Точность диагностики Microsoft AI в 4 раза выше, чем у врачей-людей. Стоит ли нам спрашивать об этом перед визитом к врачу в будущем?

Точность диагностики искусственного интеллекта в четыре раза превышает точность диагностики врачей-людей.
В это может быть трудно поверить, но команда разработчиков искусственного интеллекта Microsoft недавно выпустила систему координации диагностики ИИ MAI-DxO (MAI Diagnostic Orchestrator), которая действительно это делает.
Он был протестирован на 304 реальных сложных случаях, еженедельно публикуемых в New England Journal of Medicine. Результаты теста показали точность 85,5%.
Этот бенчмарк больше не является контрольной работой, которую можно выполнить, просто заучив ее, а представляет собой совершенно новый стандарт оценки, созданный корпорацией Microsoft, «Sequential Diagnosis Bench» (SD Bench). Он в высшей степени восстанавливает интерактивные задачи реального процесса диагностики и лечения:
- Начните с первоначального описания симптомов пациентом.
- Путем многочисленных раундов вопросов и выбора различных тестов и обследований постепенно собирается информация о состоянии пациента.
- Для каждой проверки запишите стоимость проверяемого элемента, оцените необходимость и стоимость.
- Поставьте окончательный диагноз.
Столкнувшись с теми же 304 сложными случаями, Microsoft выбрала еще 21 практикующего врача из США и Великобритании с клиническим опытом от 5 до 20 лет. Результаты теста показали, что средняя точность реальных врачей составила всего 20%, что в четыре раза превышает разрыв с «искусственными интеллектуальными врачами».
В то же время, по сравнению с врачами-людьми, этот «доктор ИИ» также назначал меньше ненужных обследований, что снизило расходы на диагностику на 20–70%.
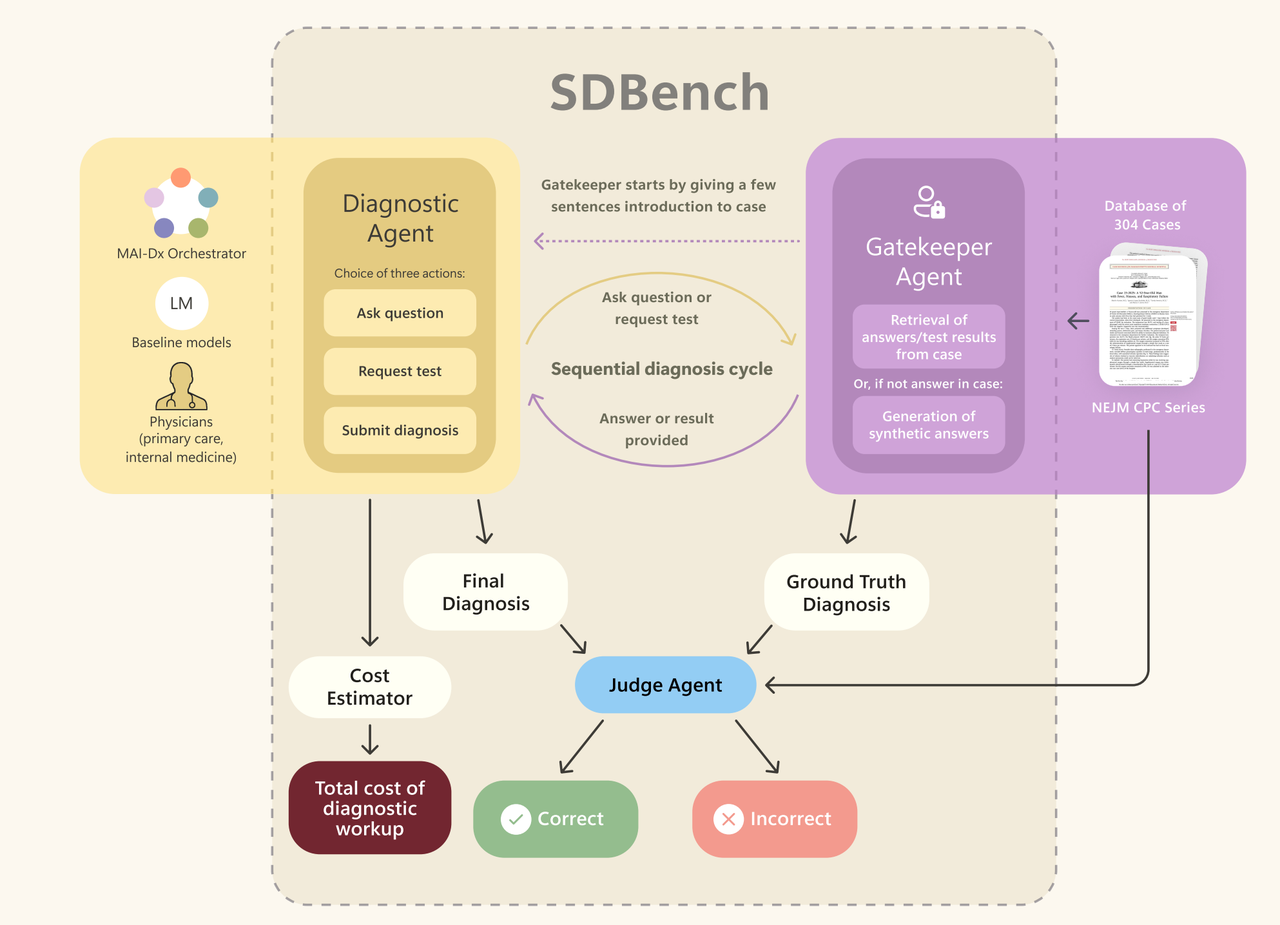
▲Вводная диаграмма последовательного диагностического эталонного теста. «Привратник» отвечает на информационные запросы от диагностических агентов, а модель оценки оценивает точность окончательного диагноза диагностического агента и отчета о случае.
Как MAI-DxO достигает точности, в четыре раза превышающей точность врачей-людей? Это не новая большая языковая модель, и она не опирается на одну модель.
MAI-DxO — это система, которая моделирует совместный процесс диагностики нескольких врачей в реальности. Благодаря непрерывному развитию текущей большой языковой модели, в системе MAI-DxO существуют различные языковые модели для исполнения пяти различных медицинских ролей.
К этим медицинским ролям относятся врач-гипотезник, который размышляет о различных результатах, врач-отборщик, врач-конкурент, который подвергает сомнению текущие диагностические предположения, врач-управитель затрат, который избегает ненужных тестов, и врач-контролер, который обеспечивает последовательность диагностических шагов и логики выбора.
Эти «врачи» работают сообща, полностью имитируя рабочий процесс человеческой медицинской бригады и компенсируя недостатки, которые может иметь одна модель ИИ при постановке сложных диагнозов.
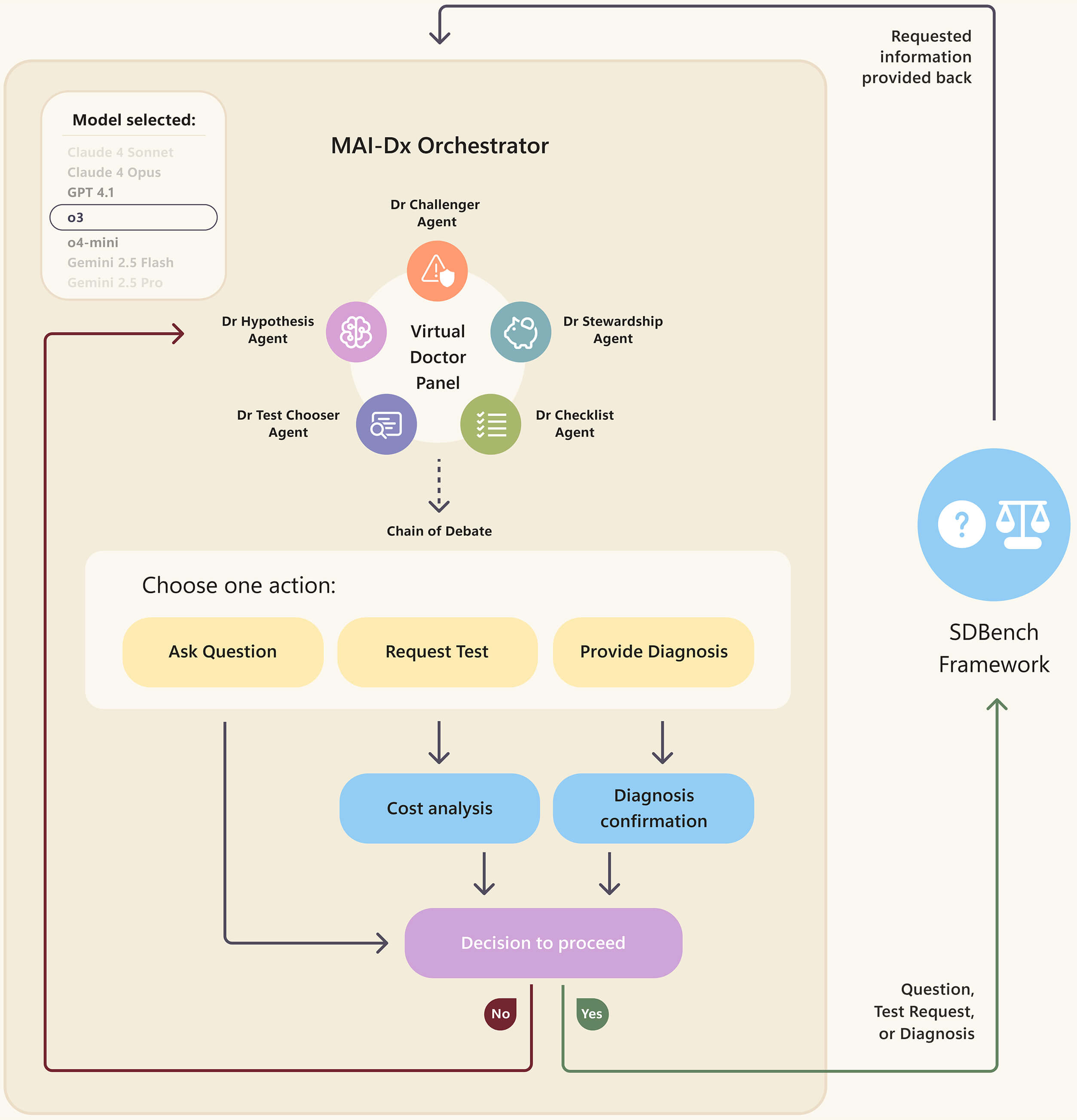
▲Обзор системы MAI-DxO
Как показано на схеме обзора системы, описанной выше, MAI-DxO полностью имитирует процесс посещения врача в больнице.
- Начиная с консультации, MAIN-DxO получает краткую клиническую историю, обычно состоящую из 2-3 предложений, охватывающую основные детали случая.
- Далее MAI-DxO начнет обобщать основные требования пациента и выберет следующий шаг: продолжать задавать пациенту вопросы или запросить обследование.
- Рассчитывается стоимость каждого обследования, и продолжаются несколько раундов взаимодействия до тех пор, пока не будет поставлен окончательный диагноз.
В процессе тестирования MAI-DxO использовала o4-mini и профессиональных врачей для создания «контролера», который должен был гарантировать, что информация, которую система передает ИИ, совпадает с информацией, которую обычные врачи могут получить во время консультаций и клинической практики.
Появление MAI-DxO значительно улучшило производительность больших языковых моделей в медицинской диагностике. Microsoft протестировала различные модели из серий OpenAI, Gemini, Claude, Grok, DeepSeek и Llama, и производительность оказалась лучше, чем при использовании только одной модели ИИ. Лучшей комбинацией оказалась пара MAI-DxO и OpenAI o3.
Поскольку MAI-DxO не ограничен большими языковыми моделями, он также может синхронно адаптироваться, когда в будущем появятся более совершенные модели.
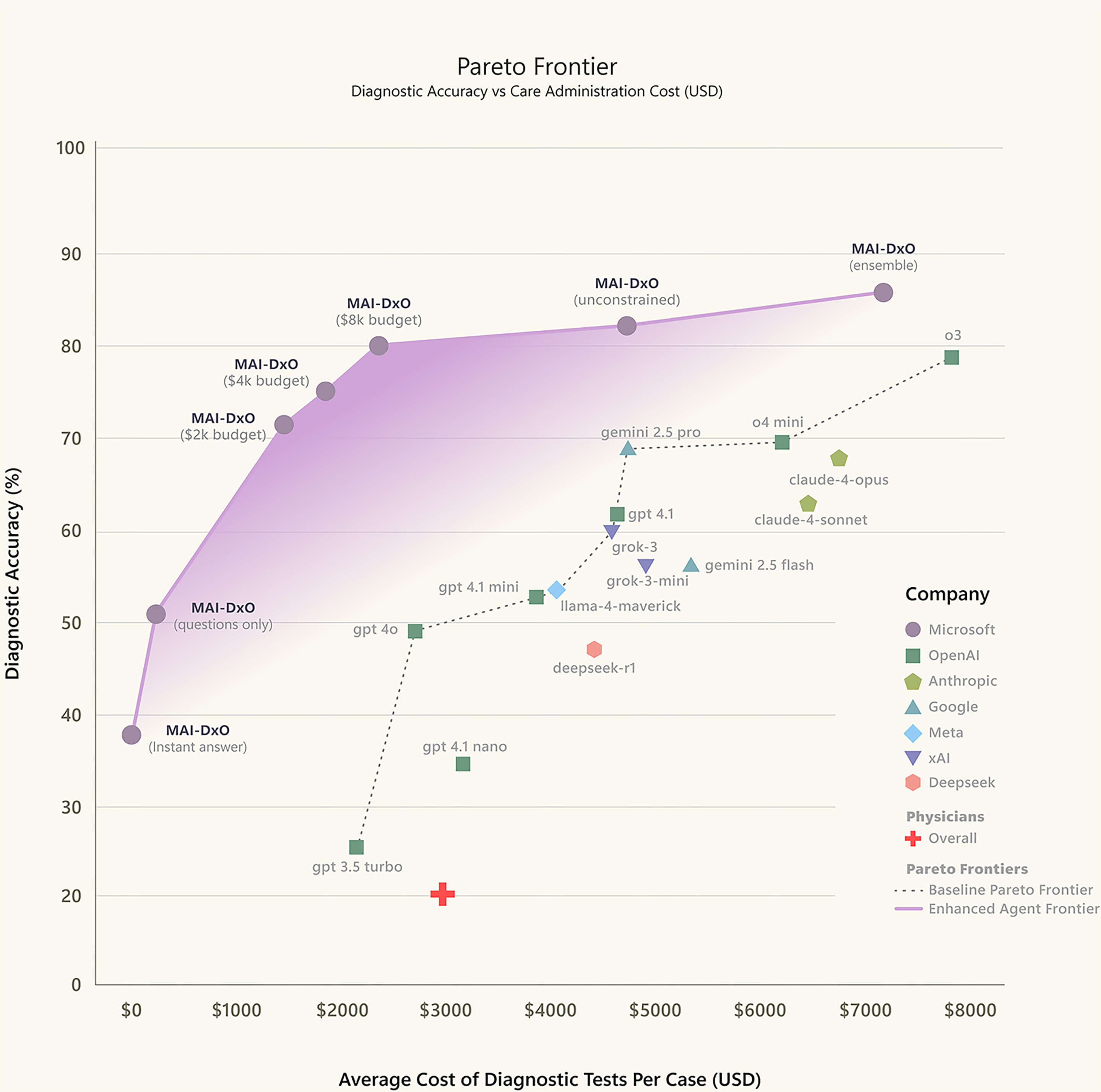
▲Сравнение точности различных моделей искусственного интеллекта и средней стоимости диагностического теста на случай
Хотя, похоже, что «искусственный интеллект-врач» уже обрел форму, искусственному интеллекту нелегко быть хорошим врачом.
В конце проектной работы Microsoft упомянула, что это исследование имеет существенные ограничения, в том числе то, что 21 врач, участвовавший в сравнительном эксперименте, не имел доступа к помощи в обсуждении коллег, справочникам, генеративному ИИ и другим ресурсам. Кроме того, эксперимент Microsoft обсуждал только самые сложные проблемы и не проводил дополнительных тестов по нашей общей ежедневной диагностике заболеваний.
Microsoft подчеркивает, что ИИ не заменит врачей, но станет помощником как врачам, так и пациентам.
Но этот помощник для врачей и пациентов продолжает привлекать внимание со всего мира. Еще в марте этого года Microsoft выпустила первого в медицинской отрасли помощника на основе искусственного интеллекта для клинических рабочих процессов — Microsoft Dragon Copilot, который может помочь врачам лучше организовывать файлы клинических случаев.
Медицинская платформа искусственного интеллекта IBM Watson Health от IBM, DeepMind от Google и NVIDIA Clara от NVIDIA привносят новые изменения в медицинские сценарии, такие как медицинское руководство, консультации и патология.
Некоторое время назад Alibaba DAMO Academy также выпустила первую в мире модель искусственного интеллекта для скрининга рака желудка, DAMO GRAPE, которая впервые использовала простые сканирующие КТ-изображения в сочетании с глубоким обучением для выявления ранних очагов рака желудка.
Компания Huawei создала свой медицинский и оздоровительный корпус только в этом году, а на прошлой неделе в сотрудничестве с больницей Ruijin Hospital анонсировала открытую модель патологии RuiPath, которая имеет возможности клинической проверки и охватывает семь распространенных видов рака, включая рак легких.
Медицина требует чрезвычайно высокой точности, и ошибка в 0,01% может иметь серьезные последствия. Это совершенно не похоже на ошибки, которые появляются, когда программисты пишут код.
MAI-DxO имитирует процесс реальной медицинской консультации, и, похоже, путь медицинской помощи с использованием искусственного интеллекта становится все более и более ясным.
От консультаций Baidu до консультаций ChatGPT, я думаю, в будущем, в дополнение к получению результатов обследований в обычных больницах, проверке рейтингов больниц и оплате консультаций у онлайн-врачей, вы также сможете сначала взглянуть на этого «искусственного интеллекта-врача».
#Добро пожаловать на официальный публичный аккаунт WeChat iFanr: iFanr (WeChat ID: ifanr), где вам будет представлен еще более интересный контент как можно скорее.
iFanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo