Персональный суперкомпьютер за 30 000 долларов, подаренный Дженсеном Хуангом Илону Маску, требует для бесперебойной работы Mac Studio. Первые реальные демонстрации уже здесь.

Сможет ли эта машина, прозванная «самым маленьким суперкомпьютером в мире», с 200 миллиардами параметров, 30 000 юаней и 128 ГБ памяти действительно позволить нам запускать большие модели на наших настольных компьютерах?

▲ Изображение от x@nvidia
Несколько дней назад Дженсен Хуан официально передал этот суперкомпьютер Илону Маску, а затем лично посетил штаб-квартиру OpenAI, чтобы представить его ему. От дебюта на выставке CES до текущего использования этот персональный суперкомпьютер наконец-то попадает к нам в руки.
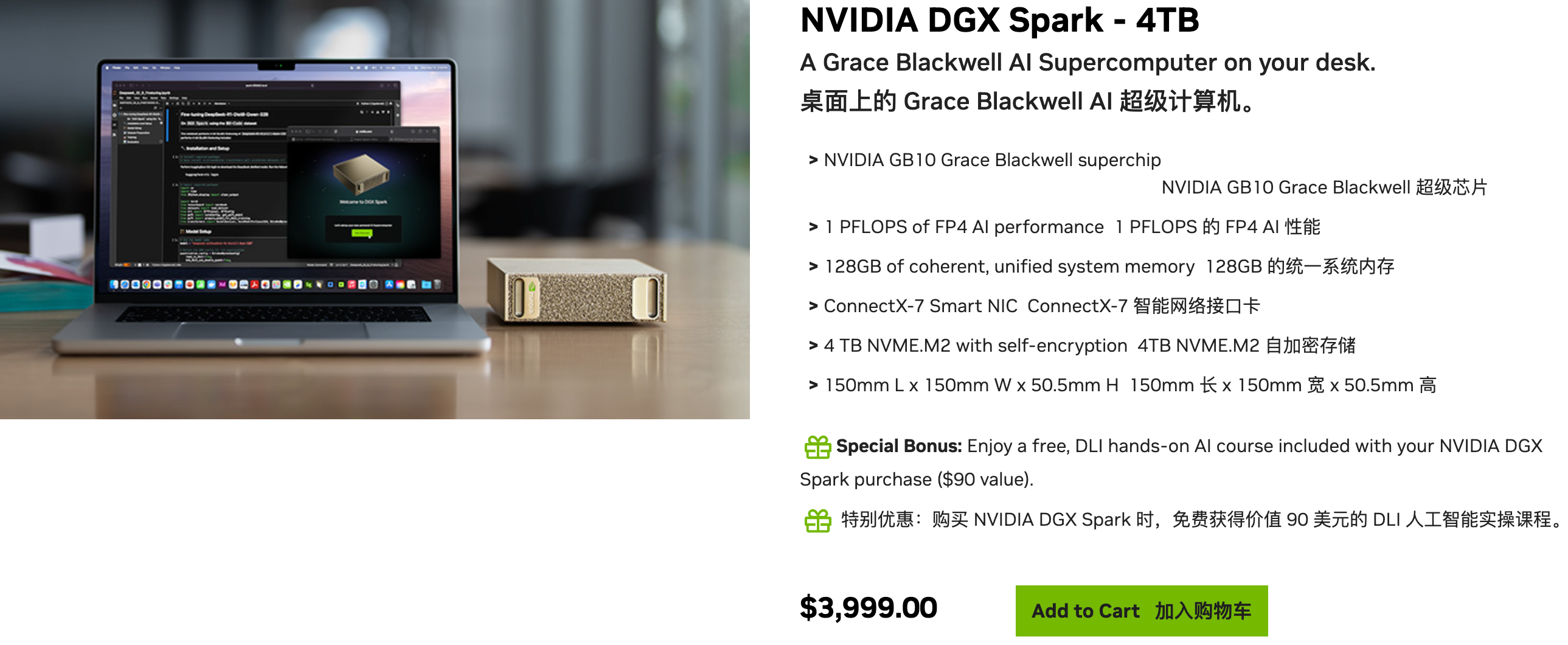
▲Информация о продажах на официальном сайте: цена составляет 3999 долларов США, также предлагаются версии от семи компьютерных брендов, включая ASUS, Lenovo и Dell; ссылка: https://marketplace.nvidia.com/en-us/developer/dgx-spark/
NVIDIA DGX Spark — это персональный суперкомпьютер на базе ИИ, разработанный для исследователей, специалистов по обработке данных и студентов. Он предоставляет им высокопроизводительные возможности ИИ-вычислений на уровне настольных компьютеров, помогая им разрабатывать и совершенствовать модели ИИ.
Звучит мощно, но обычные люди не могут придумать ничего более, чем:
- Запускайте большие модели локально: содержание ваших разговоров с ним остается только на вашем компьютере, что обеспечивает абсолютную безопасность.
- Создавайте контент локально: создавайте изображения и видео без ограничений, попрощайтесь с членством и баллами.
- Создайте личного помощника: дайте ему всю необходимую информацию и обучите «Джарвиса», который понимает только вас.
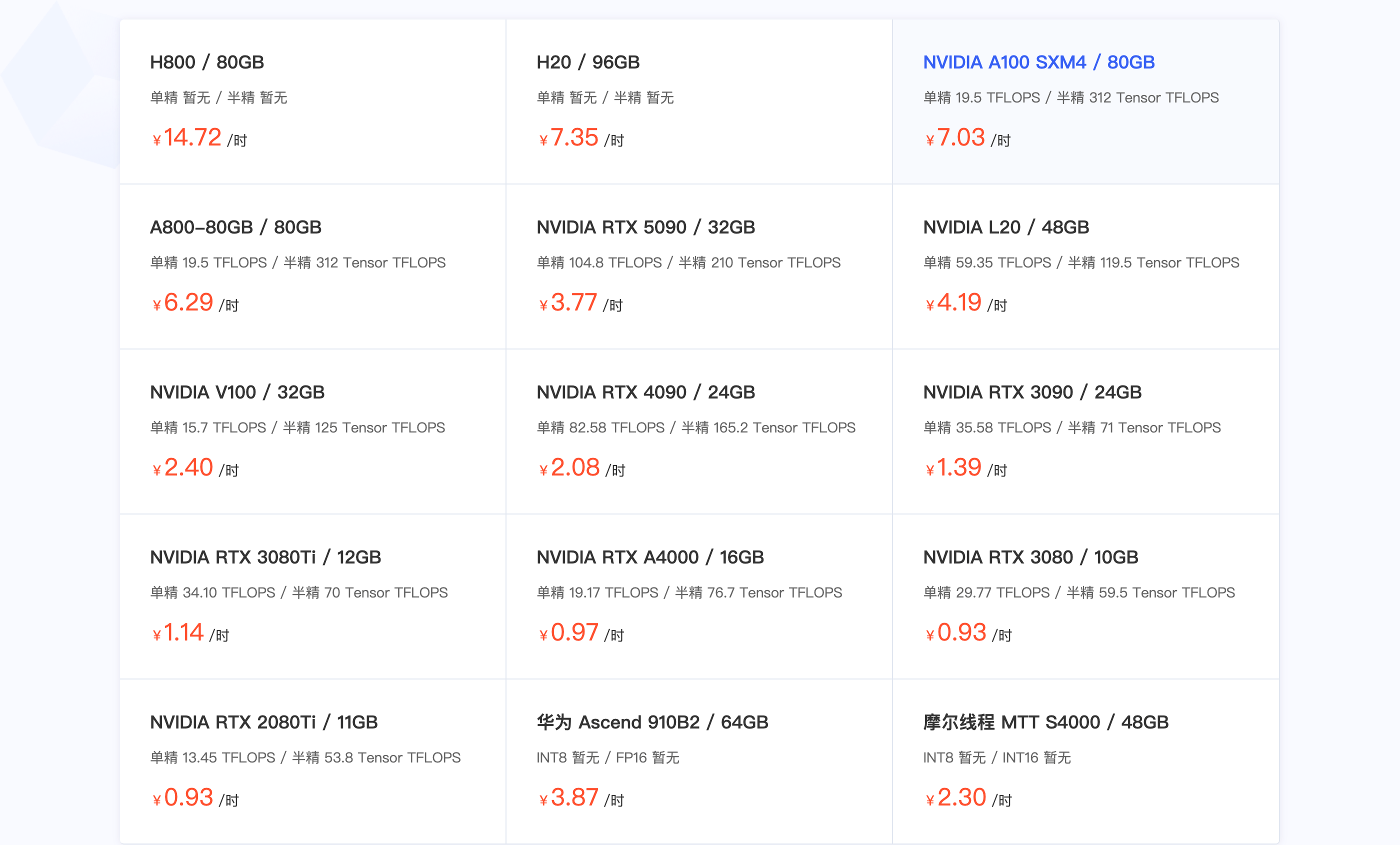
▲ На некоторых платформах аренды видеокарт стоимость A100 составляет 7 юаней/час.
На самом деле, возможности суперчипа DXG Spark GB10 Grace Blackwell могут расширить его возможности, но что именно он может делать? И насколько хорошо он это делает? С ценой в 30 000 юаней и возможностью аренды A100 на 4000 часов, станете ли вы ставить его на стол для запуска крупных моделей?
Мы собрали несколько подробных обзоров DGX Spark в сети, и прежде чем приступить к его реальному тестированию, мы хотели бы показать вам, стоит ли это устройство 30 000 юаней.
Краткая версия:
- Позиционирование производительности: лёгкие модели работают исключительно хорошо, а крупные модели со 120 миллиардами параметров также могут работать плавно. В целом, производительность видеокарты находится между будущей RTX 5070 и RTX 5070 Ti.
- Самый большой недостаток: пропускная способность памяти в 273 ГБ/с является ограничивающим фактором. Вычислительной мощности достаточно, но передача данных медленная. Ощущение такое, будто мозг работает молниеносно, а речь заикается.
- Необычный подход: использование Mac Studio M3 Ultra в качестве «помощника». DGX Spark отвечает за быстрое мышление, а Mac Studio — за беглость речи, принудительно решая проблему «заикания».
- Богатая экосистема: на официальном сайте представлено более 20 готовых к использованию функций — от создания видеороликов до разработки многоагентных помощников. Вам предоставлена целая экосистема ИИ.

Лишь немного лучше Mac Mini?
Без лишних слов, давайте взглянем на данные.
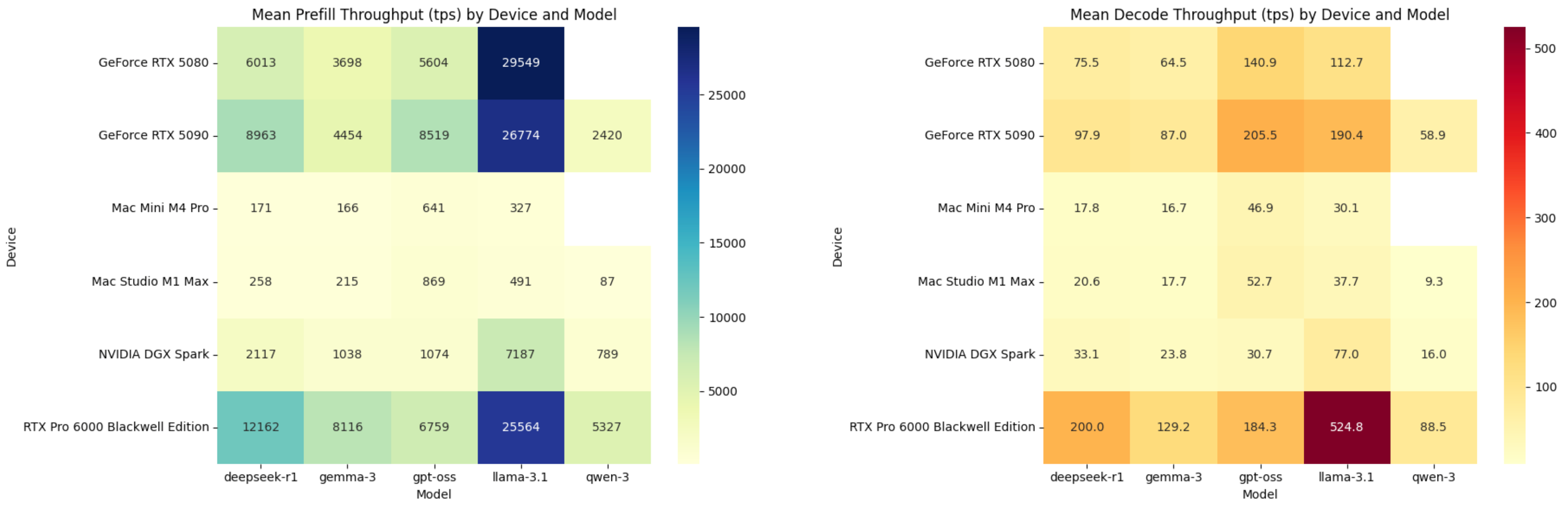
▲ Среднее количество токенов, обрабатываемых в секунду при дополнении и декодировании; DGX Spark находится после RTX 5080. Изображение создано ChatGPT.
DGX Spark значительно мощнее Mac Mini M4 Pro, особенно на этапе предзаполнения. Однако на этапе декодирования преимущество не столь очевидно. Mac Mini M4 Pro достигает 17,8 транзакций в секунду на модели DeepSeek R1 с открытым исходным кодом, тогда как DGX Spark — только 33,1.
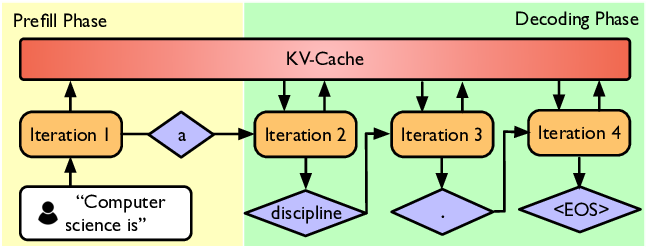
Давайте быстро определим два этапа рассуждений ИИ.
Проще говоря, когда мы вводим вопрос в окно чата ИИ, процесс генерации ответа моделью можно разделить на два ключевых этапа:
1. Предварительное заполнение (этап понимания прочитанного)
Получив наш вопрос, ИИ быстро считывает и понимает каждое введенное вами слово (т. е. слова-подсказки).
Чем быстрее выполняется этот этап, тем меньше времени требуется, чтобы ИИ произнес первое слово. Эта метрика часто используется для продвижения возможностей ИИ: время ответа на первое слово, или TTFT (Time To First Token).
2. Декодирование (этап генерации ответа)
Как будто ИИ уже нашел ответ и начинает печатать его для нас слово за словом.
Скорость ввода данных ИИ определяется показателем TPS (число транзакций в секунду). Чем выше это значение, тем быстрее отображается полный ответ.
Советы: Что такое TPS?
TPS означает Tokens Per Second (токены в секунду), что можно понимать как эффективность ИИ или скорость набора текста.
TPS на этапе предварительного заполнения: показывает скорость, с которой ИИ понимает вопрос.
TPS на этапе декодирования: показывает скорость, с которой ИИ генерирует для нас ответы.
 Советы: Что такое TPS?
Советы: Что такое TPS?
Итак, когда DGX Spark ответил на наши вопросы, первое слово он напечатал быстро, но потом скорость печати стала очень низкой. Стоит отметить, что Mac Mini M4 Pro с 24 ГБ стандартной памяти стоит всего 10 999 юаней.
Почему? Этот тест был проведён командой LMSYS из проекта Large Model Arena, которая выбрала шесть различных устройств, показанных на изображении выше, и запустила несколько моделей больших языков с открытым исходным кодом в своём проекте SGLang и Ollam.

▲ SGLang — высокопроизводительная среда вывода, разработанная командой LMSYS. FP8, MXFP4, q4_K_M и q8_0 относятся к форматам квантования больших языковых моделей, т. е. к сжатию больших моделей и использованию различных методов двоичного хранения.
Тесты включали большую локальную модель со 120 миллиардами параметров и меньшую модель с 8 миллиардами параметров. Кроме того, размер пакета и различия между фреймворками SGLang и Ollam по-разному влияют на производительность DGX Spark.
Например, группа по обзору отметила, что DGX Spark декодировал всего 20 единиц в секунду, когда размер пакета был равен 1, но когда размер пакета был установлен на 32, количество единиц, декодируемых в секунду, возросло до 370. В общем случае, чем больше размер пакета, тем больше контента необходимо обрабатывать каждый раз и тем выше требования к производительности графического процессора.
Благодаря архитектуре чипа GB10 Grace Blackwell и производительности разреженных тензоров FP4 в 1 ПФЛОП возможности искусственного интеллекта DGX Spark располагаются между RTX 5070 и RTX 5070 Ti.
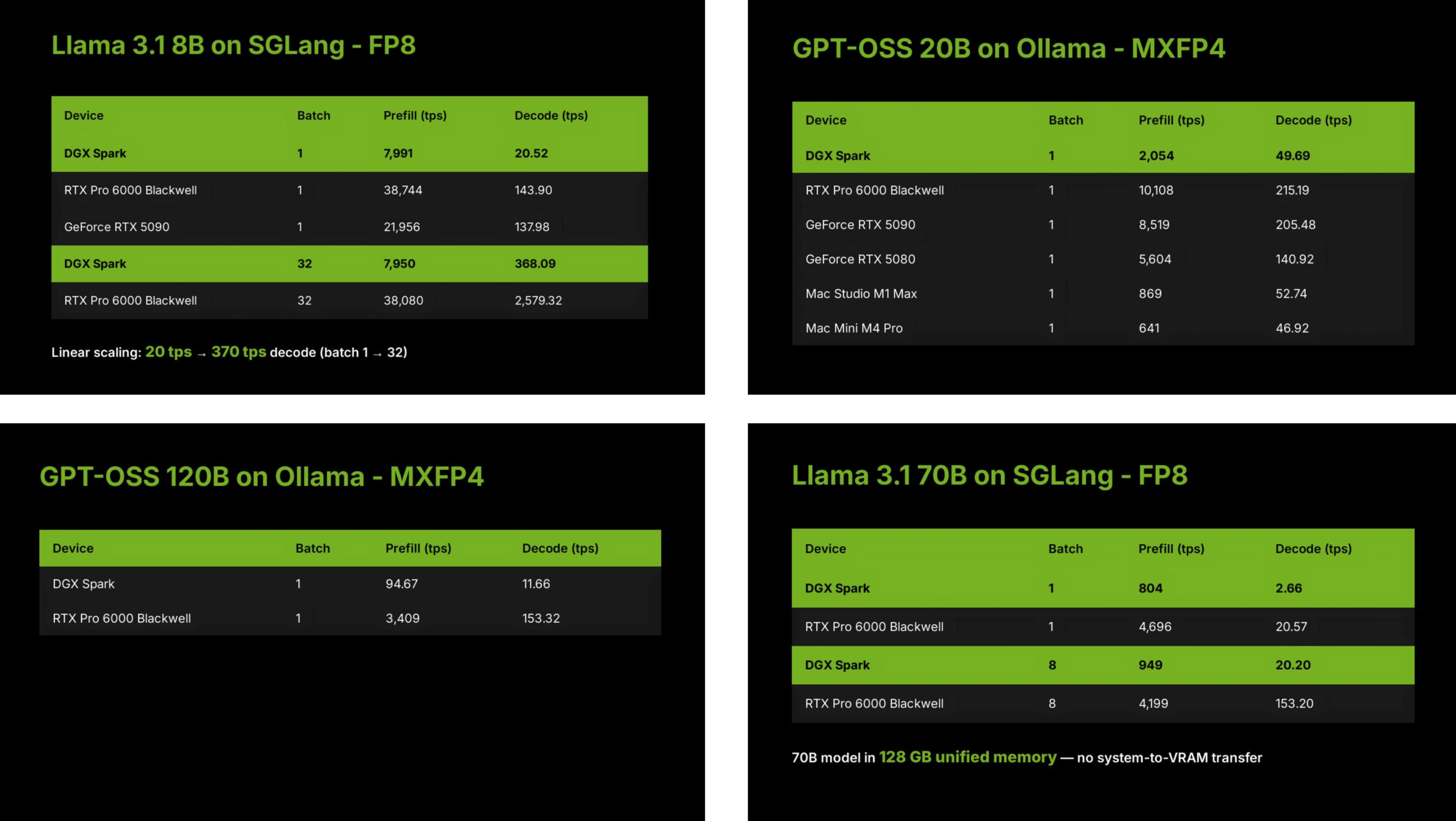
Таким образом, график, показывающий результаты в начале, не отражает в полной мере возможности DGX Spark, поскольку он усредняет результаты всех модельных тестов. Однако итоговая производительность будет варьироваться в зависимости от размера пакета вывода модели и её параметров.
Подводя итог, можно сказать, что преимущества DGX Spark таковы:
- Высокая вычислительная мощность: способность обрабатывать большие пакеты задач, основные возможности ИИ на уровне RTX 5070.
- Большой объем памяти: благодаря огромному объему памяти в 128 ГБ он может легко обрабатывать большие модели с сотнями миллиардов записей.

Но его слабость фатальна и очевидна — пропускная способность.
Фаза предварительного заполнения посвящена вычислительной мощности (насколько быстро вы можете думать), а фаза декодирования — пропускной способности (насколько быстро вы можете говорить).
Проблема DGX Spark в том, что его мозг (вычислительная мощность) быстр, но его «рот» (пропускная способность) не справляется.
Проще говоря, его канал передачи данных похож на тонкую водопроводную трубу:
- DGX Spark использует память LPDDR5X (обычно используемую в мобильных телефонах и ноутбуках) с пропускной способностью всего 273 ГБ/с.
- Напротив, высокопроизводительная игровая видеокарта RTX 5090 использует память GDDR7 с пропускной способностью до 1800 ГБ/с, что сравнимо с пожарным шлангом.
Это основная причина низкой производительности DGX Spark на этапе декодирования.
LMSYS предоставила подробные результаты оценки в Google Docs. Мы предоставили данные агенту Kimi и получили подробный отчёт с визуализацией, предварительный просмотр необработанных данных. Вы также можете скачать предварительный отчёт Kimi, нажав кнопку загрузки.

▲ https://www.kimi.com/chat/199e183a-7402-8641-8000-0909324fe3fb
Ограничения пропускной способности? Обойдите их, подключившись к экземпляру Mac Studio.
Пропускная способность является узким местом, но еще более продвинутая команда нашла способ выжать всю вычислительную мощность из DGX Spark: найдите настольное устройство с более высокой пропускной способностью, Mac Studio M3 Ultra, и используйте его скорость 819 ГБ/с, чтобы увеличить скорость вывода больших моделей в 2,8 раза.
Компания EXO Lab, получив ранний доступ к двум машинам DGX Spark, напрямую назначила этапы предварительного заполнения и декодирования вывода больших моделей на DGX Spark и Mac Studio соответственно; этот процесс известен как разделение PD.

Подобно этапам предварительного заполнения и декодирования, которые мы рассмотрели ранее, один из них зависит от вычислительной мощности, а другой — от пропускной способности. Как показано на диаграмме выше, жёлтый цвет обозначает этап предварительного заполнения, который определяет время до первого измерения (TTFT), и этап декодирования, который определяет количество транзакций в секунду (TPS).

▲ Подход EXO Lab заключается в передаче декодирования Mac Studio.
Однако реализовать разделение PD непросто. Команде EXO также предстоит решить другую проблему: как передать контент, сгенерированный на этапе предварительного заполнения (кэш KV) на устройстве DGX Spark, на устройство, обрабатывающее декодирование.
Этот фрагмент данных очень большой. Если время передачи между двумя устройствами слишком велико, это может даже свести на нет улучшение производительности.
Ответ EXO: конвейерные многоуровневые вычисления и передача данных. Когда DGX Spark обрабатывает первый уровень предварительного заполнения, вычисленный кэш «ключ-значение» немедленно передаётся в Mac Studio, в то время как DGX Spark продолжает второй уровень предварительного заполнения.
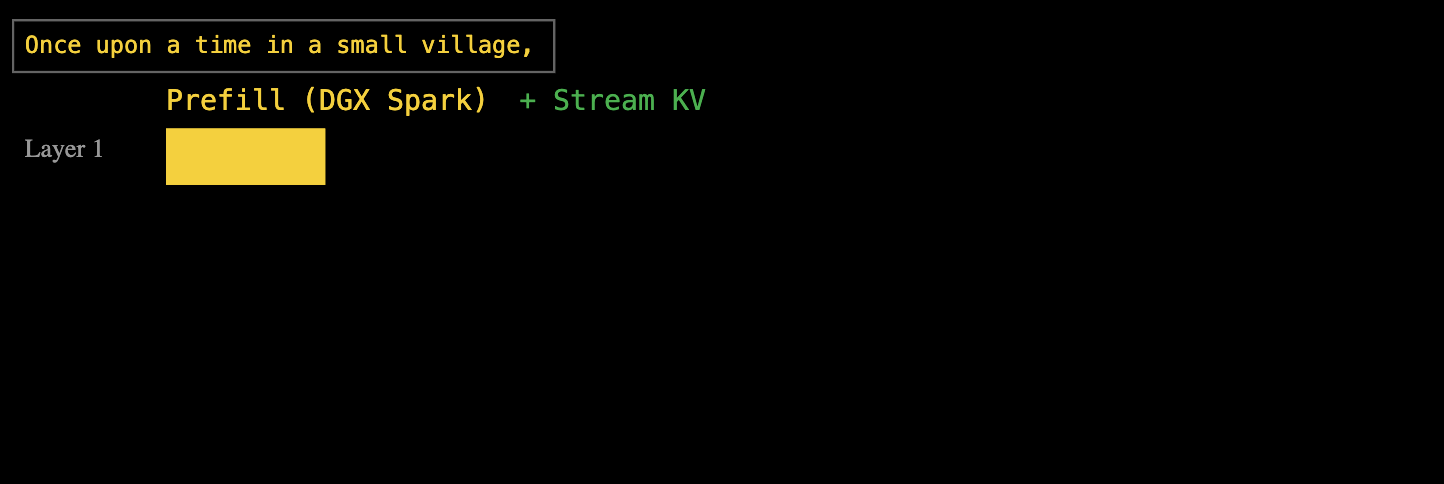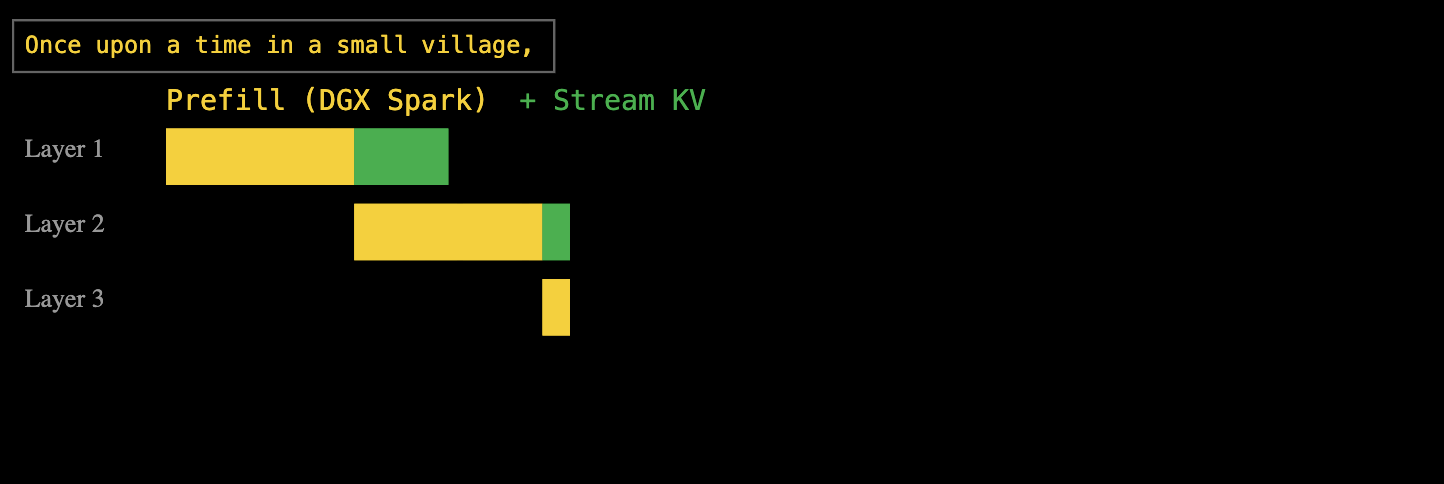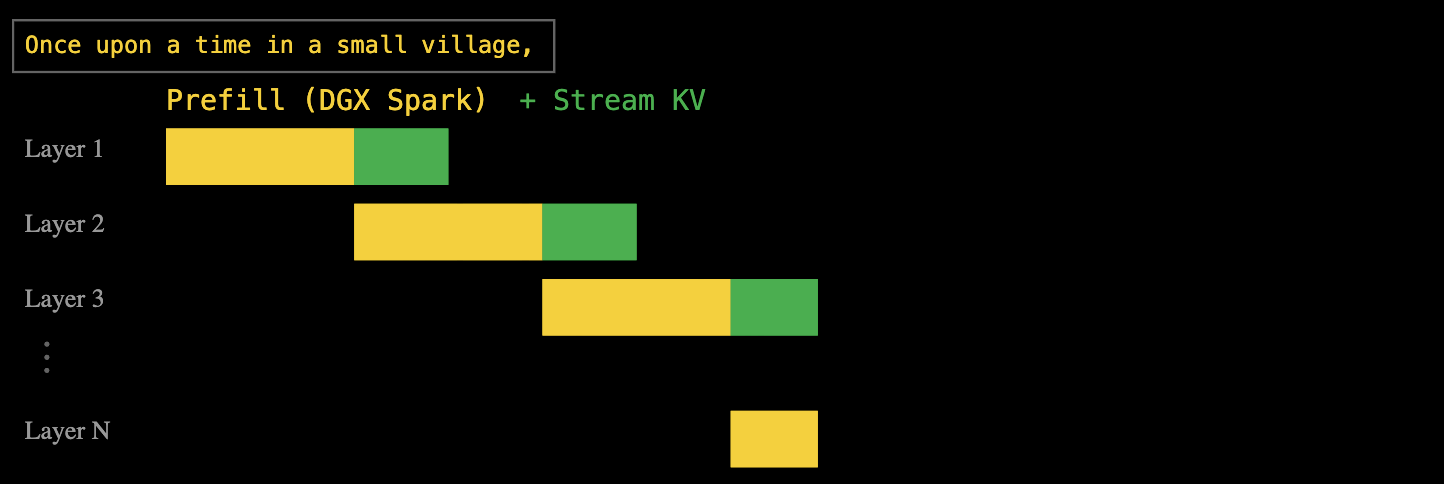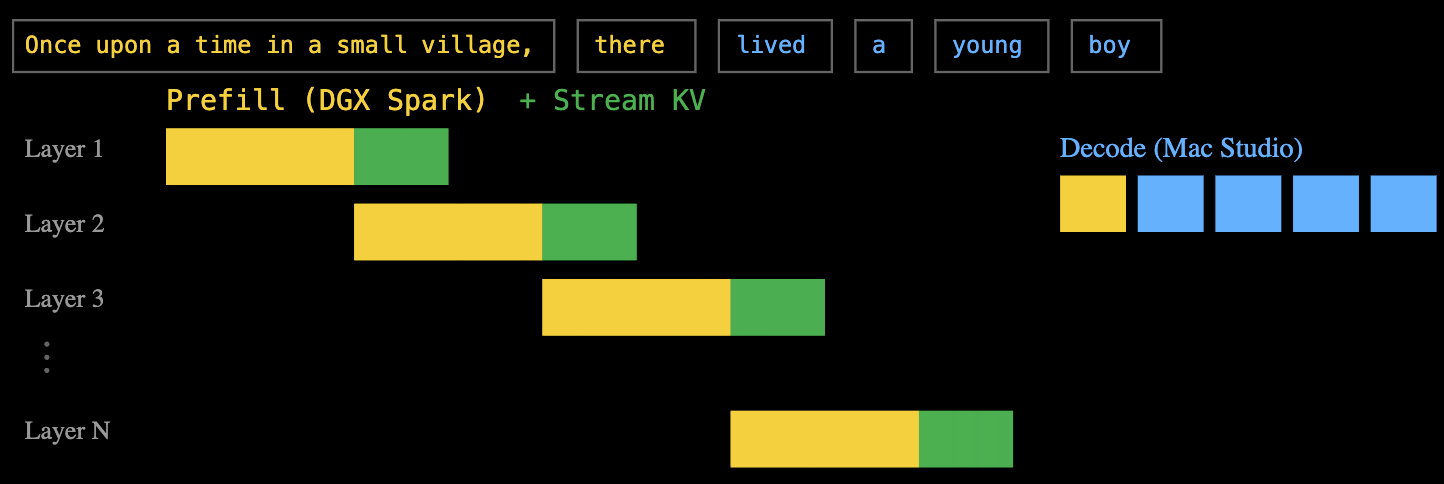
Такой подход с использованием многоуровневого конвейера позволяет полностью перекрывать время вычислений и передачи данных. В конечном итоге, после предварительного заполнения всех слоёв, Mac Studio получает полный кэш пар «ключ-значение» и может немедленно приступить к декодированию.
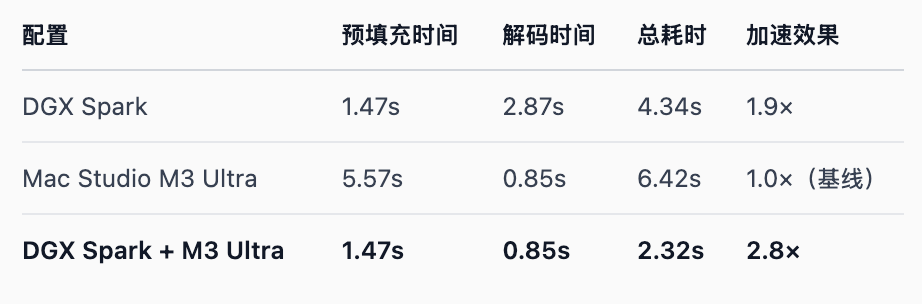
Хотя это решение в некоторой степени решает проблему ограничений пропускной способности DGX Spark, увеличивая скорость в три раза, оно также утраивает стоимость. Общая стоимость двух экземпляров DGX Spark и одного Mac Studio M3 Ultra составляет около 100 000 юаней.
Использовать его для запуска большой локальной модели было бы излишеством.
Что еще можно сделать, помимо тестирования производительности?
Пропускная способность 273 ГБ/с — это не всё, что может предложить DGX Spark. Благодаря 128 ГБ унифицированной памяти, видеокартам с архитектурой GB10 уровня центра обработки данных, поддерживающим 1 петафлопс в секунду, и дизайну уровня настольных компьютеров, он обладает потенциалом для расширения сфер применения.
Мы нашли несколько видеороликов с распаковкой и практическими рекомендациями от пользователей YouTube, чтобы увидеть, на что способно это устройство, учитывая его очевидные сильные и слабые стороны.
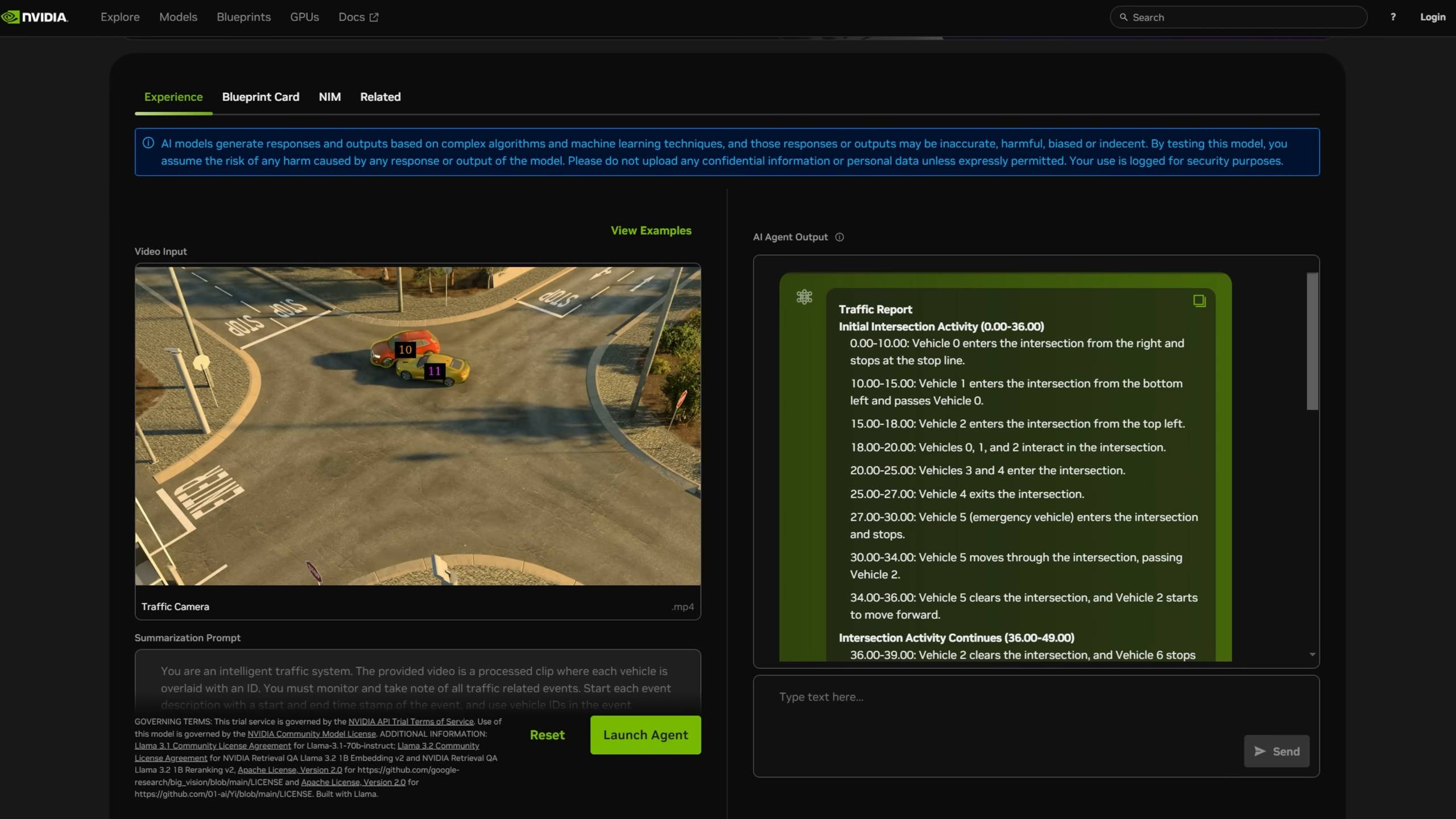
Генерация локального видео с помощью искусственного интеллекта
Большинство текстовых моделей теперь можно использовать бесплатно, но для большинства необработанных видеомоделей требуется платное членство или система баллов.
Блогер BijianBowen использовал фреймворк ComfyUI и модель преобразования текста в видео Wan 2.2 14B от Alibaba, напрямую настроив проект генерации видео на основе официальных DXG Spark Playbooks.
▲ NVIDIA DGX Spark — обзор без спонсорской поддержки (сравнение с Strix Halo, плюсы и минусы) Источник видео: https://youtu.be/Pww8rIzr1pg
В процессе генерации видео он упомянул, что, хотя температура графического процессора достигла 60–70 градусов Цельсия после выполнения команды, не было никакого шума, даже звука вращающегося вентилятора.

▲Большинство блогеров отметили, что DGX Spark действительно относительно «тихий», а разборка устройства довольно аккуратна. (Источник: storagereview.com)
Помимо ComfyUI, который используется для создания видео и изображений, предоставляя руководства по работе с DGX Spark, LM Studio, настольный инструмент для локального запуска больших моделей, также опубликовал запись в блоге, в которой упоминается поддержка DGX Spark.
Использование инструментов для создания многоагентного чат-бота
Компания Level1Techs рассказала, как она использовала DGX Spark для параллельного запуска нескольких LLM и VLM, чтобы обеспечить взаимодействие между агентами.
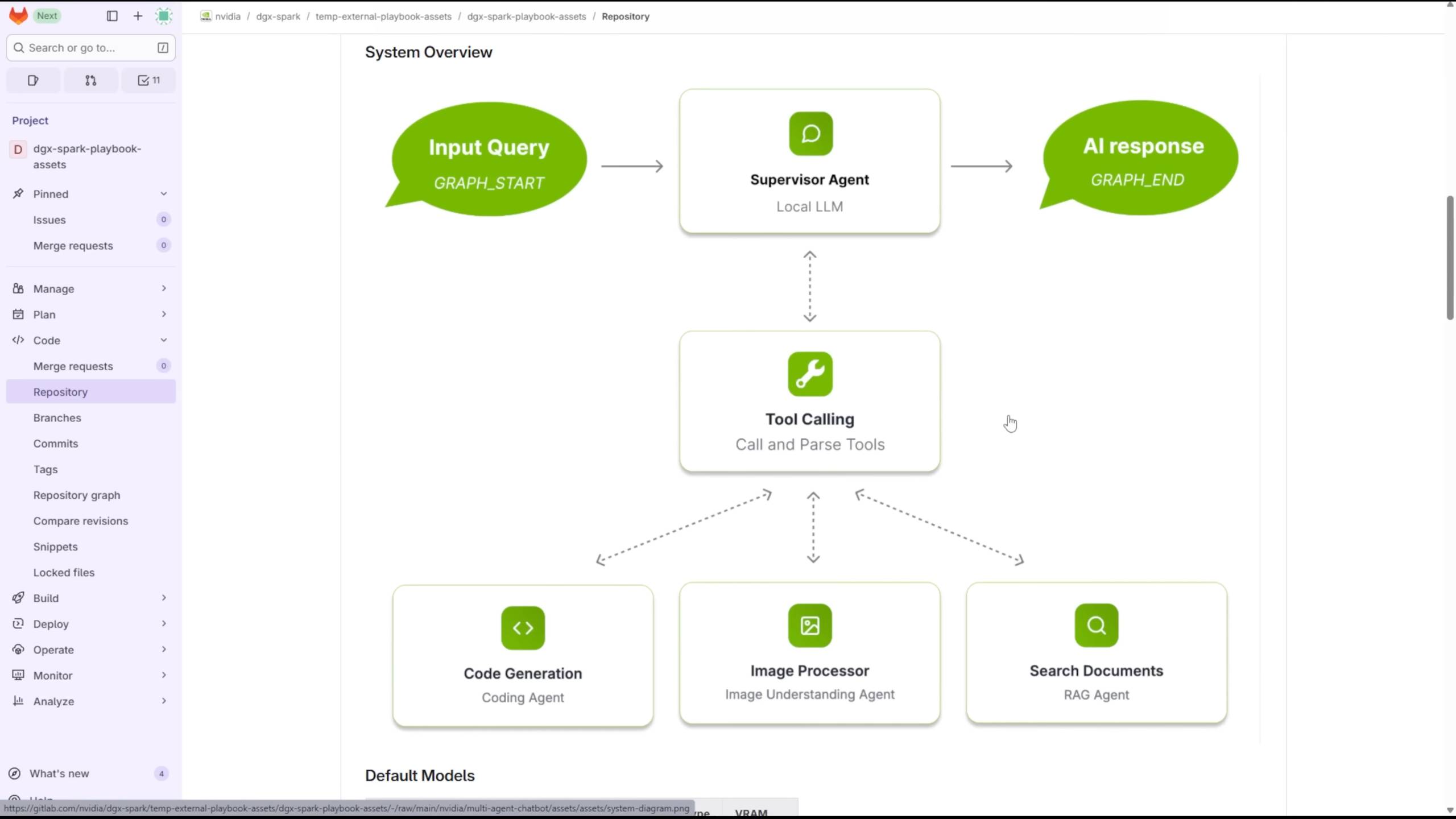
▲ Подробный обзор NVIDIA DGX Spark, источник видео: https://youtu.be/Lqd2EuJwOuw
Благодаря 128 ГБ памяти он может выбирать из четырех моделей для выполнения различных задач: GPT-OSS со 120 миллиардами параметров, DeepSeek-Coder с 6,7 миллиардами параметров, а также Qwen3-Embedding-4B и Qwen2.5-VL:7B-Instruct.
Этот проект также является официальным руководством от Nvidia. На их сайте предлагается более 20 способов его использования, и для каждого из них указывается примерное время выполнения и подробные инструкции.
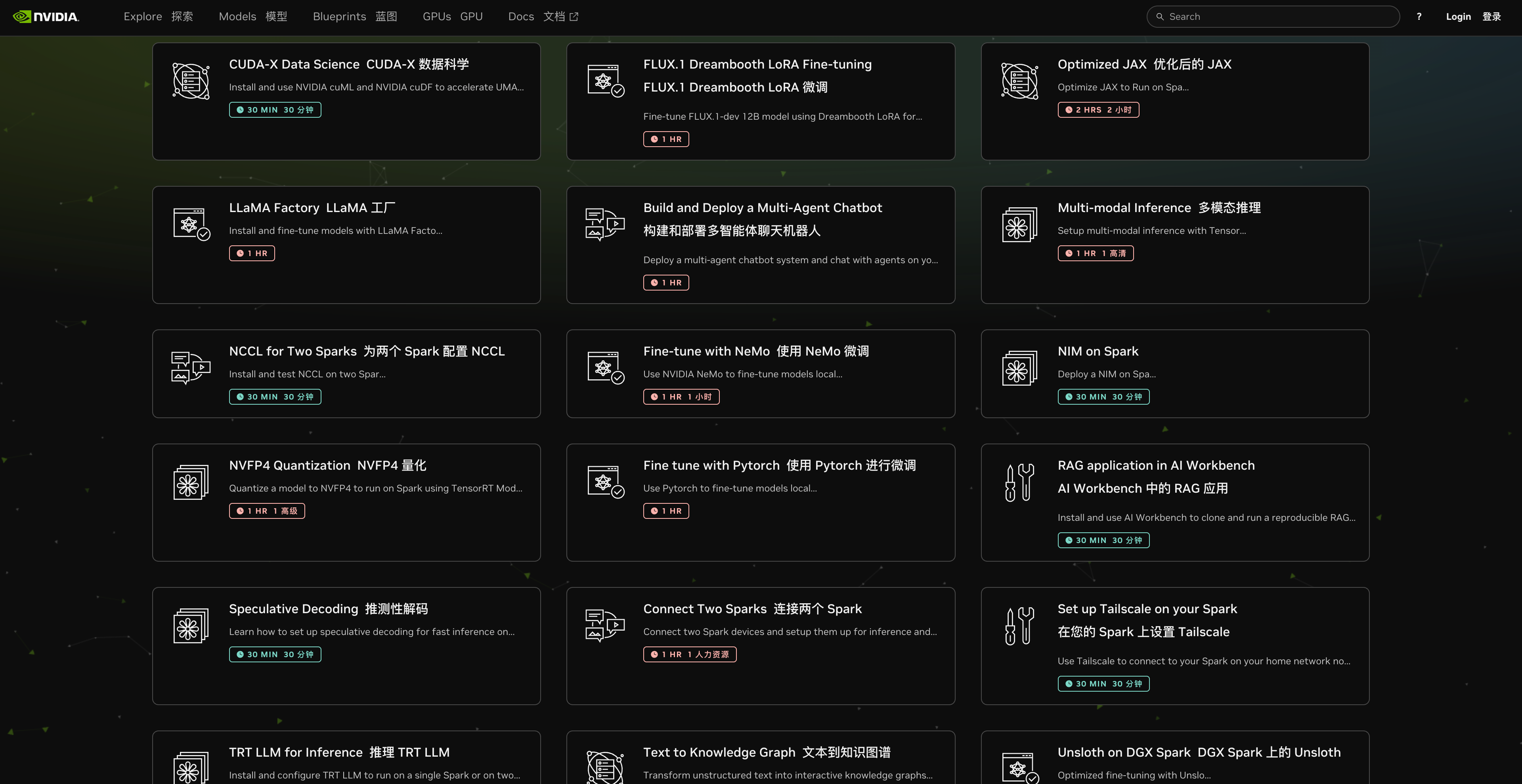
▲ https://build.nvidia.com/spark
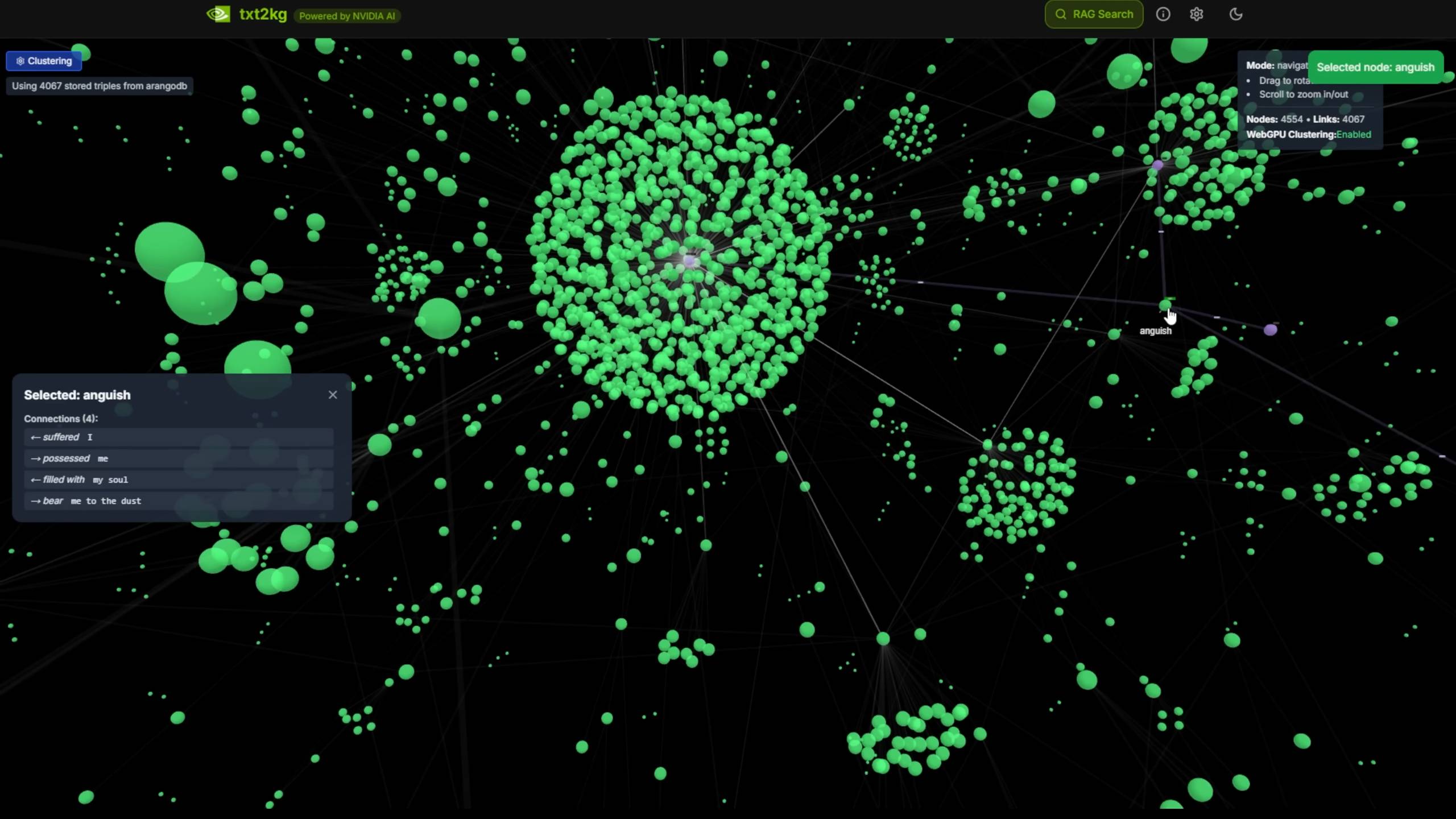
Это похоже на построение системы графа «текст-знания», преобразующей неструктурированные текстовые документы в структурированные узлы знаний.
Поиск и краткое содержание видео.
Мы также нашли несколько пользователей на Reddit, которые получили DGX Spark и начали сеанс AMA (Ask Me Anything). Один из них поделился результатами тестирования, отметив, что возможности ИИ-технологий видеокарты сопоставимы с RTX 5070. Другой пользователь спросил, возможно ли запустить недавно запущенный проект Karpathy nanochat.
Ожидается, что вскоре появятся новые результаты тестов и более подробные обновления руководства пользователя для DGX Spark, а DGX Spark от APPSO появится совсем скоро.
Существование DGX Spark больше похоже на эксперимент в эпоху быстрого развития ИИ: настольная машина с вычислительной мощностью уровня центра обработки данных, проверяющая границы нашего воображения в отношении локального ИИ.
Настоящий вопрос, помимо того, сможет ли DGX Spark работать, заключается в том, что мы сможем сделать с суперкомпьютером, когда он будет у каждого из нас.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (WeChat ID: ifanr), где вы сможете как можно скорее получить еще больше интересного контента.
ifanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo