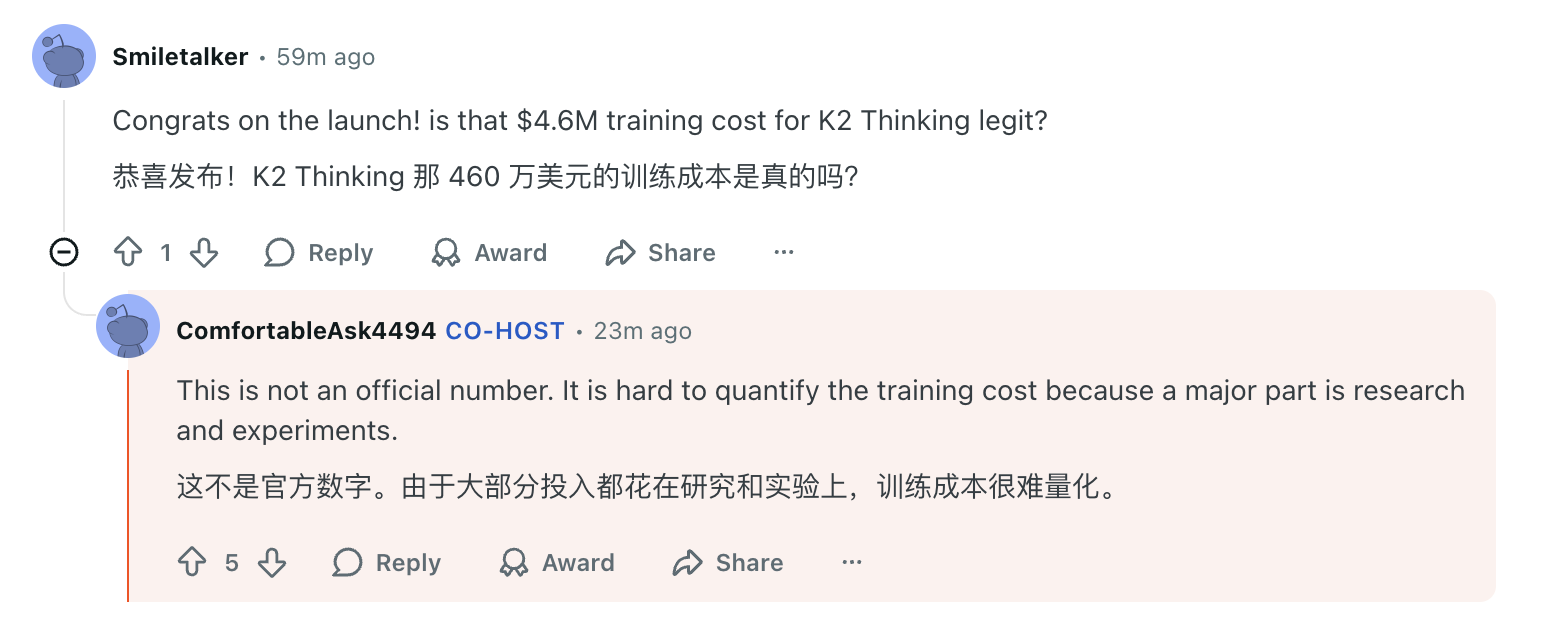
- Цифра в 4,6 млн долларов не является официальной; точную стоимость обучения оценить сложно.
- Когда прибудет K3? Это зависит от того, когда будет достроен дата-центр Ультрамена стоимостью в триллион долларов.
- Технологии, используемые в K3, будут использоваться и дальше, включая высокоэффективный в настоящее время механизм внимания KDA.
- Нам еще предстоит собрать больше данных для визуальных моделей, но мы уже этим занимаемся…

Мы собрали некоторые из наиболее примечательных ключевых моментов этого AMA, чтобы вы могли увидеть, как эта лаборатория ИИ, которая в настоящее время считается лидером в области отечественных решений с открытым исходным кодом, рассматривает свою модель и будущее развитие ИИ.
Бросая вызов OpenAI: «У нас свой ритм».
Вероятно, самой бурной частью этого AMA стала реакция команды Кими на OpenAI.
Один из самых важных вопросов: когда появится K3? Команда Кими дала весьма остроумный ответ: « До того, как будет построен дата-центр Ультрамена стоимостью в триллион долларов».
Это отчасти явно смешно, поскольку никто не знает, когда OpenAI действительно сможет построить такой центр обработки данных, а отчасти, похоже, является ответом на восхищение внешнего мира тем, что Kimi может догнать GPT-5, имея меньше ресурсов.
Когда один из пользователей сети напрямую спросил Кими, что он думает о том, что OpenAI тратит так много денег на обучение, Кими откровенно ответил: «Мы тоже не знаем, знает только сам Ультрамен», и твердо добавил: « У нас свои методы и темп».
Этот независимый ритм в первую очередь отражается в философии их продукта. На вопрос, планируют ли они выпустить браузер с искусственным интеллектом, подобный OpenAI, команда ответила прямо: «Нет».
Нам не нужно создавать еще одну оболочку Chromium (оболочку браузера), чтобы построить лучшую модель.
Они подчеркнули, что в настоящее время их работа сосредоточена на обучении моделей, а демонстрация возможностей будет осуществляться с помощью большой модели-помощника.
Кими также продемонстрировал бережливый подход к расходам на обучение и оборудование. Когда сообщество задались вопросом, соответствует ли слухам о стоимости обучения K2 в 4,6 миллиона долларов, Кими пояснил, что эта цифра неверна, но отметил, что большая часть средств была потрачена на исследования и эксперименты, что затрудняет точную оценку.
Что касается аппаратного обеспечения, Кими признался, что они использовали графические процессоры H800 и Infiniband, которые, хотя «не так хороши, как топовые графические процессоры в США, и не так многочисленны», позволяли полностью задействовать каждую карту.
Индивидуальность модели и мусорный запах ИИ
Хорошей модели нужен не только интеллект, но и индивидуальность.
Многим пользователям нравится стиль Kimi K2 Instruct, они считают его «менее лестным, но при этом содержательным и уникальным, как эссе».
Кими объяснил, что это результат сочетания «предварительного обучения (предоставление знаний) и последующего обучения (добавление вкуса)». Различные формулы обучения с подкреплением (то есть разные варианты моделей вознаграждения) приведут к разным стилям, и они также намеренно спроектируют модель менее послушной .
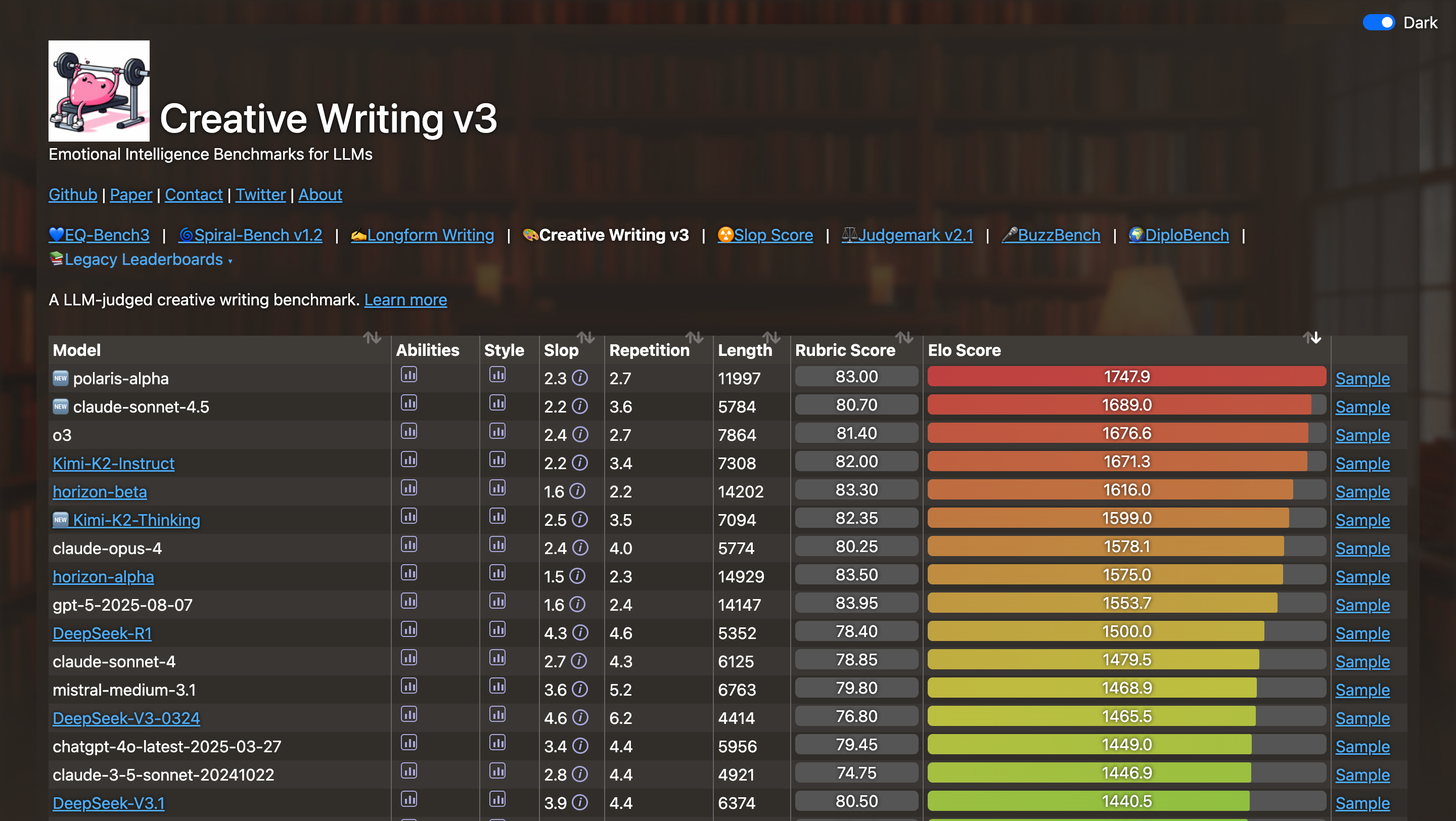
▲ Рейтинг оценки эмоционального интеллекта с использованием большой языковой модели. Источник изображения: https://eqbench.com/creative_writing.html
Однако некоторые пользователи прямо заявили, что стиль письма Кими K2 Thinking — это «полный отстой ИИ». Независимо от темы, стиль слишком позитивный и оптимистичный, что создаёт сильное ощущение присутствия искусственного интеллекта. Один пользователь даже привёл пример: когда Кими попросили написать о жестоком или конфронтационном контенте, он всё равно сохранил позитивный и оптимистичный стиль.
Команда Кими ответила очень откровенно. Они признали, что это распространённая проблема больших языковых моделей, и отметили, что современное обучение с подкреплением намеренно усиливает этот стиль.
Это расхождение между пользовательским опытом и данными тестирования также отражается в скептицизме, связанном с результатами бенчмарков . Один из пользователей сети многозначительно спросил, был ли Kimi K2 Thinking специально обучен для таких бенчмарков, как HLE, чтобы достичь столь высокого результата, учитывая, что такой высокий результат, похоже, не соответствует его реальному интеллектуальному уровню в реальных условиях.
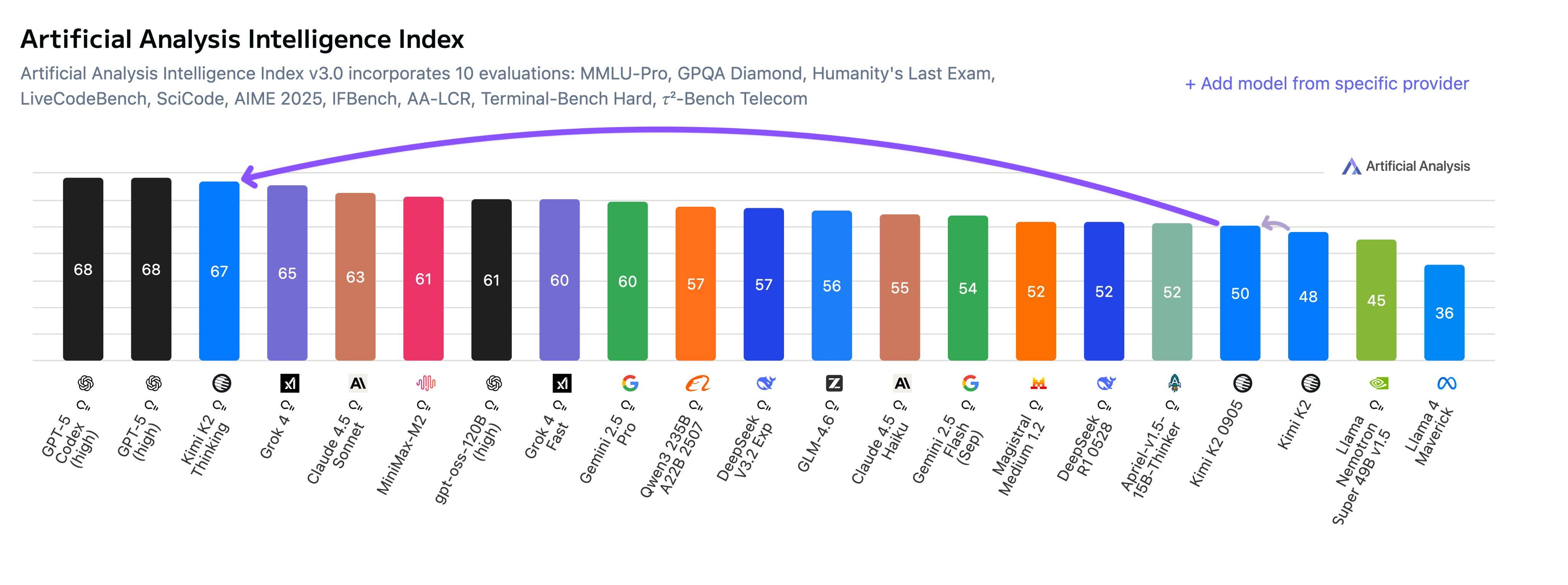
Команда Кими объяснила, что добилась небольшого прогресса в улучшении автономного мышления, что, как ни странно, способствовало высокому результату K2 Thinking на HLE. Однако они также открыто обозначили направление своей работы: дальнейшее развитие общих возможностей, чтобы система могла достичь уровня интеллекта, соответствующего её бенчмаркам, в более реальных приложениях.
Пользователи сети также отметили, что Grok Маска выполнил много работы, не относящейся к сфере безопасности на работе (NSFW), создав изображения и видео; Kimi мог бы использовать его писательские навыки для написания текстов, не соответствующих требованиям безопасности на работе, что, несомненно, привлекло бы к Kimi множество пользователей.

Кими лишь улыбнулся и промолчал, сказав, что это хорошее предложение. Поддержка контента NSFW в будущем может зависеть от поиска методов проверки возраста и дальнейшего улучшения согласованности моделей.
Очевидно, что на данном этапе Кими не может поддерживать NSFW.
Раскрыты основные технологии: KDA, длинный вывод и мультимодальный анализ
Поскольку компания известна как «лаборатория-первопроходец в области ПО с открытым исходным кодом», а сам Reddit представляет собой очень большое и активное техническое сообщество, Кими также поделился множеством технических подробностей в этом AMA.
В конце октября в своей статье «Линейная модель Кими: выразительная и эффективная архитектура внимания» Кими подробно описал новую гибридную линейную архитектуру внимания, Kimi Linear, ядром которой является Kimi Delta Attention (KDA).

▲Реализация алгоритма KDA, ссылка на статью: https://arxiv.org/pdf/2510.26692
Проще говоря, внимание — это механизм, с помощью которого искусственный интеллект решает, на каких словах в контексте сосредоточиться при размышлении. В отличие от обычного полного и линейного внимания, KDA (Kimi Delta Attention) — более интеллектуальный и эффективный механизм внимания .
В ходе этого AMA Кими также несколько раз упомянул, что KDA продемонстрировал улучшение производительности в сценариях обучения с подкреплением с длинной последовательностью и что идеи, связанные с KDA, вероятно, будут применены в K3.
Однако Кими также признал, что в технологиях существуют компромиссы. В настоящее время основная цель гибридного внимания — экономия вычислительных затрат, а не улучшение рассуждений. Для задач с длительным вводом и длительным выводом полное внимание по-прежнему работает эффективнее.
Как же Kimi K2 Thinking достигает такой сверхдлинной цепочки рассуждений, включающей рассмотрение и использование до 300 инструментов? Некоторые пользователи сети даже считают, что он лучше GPT-5 Pro.
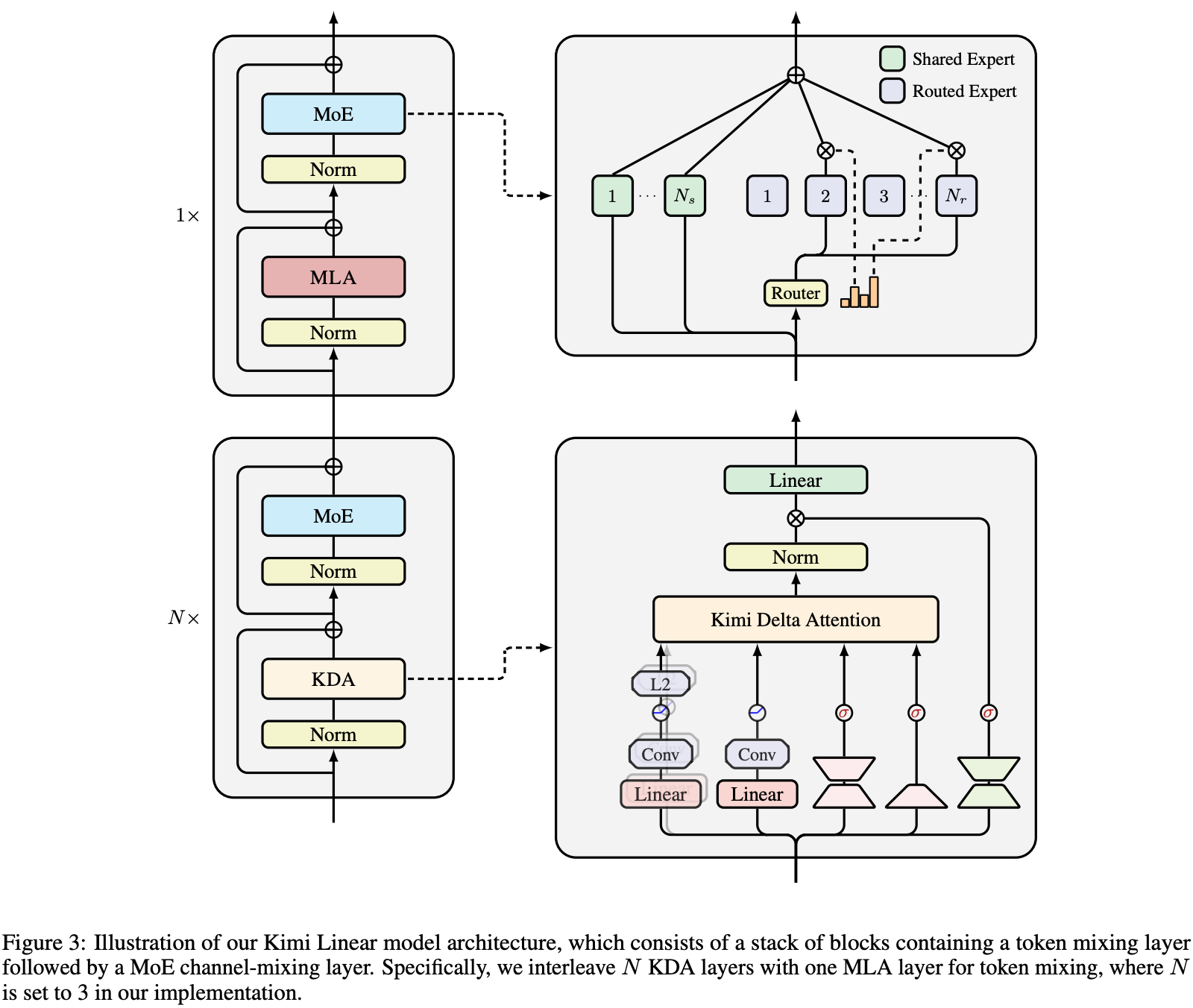
▲ Структура линейной модели Кими
Кими считает, что это зависит от метода обучения: для достижения оптимальных результатов обычно используется относительно большее количество токенов мышления . Кроме того, K2 Thinking изначально поддерживает INT4, что ещё больше ускоряет процесс рассуждения.
В нашей предыдущей статье о Kimi K2 Thinking мы также рассказали о методе квантования INT4, который является эффективным методом квантования (INT4 QAT). Kimi не сжимал данные после обучения, но поддерживал модель вычислений с низкой точностью в процессе обучения.
Это дает два огромных преимущества: повышенную скорость рассуждений и возможность обрабатывать длинные цепочки рассуждений без логического коллапса, вызванного сжатием и квантованием после обучения.
Наконец, говоря о долгожданной возможности визуального языка, Кими четко заявил: «Мы сейчас работаем над этим».
Причина, по которой мы сначала выпустили модель простого текста, заключается в том, что получение данных и обучение визуальной языковой модели требуют много времени, а ресурсы команды ограничены, поэтому мы можем отдать приоритет только одному направлению.
Экология, стоимость и открытость: будущее
Команда Кими также ответила на вопросы, которые волновали разработчиков и обычных пользователей.
Почему исчезла модель, способная обрабатывать 1 млн контекстов? Ответ Кими был лаконичен: «Цена оказалась слишком высокой». Что касается проблемы с тем, что 256 КБ контекста всё ещё недостаточно для работы с большими кодовыми базами, команда заявила, что планирует увеличить длину контекста в будущем.
Что касается ценообразования API, некоторые разработчики задаются вопросом, почему плата взимается на основе количества вызовов API, а не токенов. Для пользователей, использующих другие инструменты для интеллектуальных агентов, такие как Claude Code, тарификация на основе количества запросов к API является наименее контролируемым и непрозрачным методом.
До отправки запроса пользователь не имеет ни малейшего представления о том, сколько вызовов API сделает инструмент или как долго будет выполняться задача.

▲Программа членства Кими
Кими объяснил, что они использовали вызовы API, чтобы пользователям было понятнее, как формируются расходы, и чтобы это соответствовало планированию расходов их команды. Однако они также отметили, что будут изучать более эффективные методы расчёта.
Когда один из пользователей сети упомянул, что их компания не разрешает использовать других чат-помощников, Кими воспользовался возможностью, чтобы выразить основную философию компании:
Мы поддерживаем открытый исходный код, поскольку считаем, что общий искусственный интеллект должен быть целью, несущей единство, а не разделение.
Что касается главного вопроса — когда появится ИИОН? Кими считает, что ИИОН сложно определить, но люди уже начали ощущать его атмосферу, и на подходе более мощные модели.
В отличие от агрессивной рекламной и маркетинговой кампании Kimi в прошлом году, ответы Ян Чжилиня и его команды на этой сессии AMA действительно продемонстрировали, что на фоне постепенного доминирования отечественных технологий с открытым исходным кодом на мировом рынке моделей языков с открытым исходным кодом Kimi чувствует себя более уверенно и имеет более четкое понимание собственного темпа.
Основной принцип ясен: в этой поглощающей деньги и даже пространство гонке за искусственный интеллект, продолжение движения по пути открытого исходного кода — единственный способ продвинуть технологии вперед.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (WeChat ID: ifanr), где вы сможете как можно скорее получить еще больше интересного контента.
ifanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo