Компания DeepSeek только что выпустила новую модель, выводящую маленькие и красивые модели на новый уровень.
Недавно компания DeepSeek открыла исходный код модели 3B, DeepSeek-OCR. Несмотря на небольшой размер модели 3B, она содержит значительные инновации в моделировании.
Как мы все знаем, все современные LLM сталкиваются с неизбежной дилеммой при обработке длинных текстов: вычислительная сложность растёт квадратично. Чем длиннее последовательность, тем больше вычислительной мощности потребляется.
Итак, команде DeepSeek пришла в голову гениальная идея. Поскольку одно изображение может содержать большой объём текстовой информации, используя относительно небольшое количество токенов, почему бы не преобразовать текст непосредственно в изображение? Это называется «оптической компрессией» — использование визуальных модальностей для уменьшения объёма текстовой информации.
OCR естественным образом подходит для проверки этой идеи, поскольку выполняет преобразование «визуальное→текстовое», а эффект можно оценить количественно.
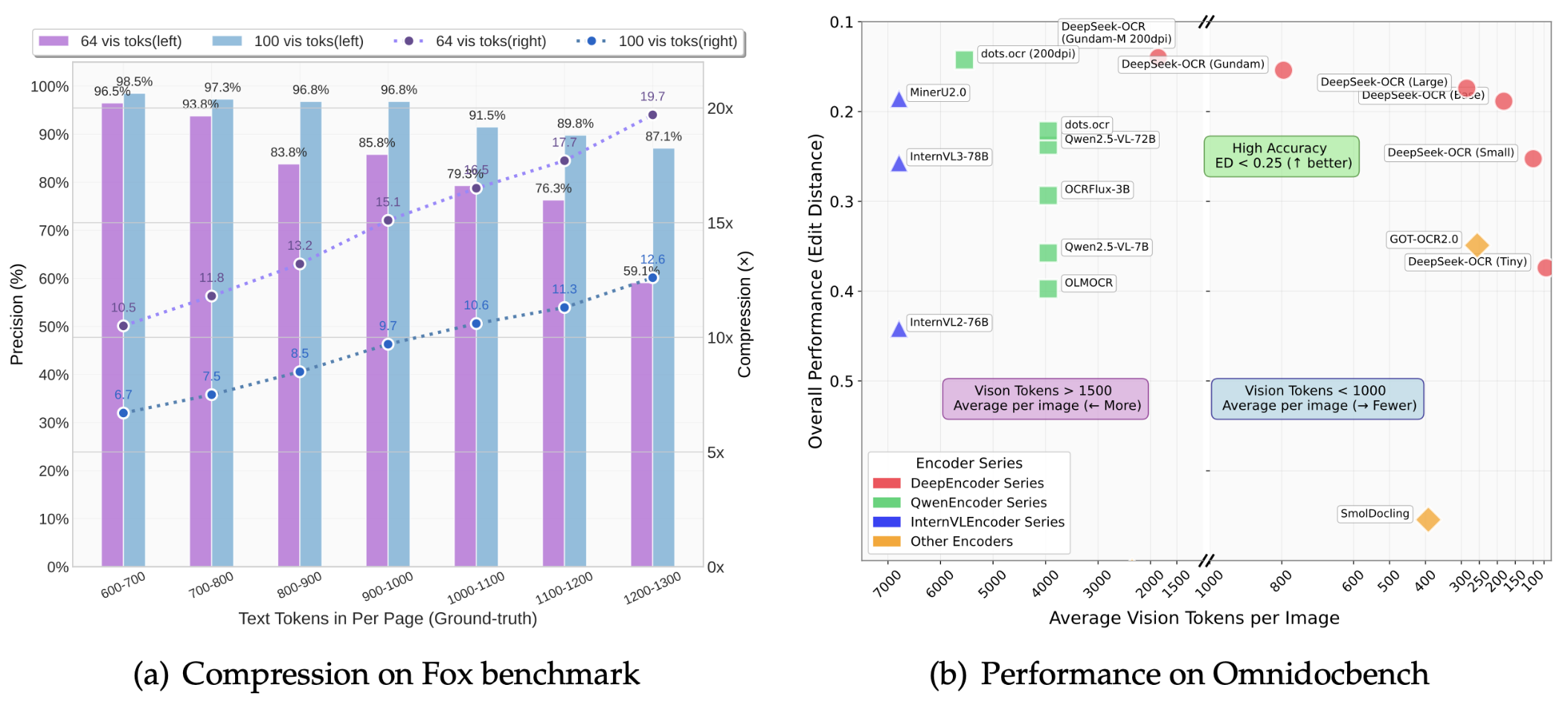
В статье показано, что степень сжатия DeepSeek-OCR может достигать 10 раз, а точность OCR может поддерживаться на уровне выше 97%.
Что это значит? Это означает, что контент, для которого раньше требовалось 1000 текстовых токенов, теперь можно выразить всего 100 визуальными токенами. Даже при 20-кратном сжатии точность остаётся около 60%, что в целом весьма впечатляет.
Результаты теста OmniDocBench показывают:
- Используя всего 100 визуальных токенов, он превосходит производительность GOT-OCR2.0 (256 токенов на страницу)
- С менее чем 800 визуальными токенами он превзошел MinerU2.0 (более 6000 токенов на страницу в среднем)
В реальных условиях одна видеокарта A100-40G может генерировать более 200 000 страниц обучающих данных LLM/VLM в день. При использовании 20 узлов (160 A100) этот показатель возрастает до 33 миллионов страниц в день.
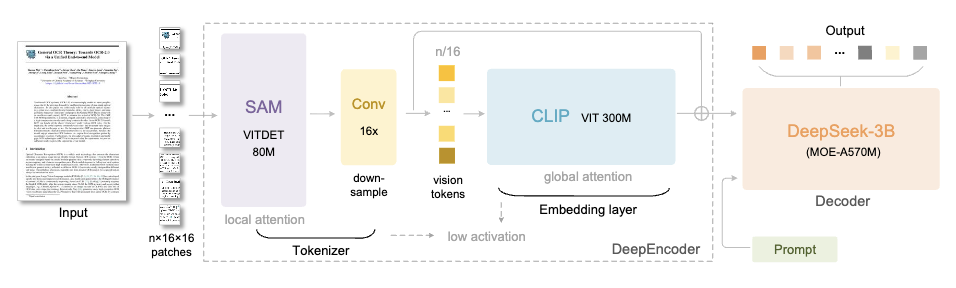
DeepSeek-OCR состоит из двух основных компонентов:
- DeepEncoder (кодер): отвечает за извлечение и сжатие признаков изображения.
- DeepSeek3B-MoE (декодер): отвечает за реконструкцию текста из сжатых визуальных токенов.
Давайте сосредоточимся на движке DeepEncoder.
Его архитектура очень продумана. Благодаря объединению SAM-base (80 миллионов параметров) и CLIP-large (300 миллионов параметров) первый отвечает за «оконный анализ» для извлечения визуальных характеристик, а второй — за «глобальный анализ» для понимания общей информации.
В середине добавлен 16-кратный сверточный компрессор, позволяющий существенно сократить количество токенов перед входом в глобальный слой внимания.
Например, изображение размером 1024×1024 будет разделено на 4096 токенов. Однако после обработки компрессором количество токенов, попадающих в глобальный слой внимания, значительно сократится.
Преимущество этого подхода заключается в том, что он обеспечивает возможность обработки входных данных высокого разрешения, контролируя при этом накладные расходы на активационную память.
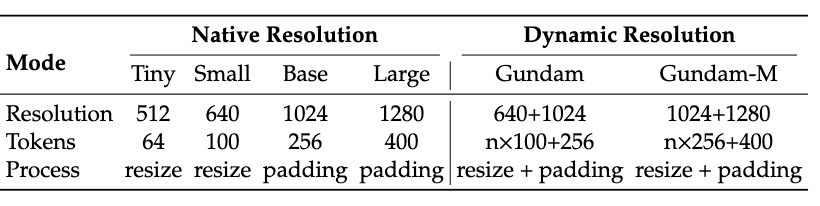
Более того, DeepEncoder также поддерживает ввод с несколькими разрешениями: от крошечного режима 512×512 (64 токена) до большого режима 1280×1280 (400 токенов), все они обрабатываются одной моделью.
Версия с открытым исходным кодом в настоящее время поддерживает четыре режима: Tiny, Small, Base и Large в собственном разрешении, а также режим Gundam в динамическом разрешении, что обеспечивает максимальную гибкость.
Декодер использует архитектуру DeepSeek-3B-MoE.
Несмотря на наличие всего 3 миллиардов параметров, модель использует смешанную экспертную модель (MoE), активируя 6 из 64 экспертов, плюс 2 общих эксперта, что в сумме составляет приблизительно 570 миллионов активированных параметров. Это обеспечивает модели выразительную мощь модели с 3 миллиардами параметров, сохраняя при этом эффективность вывода модели с 500 миллионами параметров.
Задача декодера — реконструировать исходный текст из сжатых визуальных токенов. Этот процесс может быть эффективно освоен компактной языковой моделью посредством обучения в стиле OCR.
Что касается данных, то команда DeepSeek также вложила значительные средства.
Из Интернета было собрано 30 миллионов страниц многоязычных PDF-данных, охватывающих около 100 языков, из которых 25 миллионов страниц пришлось на китайский и английский.
Данные делятся на две категории: грубые аннотации извлекаются непосредственно из PDF-файла с помощью Fitz, в основном для обучения возможностей распознавания нескольких языков; точные аннотации генерируются с использованием таких моделей, как PP-DocLayout, MinerU и GOT-OCR2.0, и содержат высококачественные данные, которые сплетают воедино обнаружение и распознавание.
Для нескольких языков группа также разработала механизм «модельного маховика» — сначала использовала модель анализа макета с возможностями межъязыкового обобщения для обнаружения, затем использовала данные, сгенерированные Fitz, для обучения GOT-OCR2.0, а затем использовала обученную модель для аннотирования дополнительных данных, повторяя этот цикл, чтобы в конечном итоге сгенерировать 600 000 образцов.
Кроме того, имеются данные 3 миллионов документов Word, что в основном улучшает возможности распознавания формул и анализа HTML-таблиц.
Для распознавания текста на сцене мы собрали изображения из наборов данных LAION и Wukong и аннотировали их с помощью PaddleOCR, используя по 10 миллионов образцов на китайском и английском языках.

DeepSeek-OCR не только распознаёт текст, но и обладает возможностями «глубокого анализа». Используя всего лишь унифицированное слово-подсказку, он может выполнять структурированное извлечение на различных сложных изображениях:
- Диаграммы: диаграммы из отчетов по финансовым исследованиям можно извлекать непосредственно в виде структурированных данных.
- Химические структуры: определение и преобразование в формат SMILES
- Геометрия: Копирование и структурный анализ плоской геометрии
- Естественные изображения: создание насыщенных подписей
Это имеет большой потенциал применения в областях STEM, особенно в таких сценариях, как химия, физика и математика, где требуется обработка большого количества символов и графики.
Здесь следует упомянуть креативную идею, предложенную командой DeepSeek, — использование оптического сжатия для моделирования механизма забывания человека.
Человеческая память со временем ухудшается, и воспоминания о прошлых событиях становятся всё более размытыми. Команда DeepSeek задались вопросом, сможет ли искусственный интеллект добиться того же. Их решение:
- Перенести содержание исторического разговора за пределами раунда k в изображение
- Первоначальное сжатие, достигающее примерно 10-кратного уменьшения размера токена
- Для дальнейшего контекста продолжайте уменьшать размер изображения.
- По мере уменьшения изображения содержимое становится все более размытым, в конечном итоге достигается эффект «забывания текста».
Это очень похоже на кривую угасания человеческой памяти, где недавняя информация сохраняет высокую точность, в то время как долгосрочные воспоминания естественным образом стираются.
Хотя это пока еще раннее направление исследований, если его удастся реализовать, это станет огромным прорывом в обработке сверхдлинных контекстов — недавний контекст сохраняет высокое разрешение, исторический контекст потребляет меньше вычислительных ресурсов и теоретически может поддерживать «бесконечный контекст».
Короче говоря, DeepSeek-OCR на первый взгляд представляет собой модель OCR, но на самом деле она исследует более широкое предложение: можно ли использовать визуальную модальность в качестве эффективного средства сжатия для обработки текстовой информации LLM?
Предварительный ответ — да, и была продемонстрирована возможность сжатия токена в 7–20 раз.
Конечно, команда признаёт, что это только начало. Одного лишь распознавания текста недостаточно для полной валидации контекстного оптического сжатия. Они планируют провести последующую предварительную подготовку с чередованием цифрового и оптического текста, тестирование методом «иголки в стоге сена» и другие систематические оценки.
Но как бы то ни было, это добавляет новый импульс развитию VLM и LLM.
В это же время в прошлом году все еще думали о том, как заставить модель «запоминать больше».
В этом году DeepSeek выбрала противоположный подход: что, если модель научилась «забывать» что-то? Действительно, эволюция ИИ иногда связана с вычитанием, а не сложением. Малое и прекрасное тоже может достичь великих целей, и небольшая 3B-модель DeepSeek-OCR — прекрасное тому подтверждение.
Домашняя страница GitHub:
http://github.com/deepseek-ai/DeepSeek-OCR
бумага:
https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
Загрузка модели:
https://huggingface.co/deepseek-ai/DeepSeek-OCR
#Приглашаем вас следить за официальным публичным аккаунтом WeChat проекта iFaner: iFaner (WeChat ID: ifanr), где в ближайшее время вам будет представлен еще более интересный контент.
iFanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo