Обновление модели мира Фэй-Фэй Ли: создавайте трёхмерные миры в реальном времени, используя только графический процессор

В то время Ультрамен из OpenAI все еще скупал графические карты и вычислительные мощности по всему миру, чтобы поддерживать свою модель генерации видео Sora 2.
Лаборатория Фэй-Фэй Ли, The World Labs, способна создать целый мир на одной видеокарте. Сегодня они представили новую технологию RTFM (Real-Time Frame Model) — совершенно новую модель генерации мира в реальном времени.

В отличие от Marble, мира, созданного на основе изображений и выпущенного в середине сентября, RTFM не только использует одну фотографию для создания трехмерного мира, по которому мы можем свободно перемещаться и исследовать, но, что самое важное, он разработан для эффективной работы на одном графическом процессоре H100 и создания мира в реальном времени.
В настоящее время RTFM официально выпущен в качестве ознакомительной исследовательской версии, и вам предоставляется демо-версия, чтобы вы могли опробовать ее самостоятельно.
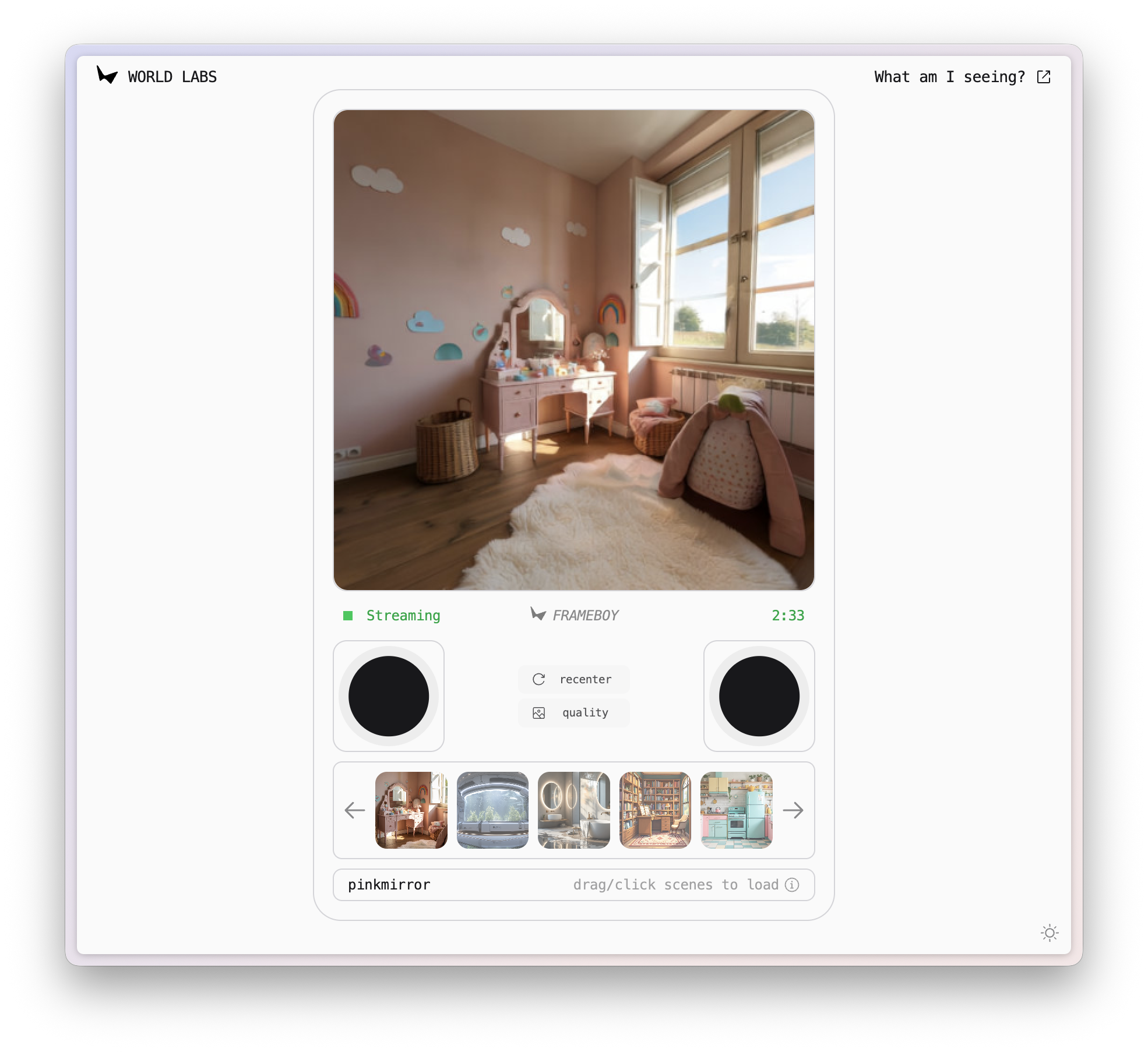
▲ Ссылка на демо-версию RTFM: https://rtfm.worldlabs.ai/
Неожиданно я обнаружил, что демо-версия называется FRAMEBOY. В сочетании с дизайном веб-страницы мне сразу пришла в голову мысль о старой консоли Game Boy.
Такой мир с реалистичным освещением, отражениями и тенями, происходящими в реальном времени на наших глазах, в каком-то смысле является просто еще одним способом игры.
Больше, чем просто генерация, больше о взаимодействии в реальном времени
Основная функция RTFM — создание интерактивных видео в реальном времени. RTFM может начать со статичного изображения и превратить его в свободно исследуемую 3D-сцену.
В отличие от многих мировых моделей, RTFM способен обучаться и воспроизводить чрезвычайно сложные и реалистичные визуальные эффекты. Будь то отражения на гладких мраморных полах, тени от предметов на солнце или виды сквозь стекло, RTFM точно их имитирует.
RTFM не опирается на традиционное графическое программирование, а вместо этого позволяет модели непрерывно развиваться посредством сквозного изучения больших объемов видеоданных.

В основе этой возможности лежат три основных принципа, на которых был разработан RTFM.
Эффективность: Если мы хотим приблизить будущее к настоящему, то вычислительные требования модели мира являются самым большим препятствием.
Будь то видео, сгенерированное ИИ, например, Sora, или Genie 3 от Google, который пока официально не выпущен, оба решения представляют собой колоссальные вычислительные задачи. Исследования показали, что для создания интерактивного видеопотока 4K с частотой 60 кадров в секунду в реальном времени модели ИИ необходимо обрабатывать количество токенов в секунду, примерно эквивалентное объёму текста в книге о Гарри Поттере.
Если мы хотим сохранить сгенерированный контент в течение взаимодействия, длящегося более часа, необходимый для обработки контекст превысит 100 миллионов токенов. Это непрактично и невыгодно для текущей вычислительной инфраструктуры.

Цель команды Фэй-Фэй Ли — «запускать модели будущего на сегодняшнем оборудовании и обеспечивать максимально точный предварительный просмотр».
Благодаря экстремальной оптимизации архитектуры, дистилляции модели и процесса вывода, а также перепроектированию всей системы, им удалось успешно достичь RTFM, используя всего один графический процессор H100 для выполнения вывода с интерактивной частотой кадров и генерации результатов в реальном времени.
Масштабируемость: от видеомоделей до моделей мира.
Традиционные 3D-движки используют явные структуры, такие как треугольные сетки, гауссовы облака точек и воксельный рендеринг, полностью полагаясь на сложные знания компьютерной графики. Каждый объект должен быть смоделирован, текстурирован, освещен и запечен с тенями. Этот подход аналогичен представленному ранее 3D-миру Hunyuan, и ориентирован на создание полноценного 3D-конвейера.

Традиционный 3D-метод (слева) и метод RTFM (справа)
В отличие от Hunyuan, World Lab использует другой подход. RTFM не строит явных трёхмерных моделей. Вместо этого он использует авторегрессионный диффузионный преобразователь, аналогичный Sora, для изучения закономерностей окружающего мира непосредственно из последовательностей видеокадров.
Например, модели больше не нужно знать, «это стена» или «это лампа». Она лишь усваивает, что такое «пространственное чувство», изучая тысячи видеороликов, и учится предсказывать следующую новую перспективу на основе входной последовательности двумерных изображений.
В отличие от метода генерации 3D-активов, RTFM позволяет эффективнее использовать постоянно растущие объемы данных и вычислительную мощность, достигая тем самым неограниченной масштабируемости.
Устойчивость , которая сохраняет модель мира последовательной, как нано-банан.
Большинству моделей видеогенерации присущ один существенный недостаток: им не хватает памяти. Несмотря на то, что Sora может сгенерировать 25 секунд потрясающего видео за один раз, мир заканчивается после создания видео, и он не может обеспечить непрерывное взаимодействие.
Однако если мы хотим запомнить все сценарии, вычислительная нагрузка неизбежно будет бесконечно накапливаться по мере углубления исследования.

RTFM пытается обеспечить сохранение сгенерированного мира. Он использует механизм, называемый «пространственной памятью», который присваивает каждому сгенерированному кадру точную «позу» (положение и ориентацию) в трёхмерном пространстве.
При генерации новых изображений модель использует технику, называемую «жонглирование контекстом», которая использует в качестве ссылок только кадры рядом с новым изображением, а не глобальный контекст.

Это позволяет использовать RTFM, позволяя нам многократно входить в мир, выходить из него и возвращаться в него без увеличения вычислительной нагрузки.
В настоящее время демо RTFM длится всего три минуты, после чего теряет память об окружающем мире. Я долго перетаскивал левый и правый джойстики в демо, и это напомнило мне слова Фэй-Фэй Ли о том, что пространственный интеллект должен стать следующим шагом в развитии искусственного интеллекта.

Будет ли в будущем возможность создать чёткую связь между реальным и виртуальным мирами, как в фильме «Первому игроку приготовиться»? Если взглянуть на текущую модель мира, становится ясно, что в ней всё ещё слишком много контента для загрузки.
В конце концов, даже один графический процессор H100 стоит более 25 000 долларов. Но по мере снижения стоимости вычислительной мощности и ускорения алгоритмов мы можем стать свидетелями действительно значительного «обновления» модели мира — дня, когда реальность будет полностью сгенерирована.
#Приглашаем вас следить за официальным публичным аккаунтом WeChat проекта iFaner: iFaner (WeChat ID: ifanr), где в ближайшее время вам будет представлен еще более интересный контент.
iFanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo