Превращается ли бизнес-битва в Кремниевой долине в кулинарное соревнование? Цукерберг когда-то лично варил суп, чтобы переманить талантливых специалистов, и заявление OpenAI о том, что её это не беспокоит, — всего лишь притворство.
Когда бекас и моллюск сражаются, выигрывает рыбак. Иногда я даже надеюсь, что мы, пользователи, и есть эти рыбаки: чем жёстче конкуренция среди производителей моделей, тем скорее у нас появится возможность использовать более совершенные модели.
22 декабря 2022 года, через три недели после выпуска ChatGPT, Google стал первым технологическим гигантом, объявившим «красный уровень тревоги» в ответ на угрозу, исходящую от OpenAI.
Вчера, через две недели после выпуска Gemini 3, OpenAI объявила первую «красную тревогу» в связи со значительным увеличением количества моделей Gemini 3.
Когда я впервые увидел новости, я подумал, что OpenAI, возможно, преувеличивает. Я быстро наткнулся на комментарии вроде: «Гордыня предшествует падению» и «Победа и поражение — обычное дело на войне». Но потом я подумал, что так называемая «красная тревога» может быть предназначена только для инвесторов. В конце концов, если OpenAI действительно не сможет стать лидером, то время, необходимое для выхода на прибыльность в 2030 году, будет только увеличиваться.
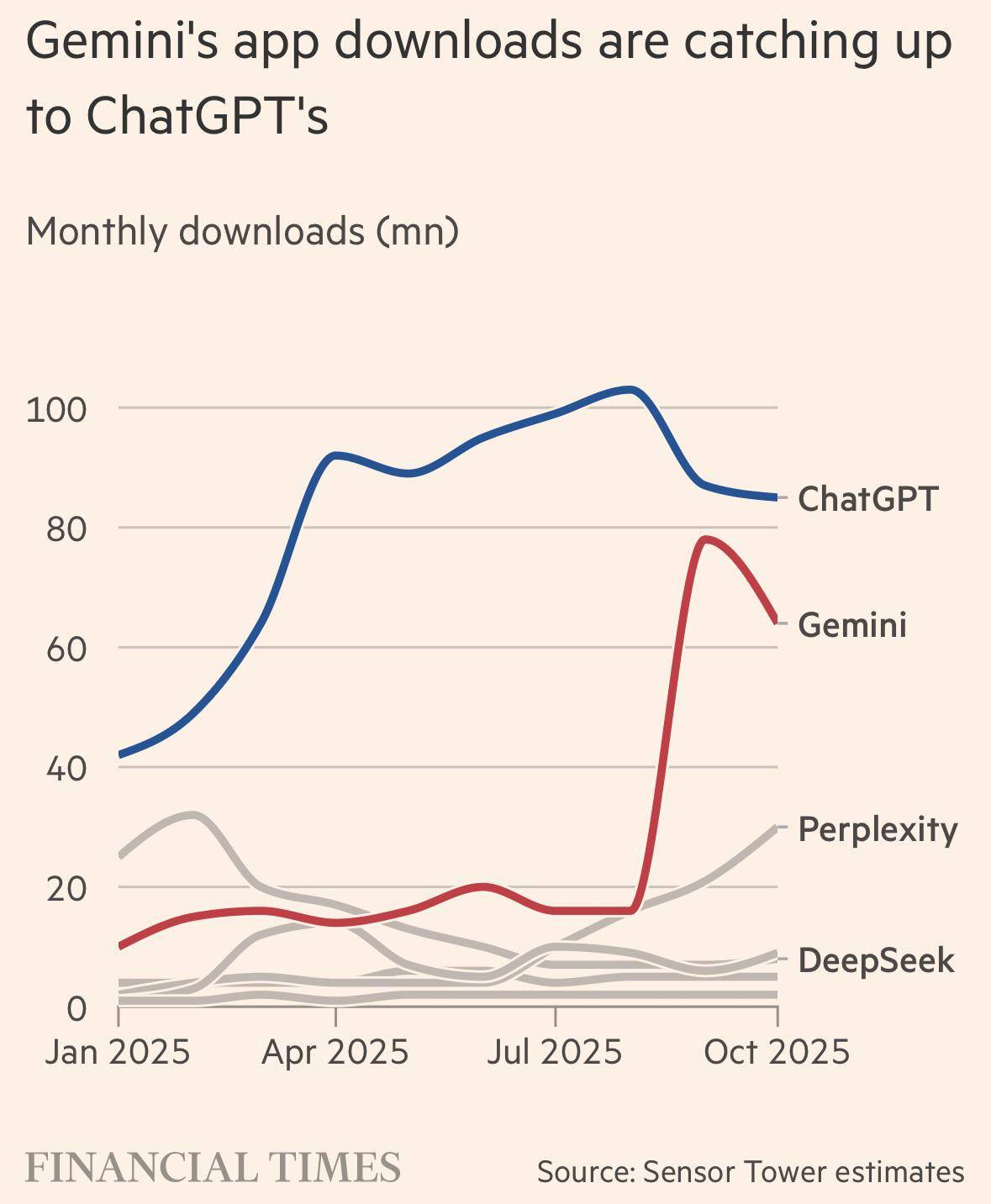
▲ Количество загрузок приложения Gemini почти догнало ChatGPT.
Согласно последним новостям, на следующей неделе OpenAI запустит новую модель вывода, которая, как показали внутренние испытания, превосходит Gemini 3. Кроме того, они планируют контратаковать с помощью модели под кодовым названием «Чеснок».
Однако более реалистичный сценарий заключается в том, что OpenAI неизбежно выпустит лучшую модель, чем Gemini 3, в то время как у Google есть также Gemini 4 и Gemini 5.
На самом деле, если оглянуться на новости из Кремниевой долины за последний год, то это было драматическое и бурное зрелище. В начале года внезапное появление DeepSeek R1 оказало на нас давление; в середине года Цукерберг запустил бешеную «захват талантов», с заоблачными зарплатами, которые перевернули всеобщее представление о талантах в сфере ИИ; а в конце года мы снова оказались втянуты в простую арену соревнования моделей.

В недавнем интервью в подкасте Марк Чен, руководитель исследований OpenAI, описал битву в Кремниевой долине как нечто сюрреалистичное. Он рассказал, что, чтобы переманить к себе центральный мозг OpenAI, Цукерберг даже начал варить суп — в буквальном смысле, пригодный для питья — и лично доставлял его исследователям прямо к дому.
Помимо этих слухов, он также рассказал о взглядах OpenAI на Gemini 3, о том, устарело ли масштабирование, о влиянии DeepSeek R1 на них, о распределении внутренних вычислительных мощностей компании и о сроках достижения AGI.
У Марка Чена весьма интересный бэкграунд: он участвовал в математических соревнованиях, окончил Массачусетский технологический институт, работал в сфере высокочастотной торговли (HFT) на Уолл-стрит и присоединился к OpenAI в 2018 году, чтобы проводить исследования вместе с Ильей. В отличие от Альтмана, который больше склонен к бизнесу, этот опыт сформировал у него совершенно особую черту: крайнюю неприязнь к неудачам и твёрдую веру в математику.
Он признался, что в настоящее время не общается с людьми и вот уже две недели работает до часу или двух ночи каждый день.
Мы составили это полуторачасовое интервью и суммировали ниже основные моменты, которые могут помочь лучше понять различные «битвы» в Кремниевой долине за последний год, а также то, какие усилия OpenAI приложит, чтобы сохранить свои лидирующие позиции в эпоху ИИ.
Что касается «Джемини-3», то мы действительно «не беспокоимся».
Действительно ли OpenAI боится Google? Оценка Марка объективна и одновременно точна. Он признал, что Gemini 3 — хорошая модель, и что Google наконец-то нашла правильный путь. Однако он отметил, что, если взглянуть на детали, такие как данные SWE-bench ( единственный бенчмарк, не занявший первое место в рейтинге Gemini 3 ), Google до сих пор не решила фундаментальную проблему эффективности данных.
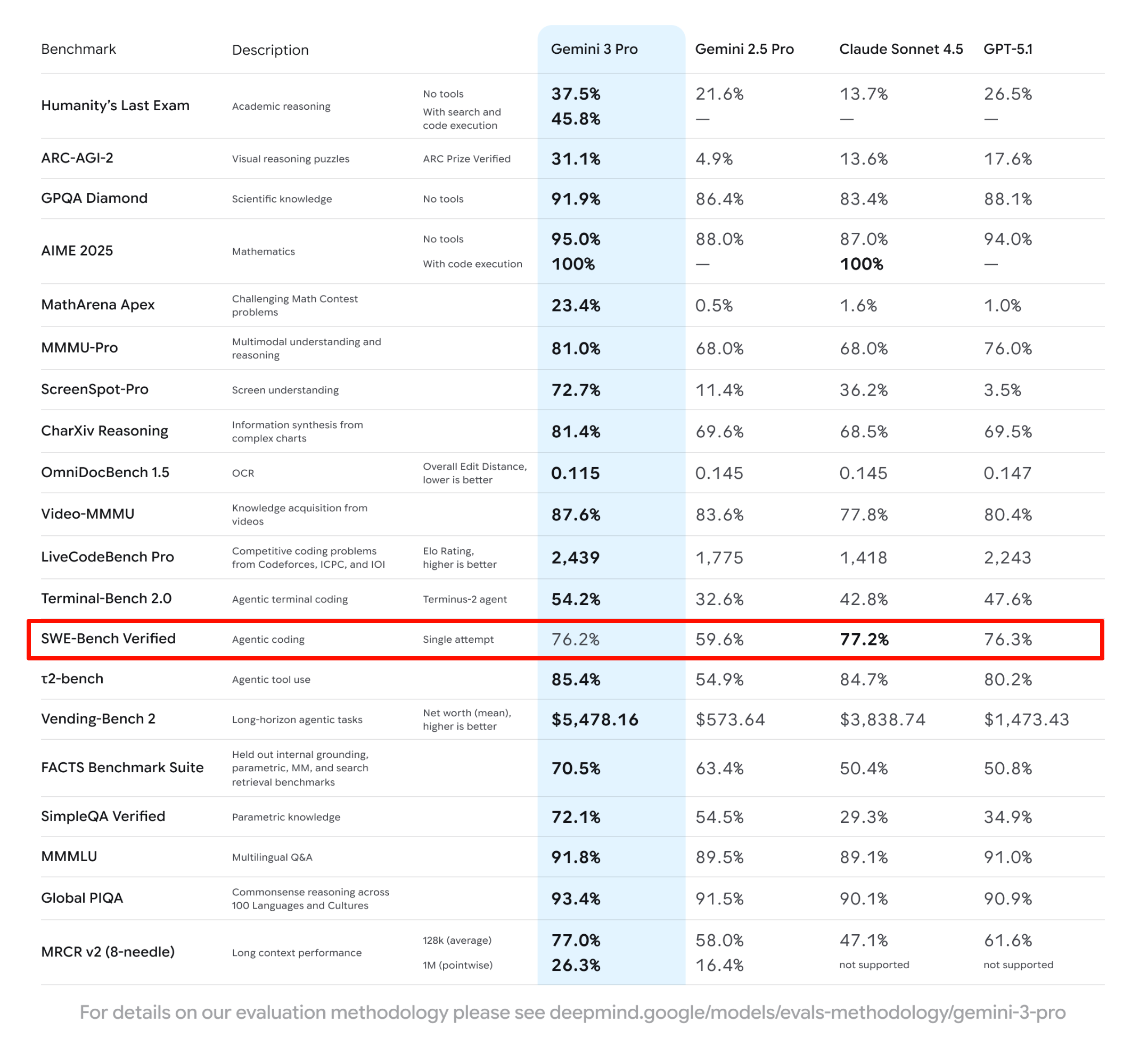
▲Производительность Gemini 3.0 Pro в SWE-Bench оказалась на 0,1% хуже, чем GPT-5.1.
Он сам с большой уверенностью заявил, что у OpenAI уже есть целевая модель для решения этой проблемы , и они уверены, что могут добиться еще большего успеха с точки зрения эффективности данных.
Марк даже сказал, что меморандум, разосланный Альтманом несколько дней назад, в котором говорилось, что все должны чувствовать давление, был призван всех напугать, но на самом деле он скорее создавал ощущение срочности. Он сказал, что это распространённая тактика руководства, и цель меморандума — мотивировать команду, а не вызывать панику.
Думаю, одна из задач Сэма — привить чувство срочности и скорости. Это его обязанность, и это также моя обязанность.
Часть нашей работы как менеджеров заключается в том, чтобы постоянно прививать организации чувство неотложности.

▲Как ранее сообщало издание The Information, при запуске Gemini 3 Альтман разослал внутреннюю служебную записку, в которой упомянул, что это создаст трудности для OpenAI.
Сейчас их самая большая проблема — это распределение вычислительных мощностей . Будучи директором по исследованиям OpenAI, он, в частности, отвечает за распределение вычислительных мощностей между различными проектами компании.
Вместе с Якубом Пахоцки (главным научным сотрудником OpenAI) он отвечает за определение направления исследований OpenAI и определение необходимого объёма вычислительной мощности для каждого проекта. Они проводят анализ каждые один-два месяца.
Они поместили все текущие проекты OpenAI, в общей сложности около 300, в огромную таблицу; затем они постарались максимально понять каждый проект, приоритизировали их, а затем распределили графические процессоры в соответствии с этой таблицей приоритетов.

▲ Сотрудничество NVIDIA и OpenAI над миллионом графических процессоров
Он также упомянул, что на самом деле большую часть ресурсов графических процессоров потребляет не обучение самой важной выпущенной модели, а внутренние эксперименты, исследующие следующее поколение парадигм ИИ.
Поэтому, по его мнению, выпуск Gemini 3, бенчмаркинг определённой модели с открытым исходным кодом и новый рекорд, достигнутый определённой моделью мышления, не имеют значения . Напротив, больше всего следует избегать того, чтобы эта конкуренция сбивала с пути.
Он сказал, что при нынешнем уровне развития моделей мы можем легко опережать лидеров на недели или месяцы, внеся лишь «небольшое обновление». Но если мы вложим все ресурсы в эти краткосрочные итерации, никто не будет искать следующее поколение парадигм. И как только кто-то их найдёт, всей отрасли придётся следовать этому новому пути всё следующее десятилетие.
Просто шёпотом: я предсказываю, что релиз модели OpenAI на следующей неделе будет просто незапланированным обновлением, которое обновит несколько таблиц лидеров. Вы ещё не волнуетесь?

Обсуждая рейтинги, он упомянул, что у него есть собственный набор частных задач для проверки того, действительно ли модель обладает математической интуицией высшего уровня. Он привёл математическую задачу из 42 пунктов, отметив, что современные языковые модели, включая модели мышления O1, могут приблизиться к оптимальному решению, но никогда не решали его полностью.
Вы хотите создать генератор случайных чисел по модулю 42. У вас есть несколько простых чисел, которые делятся по модулю 42. Цель — сгенерировать этот генератор по модулю 42 с минимальным количеством вызовов.
Помимо обсуждения Gemini 3, ведущий также спросил его, что он думает о DeepSeek.
Как и в случае с Gemini 3, Марк признал, что модель открытого исходного кода DeepSeek оказала на них давление и даже заставила их усомниться в том, что они движутся по неверному пути.
Вывод — придерживайтесь своего пути, не позволяйте действиям конкурентов сбивать вас с пути и сосредоточьтесь на собственной дорожной карте. OpenAI не станет компанией-подражателем; её цель — определить следующую парадигму.
У Ilya большой потенциал масштабирования, а OpenAI нуждается в масштабной предварительной подготовке.
В последнее время активно обсуждается провал масштабирования. Илья сначала заявил в подкасте, что эпоха масштабирования закончилась, а затем в социальных сетях пояснил, что масштабирование продолжит приносить некоторые улучшения и не стоит на месте.
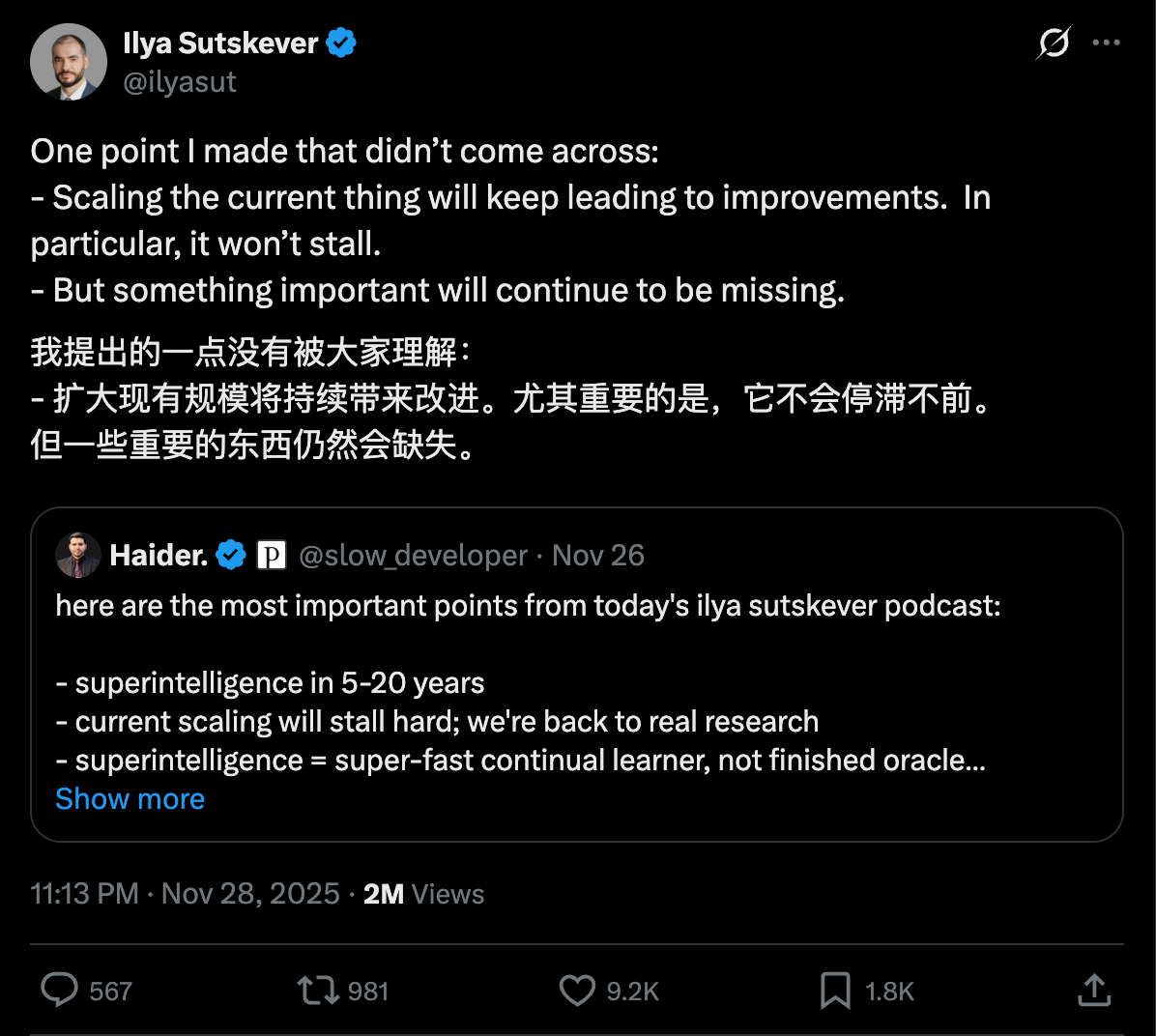
Так называемый закон масштабирования следует классическому нарративу: с учётом огромной вычислительной инфраструктуры, созданной в последние годы, каждое десятикратное увеличение вычислительной мощности должно было приводить к значительному скачку вперёд. Однако при переходе от GPT-4 к GPT-5 ожидаемый «качественный скачок» не осуществился, что привело к разговорам о том, что «закон масштабирования не сработал». Недавнее интервью Ильи ещё больше укрепило эту точку зрения.
Марк Чен решительно опроверг эту точку зрения, заявив: «Мы совершенно не согласны». Он рассказал, что OpenAI за последние два года вложила огромные ресурсы в вывод, что привело к небольшому ухудшению качества предварительной подготовки. Предыдущие проблемы с предварительной подготовкой GPT-5 были связаны с их акцентом на вывод , а не с тем, что закон масштабирования перестал действовать.
Его задача — распределять вычислительные ресурсы, и он повторил, что вычислительная мощность никогда не будет избыточной. Если бы сегодня вычислительной мощности было в три раза больше, он мог бы использовать её всю немедленно; если бы сегодня вычислительной мощности было в десять раз больше, он мог бы полностью использовать её в течение нескольких недель. Для него спрос на вычислительные мощности реален, и он не видит признаков его снижения.
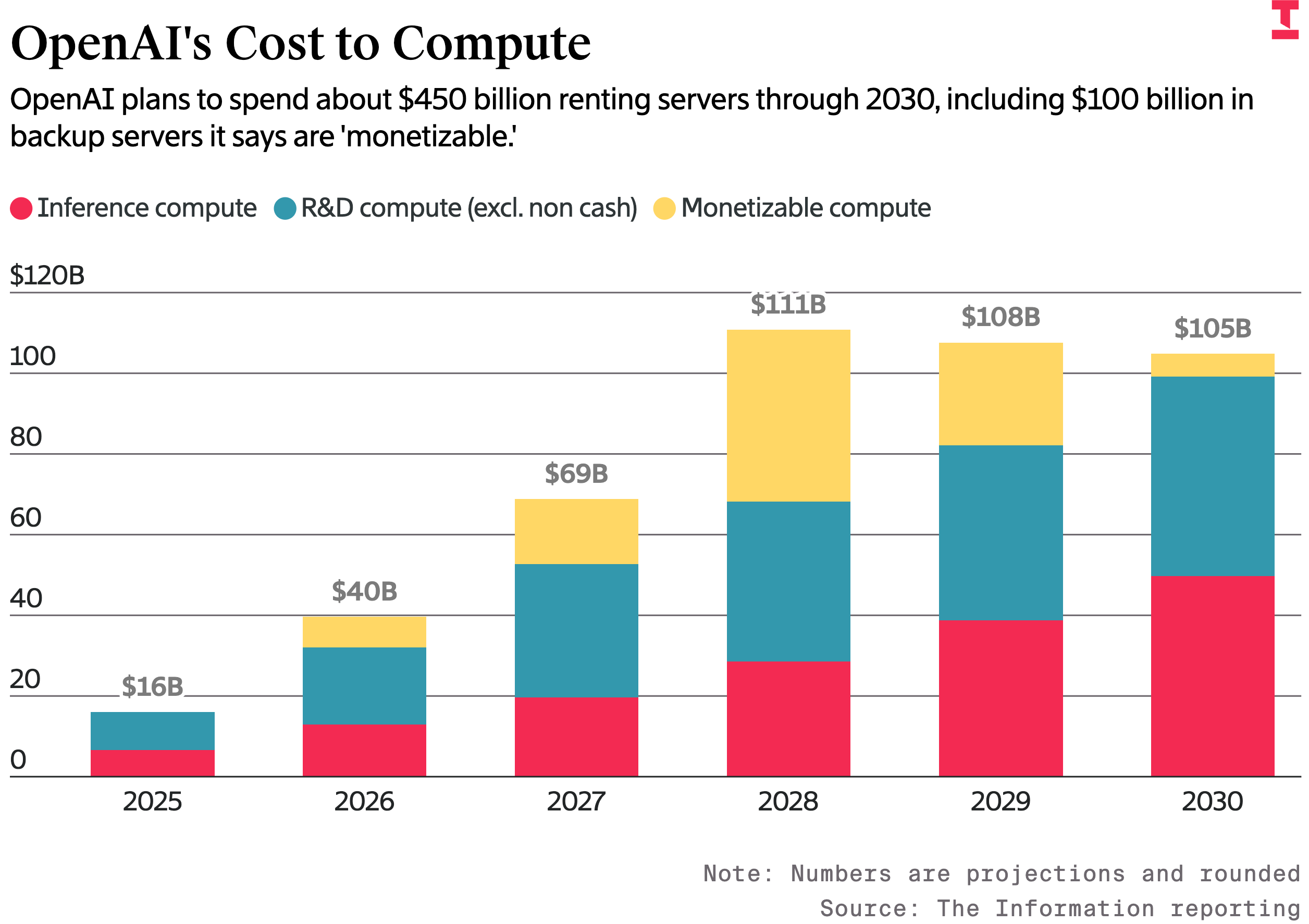
▲ Вычислительные расходы OpenAI: к 2030 году компания планирует потратить около 450 миллиардов долларов на аренду серверов. Красный цвет отображает затраты на вычисления для вывода, синий — на НИОКР (исключая денежные операции), а желтый — на прибыльные вычисления.
Он также упомянул, что за последние шесть месяцев он и главный научный сотрудник OpenAI Якуб Пачоцки снова сосредоточились на изменении доминирующей роли предварительной подготовки .
Он прямо заявил, что они продолжат разрабатывать масштабируемые модели и что был достигнут ряд алгоритмических прорывов, специально разработанных для того, чтобы сделать масштабирование более экономически эффективным, извлекая большую производительность при той же вычислительной мощности и сохраняя эффективность данных при более высокой вычислительной мощности.
Душевный суп Цукерберга не сравнится с мотивационным посланием OpenAI.
Наконец, вот сплетня, упомянутая в интервью. В этом году у Meta не было других новостей, но СМИ целый квартал раскручивали тему «масштабной утечки мозгов специалистов OpenAI/Apple/Google в Meta». Марк Чен напрямую затронул эту тему в подкасте, и подробности были почти «возмутительными».
По его словам, Цукерберг действительно шёл на всё: чтобы переманить талантливых сотрудников, он не только писал электронные письма от руки, но и лично разносил куриный суп. Война талантов в итоге превратилась в метаигру «кто лучше сварит суп».
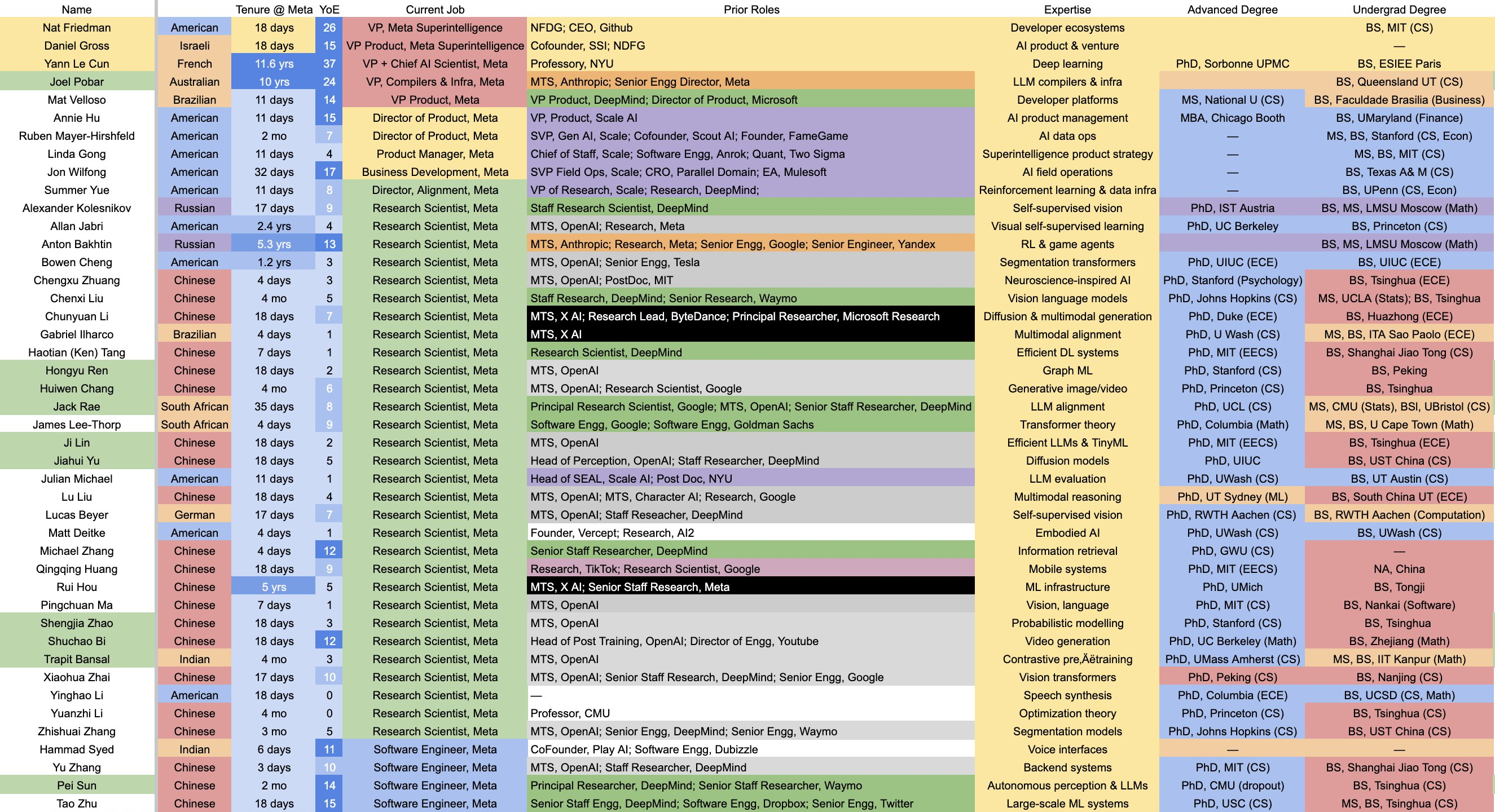
▲ Список суперлабораторий интеллекта Меты, созданных с помощью огромных сумм денег, потраченных на переманивание талантов
Однако Мета пытался переманить половину своих непосредственных подчинённых, но все они предпочли остаться. Почему же они не ушли? Не из-за денег, ведь Мета, очевидно, предлагал больше, а из-за своих убеждений .
Марк сказал, что даже те, кто перешёл в Meta, не осмелились сказать: «Meta создаст ИИОН раньше OpenAI». Те же, кто остался в OpenAI, сделали это, потому что искренне верили, что именно здесь зародился ИИОН.
Он также упомянул, что, исходя из своего опыта работы на Уолл-стрит и игры в покер, он понял, что на самом деле нужно удерживать именно ключевых специалистов, а не каждого отдельного человека . Как только вы поймёте, какие люди вам абсолютно необходимы, вы сможете сосредоточить все свои ресурсы и внимание на этой группе.
Он сказал, что его самым сильным чувством было желание «сохранить инстинкт исследователя». Когда Барретт (вице-президент по исследованиям OpenAI) ушёл, он даже месяц ночевал в своём кабинете, чтобы исследовательская группа не сбивалась с пути.
▲ Баррет и Мира (бывший технический директор OpenAI) в настоящее время работают в Thinking Machines.
Так что же такое AGI, в который верит OpenAI? Ведущий спросил его: «Андрей Карпати сказал в недавнем подкасте, что AGI, вероятно, появится ещё через 10 лет. Что вы думаете?»
Марк сначала в шутку прокомментировал разнообразные «потрясающие» тексты от X, где фразы «ИИ завершён» чередуются с фразами «ИИ снова жизнеспособен». Он считает, что у каждого своё понимание ИИ, и даже внутри OpenAI сложно выработать единое определение. Но он верит в цели, которые OpenAI поставила перед ИИ.
- В течение года: изменить характер исследований. Сейчас исследователи пишут код и проводят эксперименты самостоятельно. Через год основной задачей исследователей станет управление стажёрами, работающими с ИИ. ИИ должен быть эффективным помощником, выполняющим большинство специфических задач.
- В течение 2,5 лет: достичь полной автоматизации исследований . Это означает, что люди отвечают только за выдвижение идей (проектирование верхнего уровня), в то время как ИИ отвечает за реализацию кода, отладку, обработку данных и анализ результатов, образуя замкнутый цикл.
От второго пилота до ученого Марк подчеркивает, что цель OpenAI for Science заключается не в получении Нобелевской премии как таковой, а в создании набора инструментов, которые позволят современным ученым ускорить свою работу одним щелчком мыши, даже если это потребует реструктуризации всей системы научной оценки, поскольку в будущем может быть сложно отличить, было ли открытие сделано человеком или ИИ.
Два с половиной года могут показаться коротким сроком, но для индустрии ИИ, которая теперь обновляется еженедельно, это долгий марафон.
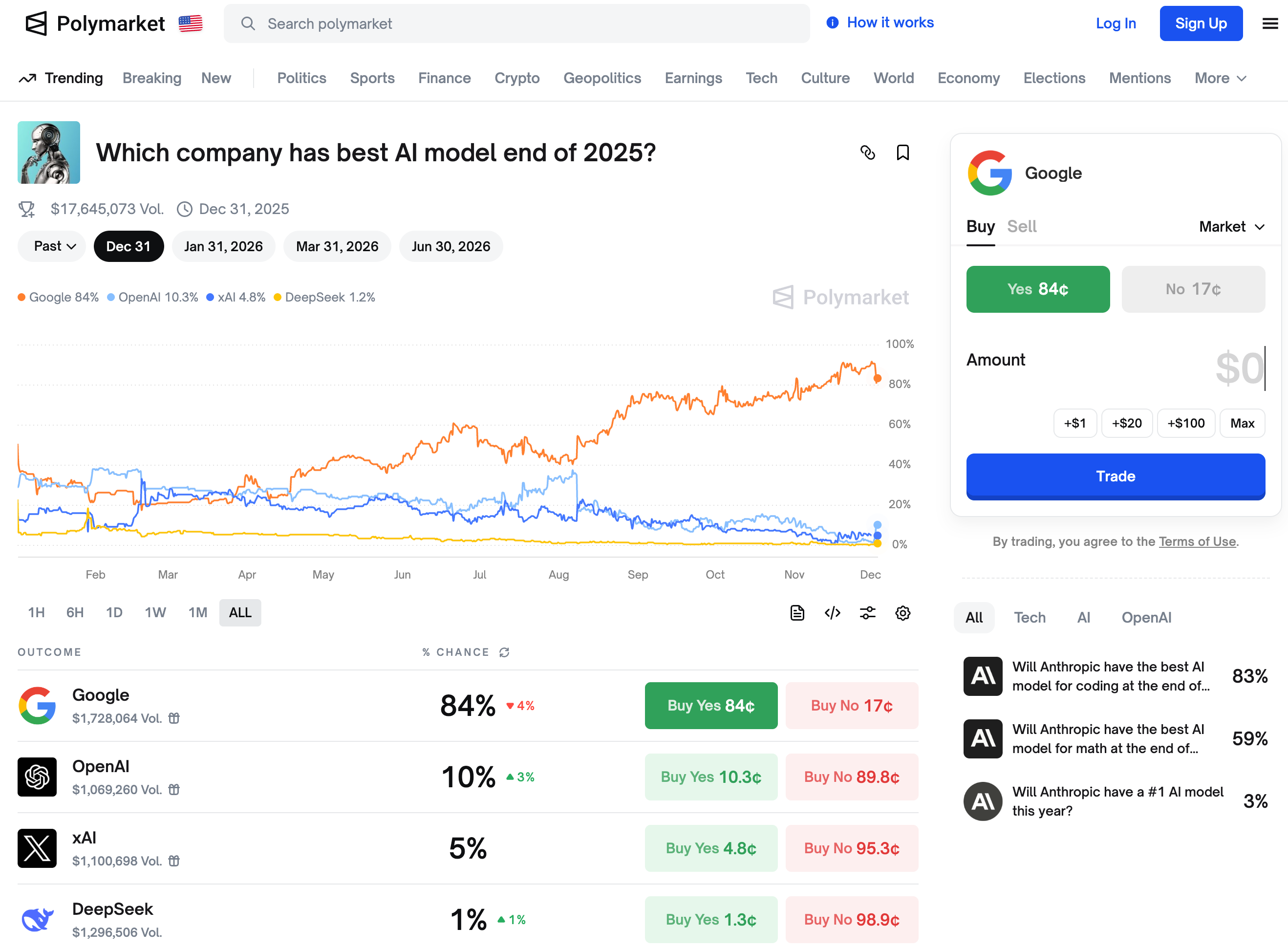
▲ Согласно прогнозам рынка, Google занимает первое место как компания, которая к концу 2025 года выпустит лучшую модель ИИ.
Будь то прибыльные, но в конечном счёте пустые обещания Цукерберга или идеалистическое видение будущего OpenAI, эта «драма» Кремниевой долины далека от завершения. Спокойствие Марка Чена в его подкасте, возможно, смягчит некоторые внешние опасения, но пользователи в конечном итоге проголосуют ногами; хорошие модели будут говорить сами за себя.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (WeChat ID: ifanr), где вы сможете как можно скорее получить еще больше интересного контента.
ifanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo