В этом списке проектов с открытым исходным кодом, от самых перспективных до самых простых, я наконец понял, почему китайский ИИ смог совершить рывок.
В последние дни на X-сервере широко распространился список уровней для модели с открытым исходным кодом.

▲ Источник изображения: https://www.interconnects.ai/p/2025-open-models-year-in-review
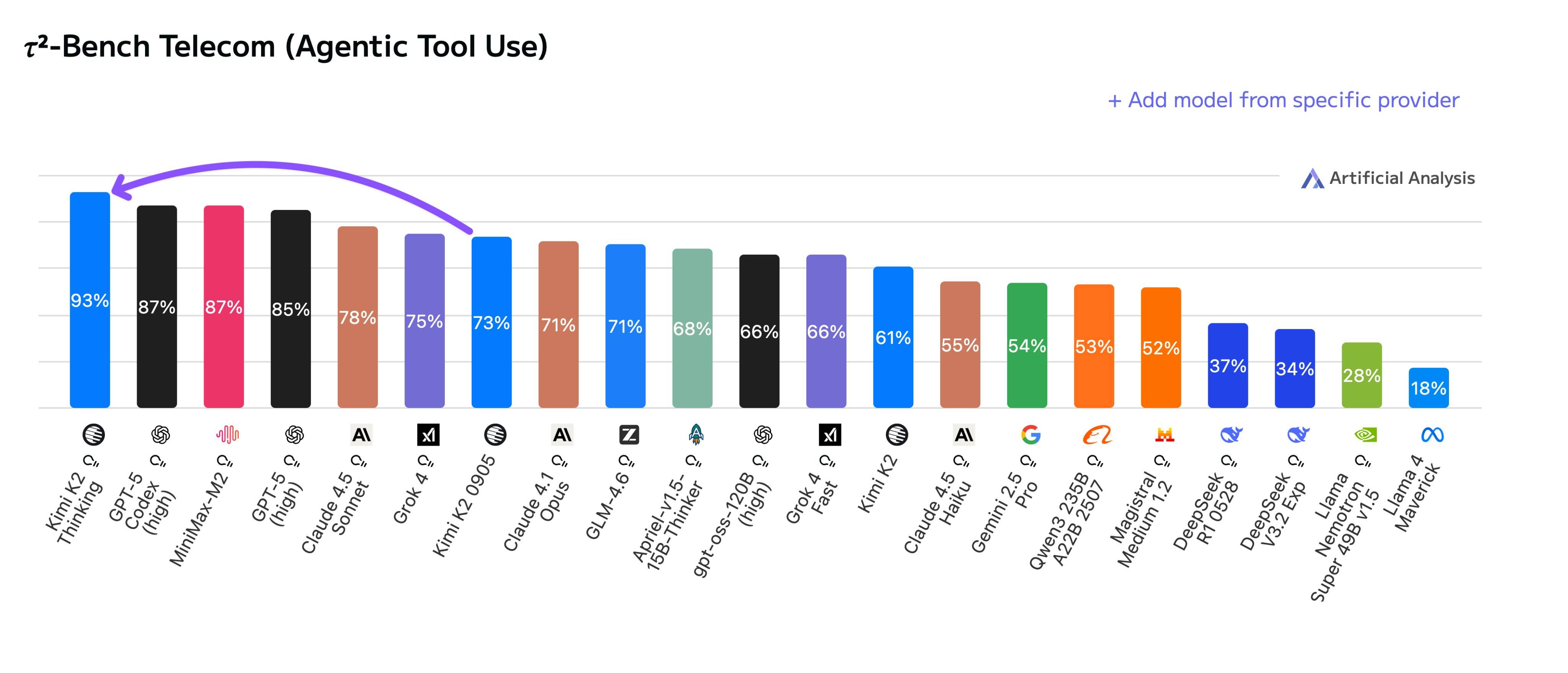
В рейтинге лучших моделей с открытым исходным кодом, разработанных внутри страны, лидируют DeepSeek, Qwen, Kimi, Zhipu и MiniMax, занимающие первые пять мест в мировом рейтинге. OpenAI, напротив, находится на четвертом уровне. Meta Цукерберга и Llama, которую он пытался создать, переманив половину талантов Кремниевой долины, получили лишь почетную номинацию.
Этот рейтинг не является результатом платной рекламы моделей, разработанных внутри страны, и не представляет собой саморекламу со стороны Китая. В статье, опубликованной на Interconnectai известным исследователем в области ИИ Натаном Ламбертом и Флорианом Брэндом, аспирантом Немецкого исследовательского центра ИИ, представлен полный рейтинг моделей с открытым исходным кодом по всему миру.

▲Нейтан Ламберт работал в компаниях Meta, DeepMind и Hugging Face.
В статье представлен подробный обзор развития глобальных моделей с открытым исходным кодом за последний год, с акцентом на то, как отечественные модели с открытым исходным кодом, в первую очередь DeepSeek и Qwen, меняют правила работы всей индустрии ИИ благодаря открытому исходному коду .
Действительно, 2024 год может стать годом Llama для глобального открытого исходного кода. Однако в этом году отечественные разработки с открытым исходным кодом оказали значительное влияние, постоянно переосмысливая стандартные варианты в глобальных моделях открытого исходного кода.
Производительность, цена, экосистема, удобство использования… по всем параметрам она стремительно приближается к гигантам закрытого программного обеспечения, а в некоторых аспектах даже превзошла их.

▲История релизов американо-китайской модели с открытым исходным кодом, январь 2024 г. – ноябрь 2025 г. Источник изображения: https://www.atomproject.ai/
Пока мы все еще гадаем, когда отечественные модели смогут догнать ChatGPT и Gemini, в гонке вооружений в сфере ИИ начинает накаляться другой вопрос: почему разработчики по всему миру используют отечественные модели с открытым исходным кодом?
В модели с открытым исходным кодом участвуют как признанные, так и новые игроки.
В последние несколько месяцев темпы обновлений отечественных моделей с открытым исходным кодом практически непрерывны. И это не просто прорыв одной компании-разработчика модели; это вся отечественная экосистема открытого исходного кода, постоянно расширяющая границы возможного, подобно быстро восходящей кривой, постоянно преодолевающая узкие места.
В ноябре компания Kimi выпустила Kimi K2 Thinking, гибридную экспертную модель с триллионами параметров, которая сразу же возглавила множество рейтинговых таблиц, превзойдя даже GPT-5 от OpenAI и Claude 4.5 от Anthropic.
В конце октября компания MiniMax официально выпустила гибридную экспертную модель MiniMax M2 MoE. Как и Kimi, она остается открытым исходным кодом. По общей производительности MiniMax M2 заняла пятое место, превзойдя Gemini 2.5 Pro и Claude Opus 4.1.
В сентябре на конференции Yunqi компания Alibaba представила серию из семи моделей, продемонстрировавших превосходные результаты в различных областях, таких как компьютерное зрение, речь, логическое мышление и программирование.
В зарубежных социальных сетях, начиная с появления DeepSeek, постоянно отмечаются китайские модели с открытым исходным кодом. «Простота использования, низкая цена, лучший выбор для разработки в небольших компаниях, в моих сторонних проектах используются китайские модели с открытым исходным кодом…» Такие комментарии встречаются повсюду на X.
Например, пользователи сети высоко оценили стиль письма Кими К2 Тинка и использование им жетонов в качестве способа обмена на глубину мысли.
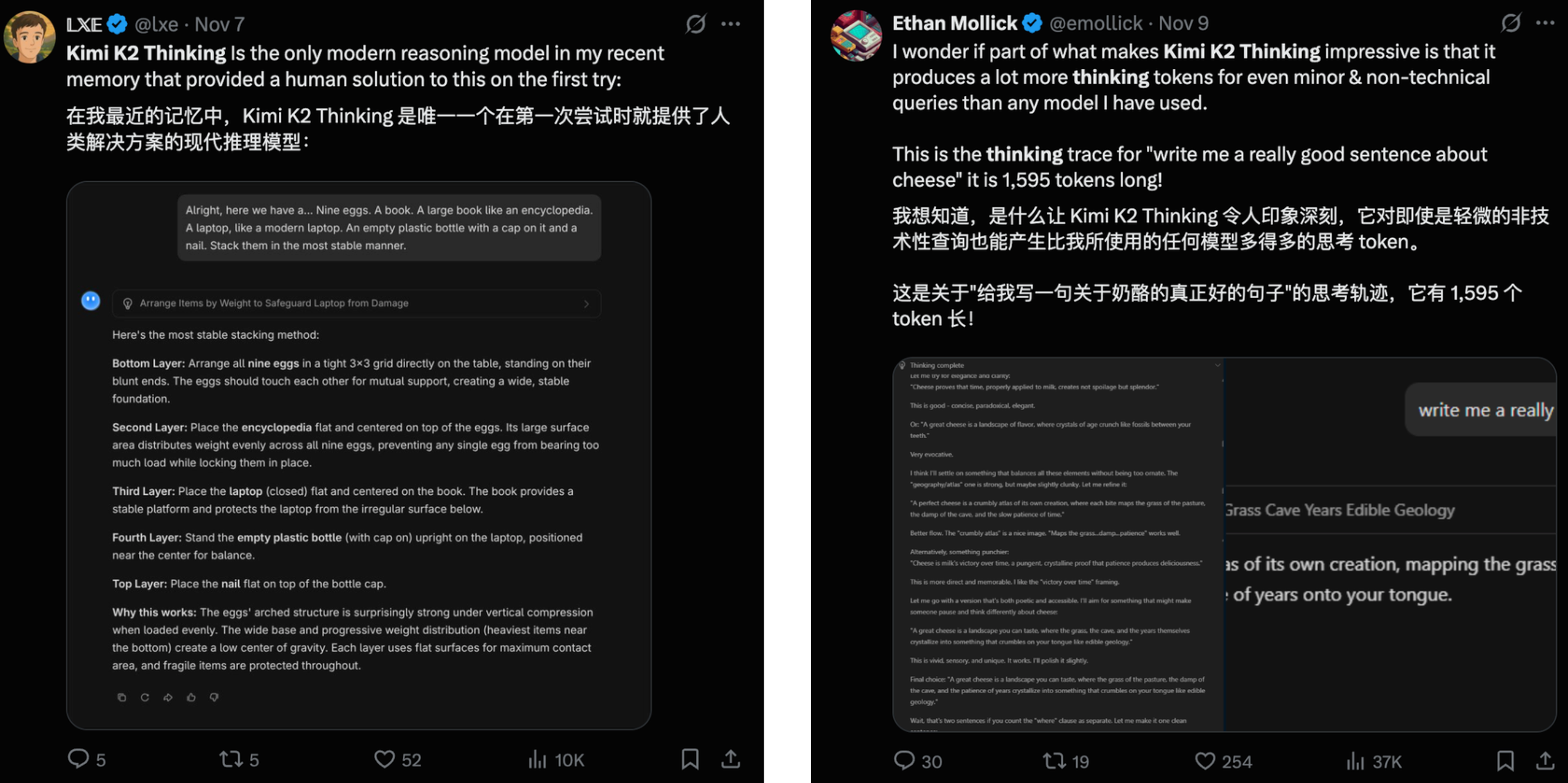
Некоторые пользователи сети также сравнили Minimax M2 с Claude Sonnet 4, отметив, что M2 может создать полностью функциональный веб-сайт всего за одно использование, тогда как Sonnet 4 потерпит неудачу.

Существует еще больше публикаций о Qwen. От версии 2.5 до текущей 3.0, от большой модели с 480 миллиардами параметров до небольшой модели всего с 600 миллионами параметров, от визуального языка Qwen 3 VL до инструмента для написания кода Qwen 3 Coder, Qwen присутствует практически на всем рынке открытого исходного кода.
В одном из интервью генеральный директор Airbnb даже открыто заявил, что, хотя OpenAI хорош, он им не подходит; в то время как модель с открытым исходным кодом Qwen из Китая превосходна, практически применима к их работе, а также лучше и дешевле, чем OpenAI.
В сфере открытого исходного кода неверно утверждать, что отечественная модель открытого исходного кода все еще отстает; она уже стала общепринятым выбором в глобальном масштабе.
MiniMax M2 — это интеллектуальный агент с открытым исходным кодом, который может быть развернут в реальных приложениях.
Если мы хотим привести конкретные примеры, иллюстрирующие преимущества отечественной модели с открытым исходным кодом, то реальный опыт тестирования нескольких инструментов с открытым исходным кодом, которым мы уже делились ранее, уже дает ответ.
Самая последняя выпущенная разработка — Kimi K2 Thinking, обладающая сверхдлинной цепочкой мышления, способной выполнить 300 вызовов инструментов за один запуск; также есть Zhipu AutoGLM 2.0, универсальный агент, разработанный для мобильных телефонов; и семейство моделей Alibaba Tongyi для Android в эпоху искусственного интеллекта.

▲Статистические данные по анализу данных ведущих отечественных производителей моделей ИИ и стартапов за 1 квартал 2025 года
Хотя все эти модели являются открытым исходным кодом, каждая из них имеет свои технические особенности, стремясь сделать карту отечественных моделей с открытым исходным кодом более полной и богатой.
K2 Thinking фокусируется на большой модели с триллионами параметров и имеет собственный механизм KDA (Kimi Delta Attention); DeepSeek фокусируется на гибридном механизме внимания, что значительно снижает затраты; Minimax M2 в этом обновлении изменил свой подход и использует полный механизм внимания, имея всего 230 миллиардов параметров модели.
Чтобы проверить, насколько хорош M2, мы провели простой тест, придерживаясь принципа тестирования при каждой возможности.
Нашей первой задачей было поручить ему обработать данные из электронной таблицы Excel. Мы отправили ему таблицу вакансий для национального экзамена на государственную службу этого года и попросили разработать универсальный инструмент для отбора кандидатов на государственные должности на основе содержимого этой таблицы.
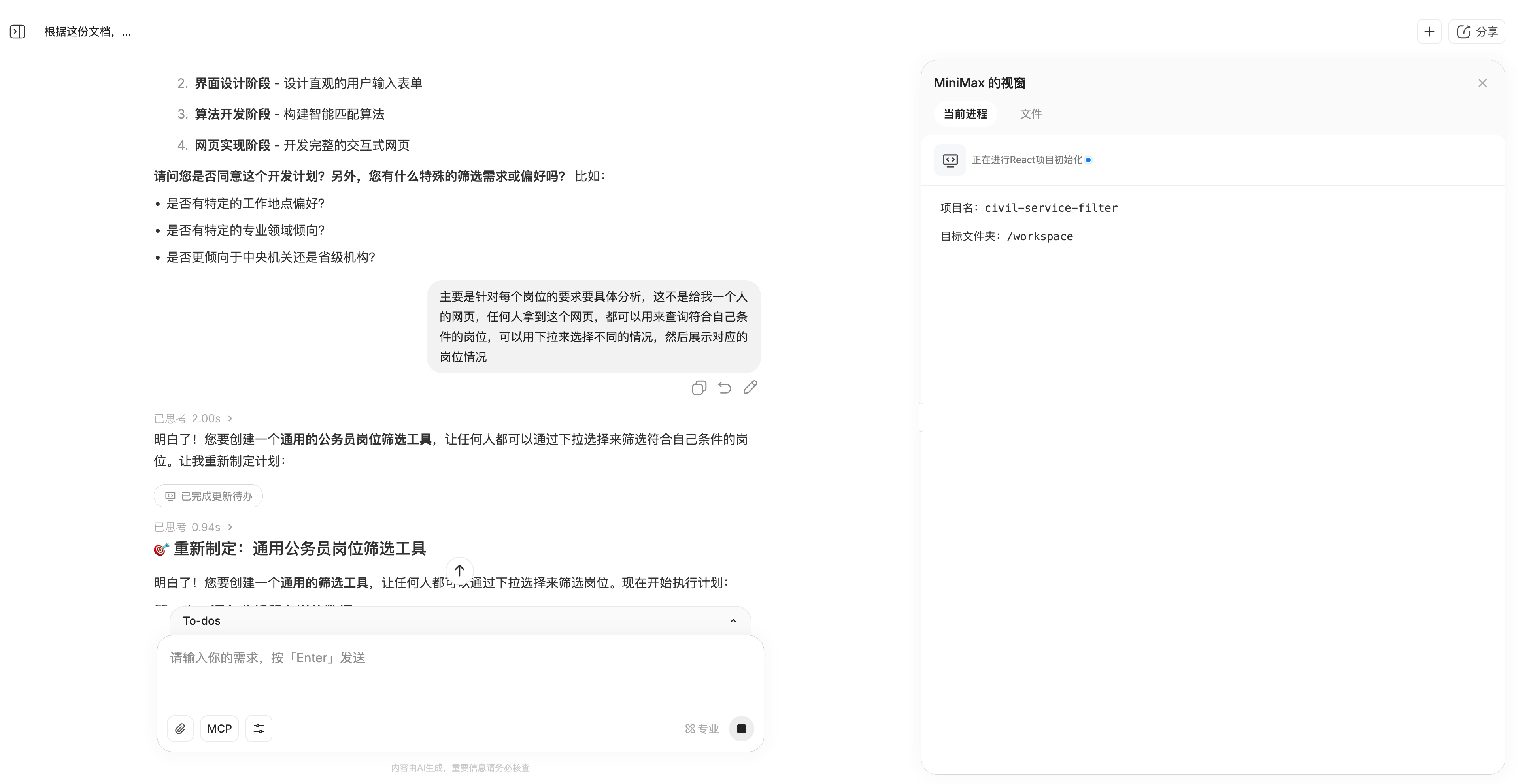
Таблица содержит большой объем данных, 10 МБ, и включает более 20 000 объявлений о вакансиях. Особенно полезной функцией MiniMax M2 является то, что перед выполнением программа спрашивает пользователя, необходимы ли какие-либо корректировки задачи.
В своем техническом блоге они упомянули, что M2 использует технику «чередующегося мышления», которая впервые была применена в модели Клода Сонета 4, но ее внедрение пока еще очень ограничено.
MiniMax предлагает подсказку, напоминающую пользователям о необходимости сохранять ход своих мыслей с помощью тегов «думать» в модели. Модель M2 основана на чередующемся мышлении, и контекст имеет важное значение для памяти; сохранение этой информации позволяет лучше использовать чередующееся мышление.

▲Директор по разработке MiniMax, Факс, объяснил, как чередующееся мышление позволяет моделям лучше справляться с задачами агентов.
Проще говоря, чередующееся мышление — это продвижение задачи за счет того, что большая модель «делает что-то (используя инструменты/вызывая интерфейсы), останавливается и думает, затем снова делает что-то, а затем снова думает», вместо того, чтобы продумывать множество идей и затем выполнять их все одновременно.
В недавно обновленной версии Kimi K2 Thinking также используется техника чередующегося мышления . Такой подход, при котором мышление и обращение к идеям происходят одновременно, позволяет модели немедленно пересматривать и корректировать свои планы после каждого получения результатов от инструмента. Это особенно подходит для задач, выполняемых агентами, с длительными процессами и неопределенными результатами.
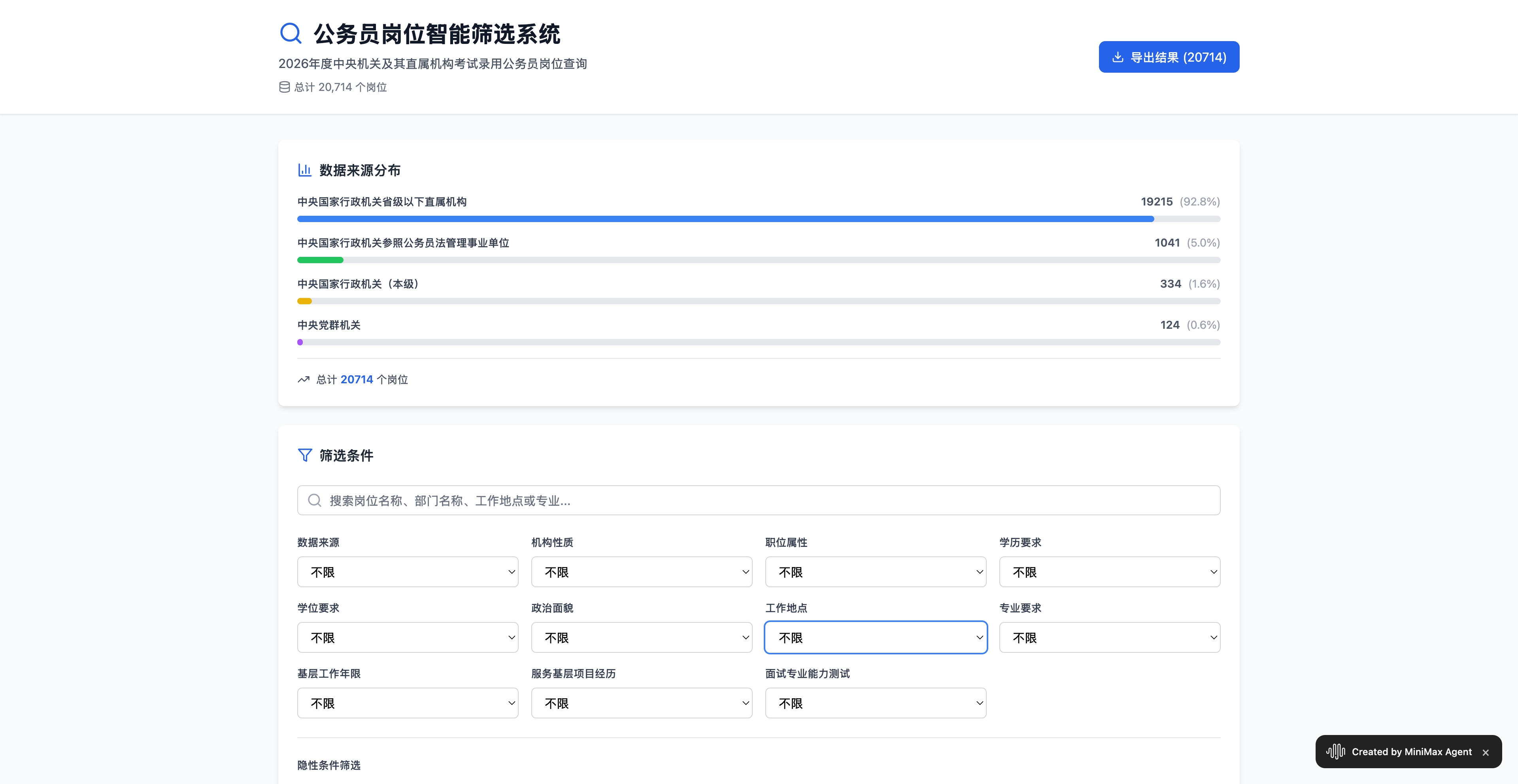
▲ Оцените это здесь: https://2rfxtimus5nr.space.minimaxi.com/; Хотя экзамен уже закончился, вы все еще можете убедиться, что возможности MiniMax M2 по обработке данных из электронных таблиц Excel нельзя недооценивать.
Итоговый результат очень точен, отображая 20 714 вакансий, и включает статистику по таким факторам, как наличие у соискателя недавнего окончания вуза, опыт работы на низовых должностях и место жительства. По сравнению с некоторыми платными инструментами подбора персонала на рынке, автоматическое создание вакансии с помощью Agent гораздо удобнее.
Мы также поручили ему провести углубленное исследование, предоставив информацию о самом M2 и создав для него красивую презентацию в PowerPoint.
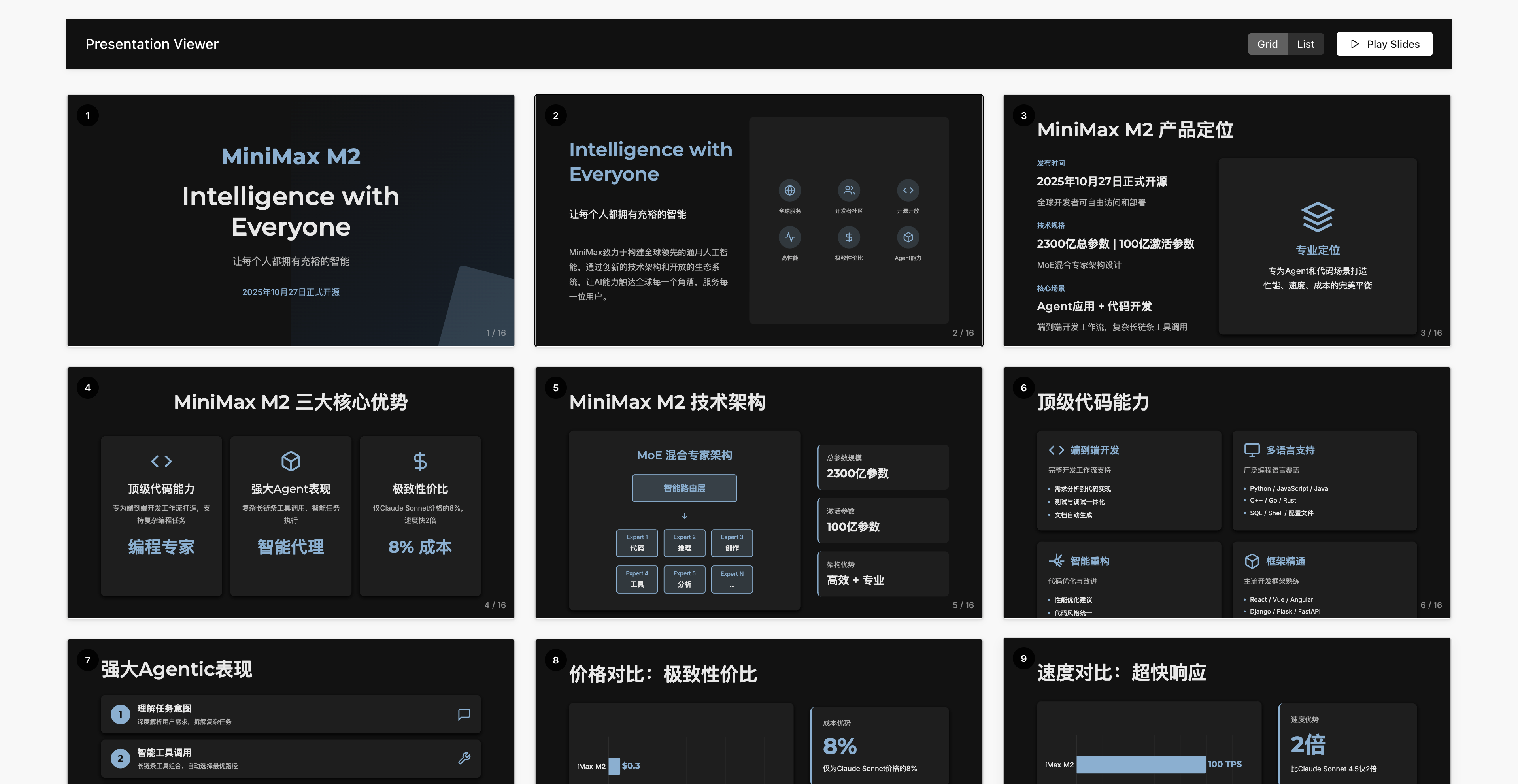
▲Ссылка для предварительного просмотра: https://z4czsdfoakc7.space.minimaxi.com/
Помимо впечатлений от создания продукта с нуля, MiniMax также предоставляет подробные руководства по интеграции инструментов командной строки, таких как Claude Code, или платформ разработки, таких как Cursor и VS Code.
▲Код Клода, использующий API модели MiniMax M2
Чередование мышления делает модели умнее, позволяя им понимать, когда следует задействовать тот или иной инструмент. Но у MiniMax M2 есть еще одна техническая особенность: он использует механизм полного внимания, что является исключением из правил .
Ранее мы обсуждали, как DeepSeek достигает таких низких затрат, и одной из важнейших причин является использование механизмов разреженного и гибридного внимания . Разреженное внимание позволяет модели избирательно фокусироваться на важной информации, игнорируя при этом второстепенную информацию при обработке токенов, подобно тому, как это делают люди.
Сочетая это с другими стратегиями, мы можем повысить скорость вывода модели и снизить затраты без ущерба для качества выходных данных.

▲ Оригинальная запись в блоге: https://huggingface.co/blog/MiniMax-AI/why-did-m2-end-up-as-a-full-attention-model
Команда MiniMax также опубликовала техническую статью в блоге, объясняющую, почему они вернулись к исходной точке и продолжили использовать механизм полного внимания — метод, который увеличивает нагрузку на обучение и вывод результатов.
Они упомянули, что главная причина — это «специфическая производительность». Большая часть того, что сейчас называют разреженным вниманием или эффективным вниманием, направлена не на улучшение производительности модели, а просто на экономию вычислительных ресурсов и снижение затрат.
Модели с полным вниманием по-прежнему демонстрируют более высокую производительность и надежность. Однако, по мере того как требования к длине контекста продолжают расти, а темпы роста вычислительных мощностей на графических процессорах замедляются, постепенно может проявиться потенциал линейного и разреженного внимания.
В настоящее время MiniMax M2 стремится достичь максимально возможного баланса между качеством, скоростью и ценой при ограниченных вычислительных ресурсах, и на этот раз ему это действительно удалось.

Поэтому в какой-то степени многие считают, что открытый исходный код означает бесплатную передачу технологий другим; однако в истории технологического развития открытый исходный код подразумевает возможность взаимодействия различных технологий и сотрудничества разных исследователей, что приводит к дальнейшим технологическим инновациям.
Когда компания Artificial Analysis, разработчик платформы для анализа крупномасштабных моделей, представила общую производительность MiniMax M2 на своей платформе, она также упомянула отечественные технологии с открытым исходным кодом, сказал он.
Компания China AI Labs продолжает удерживать лидирующие позиции в области открытого программного обеспечения.
Выпуск MiniMax продолжает укреплять лидирующие позиции Китая в области искусственного интеллекта с открытым исходным кодом, позиции, заложенные DeepSeek в конце 2024 года и поддерживаемые последующими релизами от DeepSeek, Alibaba, Zhipu, Kimi и других компаний.
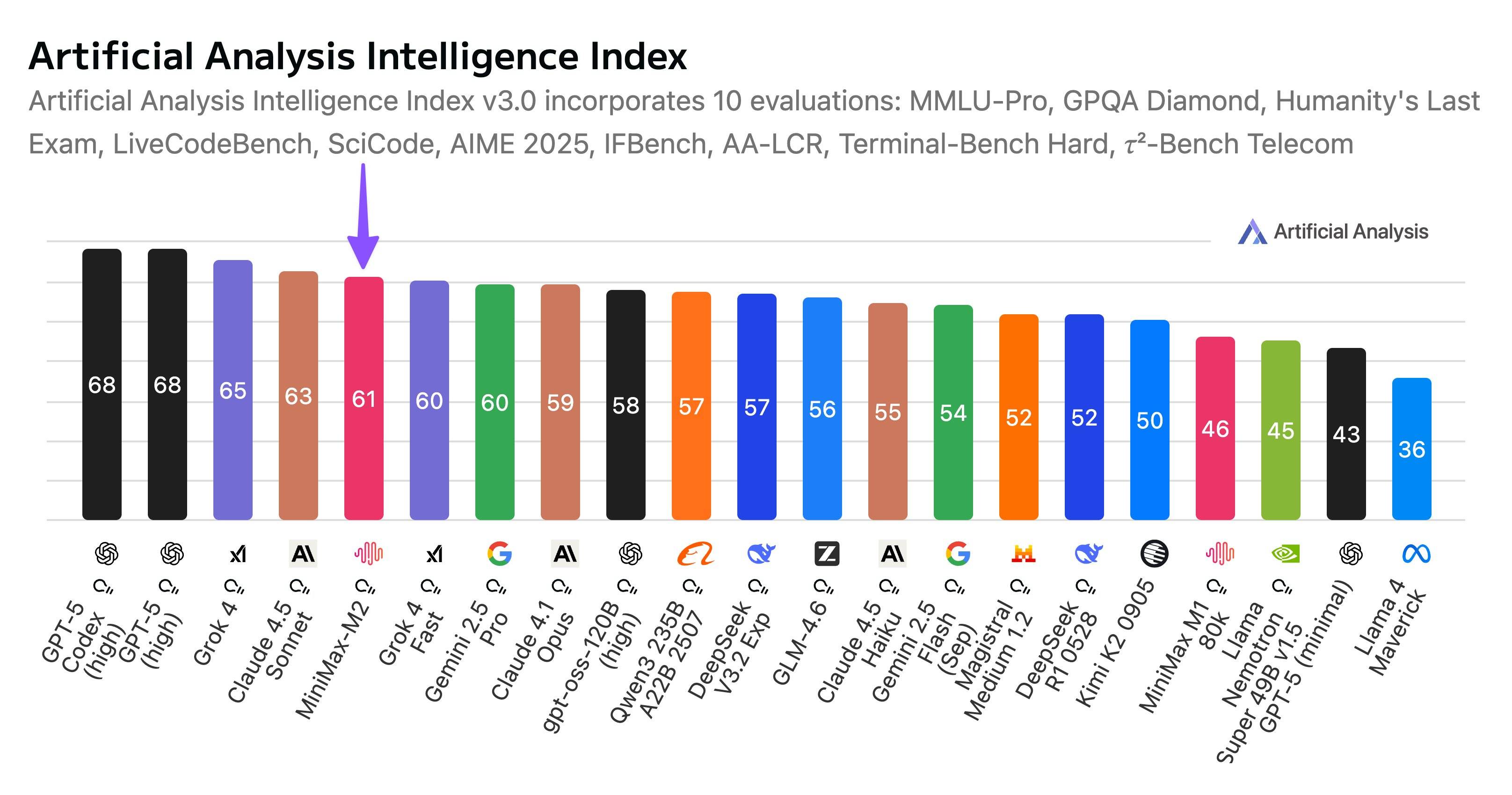
Это правда. Мы ждали DeepSeek R2 целый год, но вместо него увидели Kimi K2, ставший хитом за рубежом, серию Zhipu GLM и серию Qwen, на которую полагается почти каждый разработчик.
Все эти разработанные внутри страны модели с открытым исходным кодом, с их разнообразными техническими подходами и различными направлениями применения, только в совокупности обладают истинными преимуществами и силой, не позволяя закрытому исходному коду стать единственным представителем «хорошей модели».
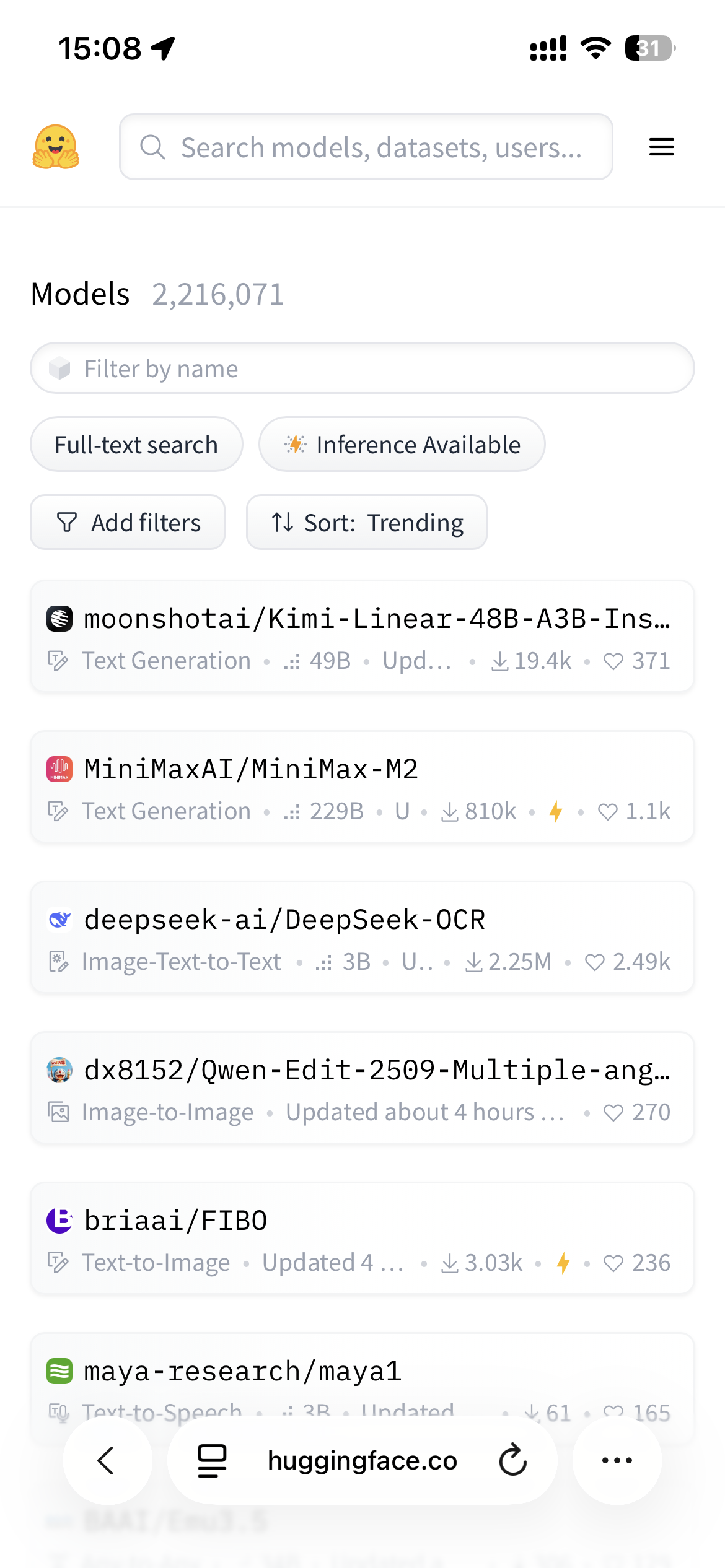
▲ На сайте Hugging Face четыре самые популярные модели — это разработанные внутри страны модели с открытым исходным кодом; Источник изображения: https://huggingface.co/models?sort=trending
Закрытый исходный код не может победить закрытый исходный код; только открытый исходный код способен преодолеть эти барьеры.
Некоторое время назад на Дне программиста 1024 года в компании Xiaohongshu основатель Hugging Face упомянул, что разрыв между открытым и закрытым исходным кодом сокращается, и Китай в этом отношении относительно продвинулся. Технический руководитель Xiaohongshu также сказал, что открытый исходный код снижает стоимость использования ИИ в обществе и мобилизует усилия всех для продвижения технологии вперед.
Несомненно, открытый исходный код — это хорошо, но никто не ожидал, что именно он погубит закрытый исходный код.

Появление DeepSeek не только открыло миру совершенно новую логику обучения моделей, позволяющую достичь столь же впечатляющих результатов при меньших затратах, но, что более важно, определило четкое направление для всей модели работы отечественного ИИ.
Это заставило всех осознать, что в условиях, когда Соединенные Штаты в то время монополизировали глобальный дискурс об ИИ, открытый исходный код был единственным способом заявить о себе.
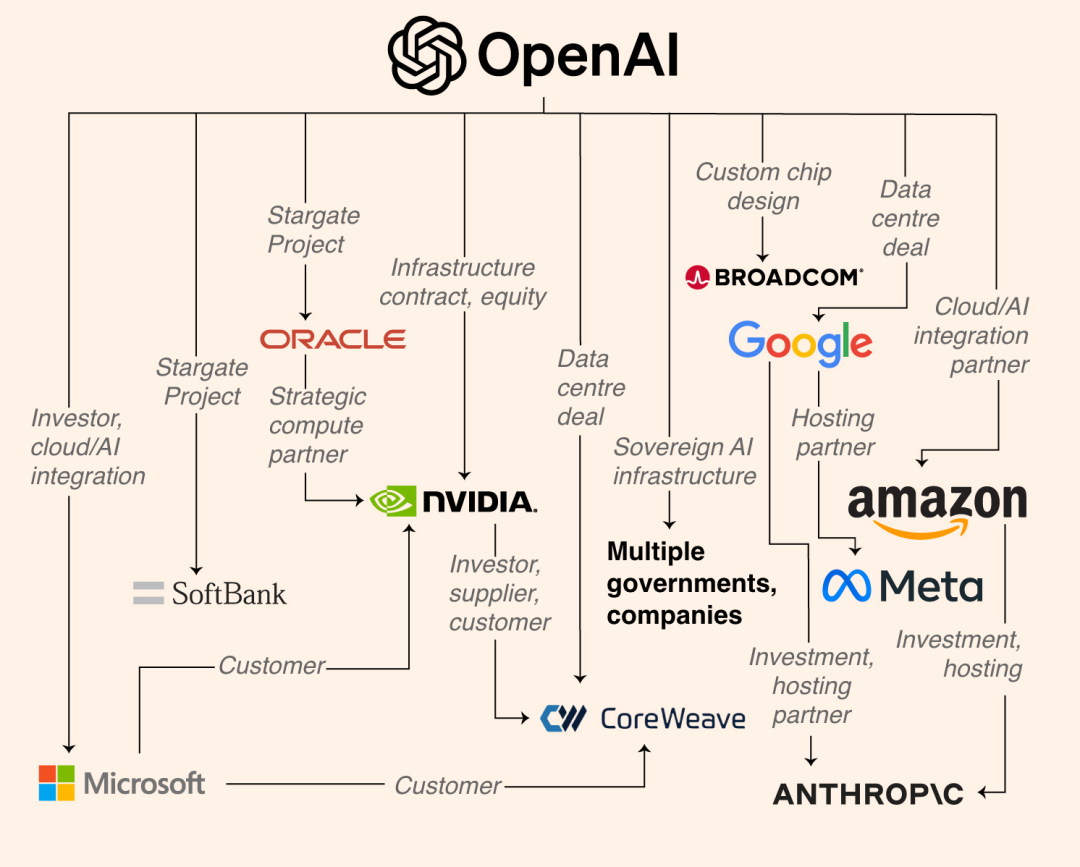
▲Бизнес-империя OpenAI, управляющая вычислительными мощностями, оцениваемая в триллион долларов, включает в себя Google, Meta, Anthropic и др.
Конечно, есть множество других конкретных причин для выбора открытого исходного кода. OpenAI, Anthropic и Gemini разрабатывают собственные системы в закрытом режиме. Они могут обучать более крупные модели с неограниченным количеством видеокарт и привлекать сотни миллиардов долларов инвестиций.
Однако дилемма, с которой сталкиваются модели отечественной разработки, заключается в нехватке вычислительной мощности и ограниченности чипов… Если модели не используются совместно, никто не сможет повторно использовать вычислительные мощности. Без пригодной для использования базовой модели все приходится начинать с нуля. Компания Baidu изначально решила сохранить модель в закрытом исходном коде ради своей бизнес-модели; в июне этого года она также объявила об официальном открытом доступе к исходному коду серии Wenxin Big Model 4.5.
С другой стороны, на внутреннем рынке слишком много производителей моделей, и конкуренция слишком высока. Если он решит не открывать исходный код, это сделают другие; если же он решит закрыть исходный код, пользователи могут выбрать другие модели.
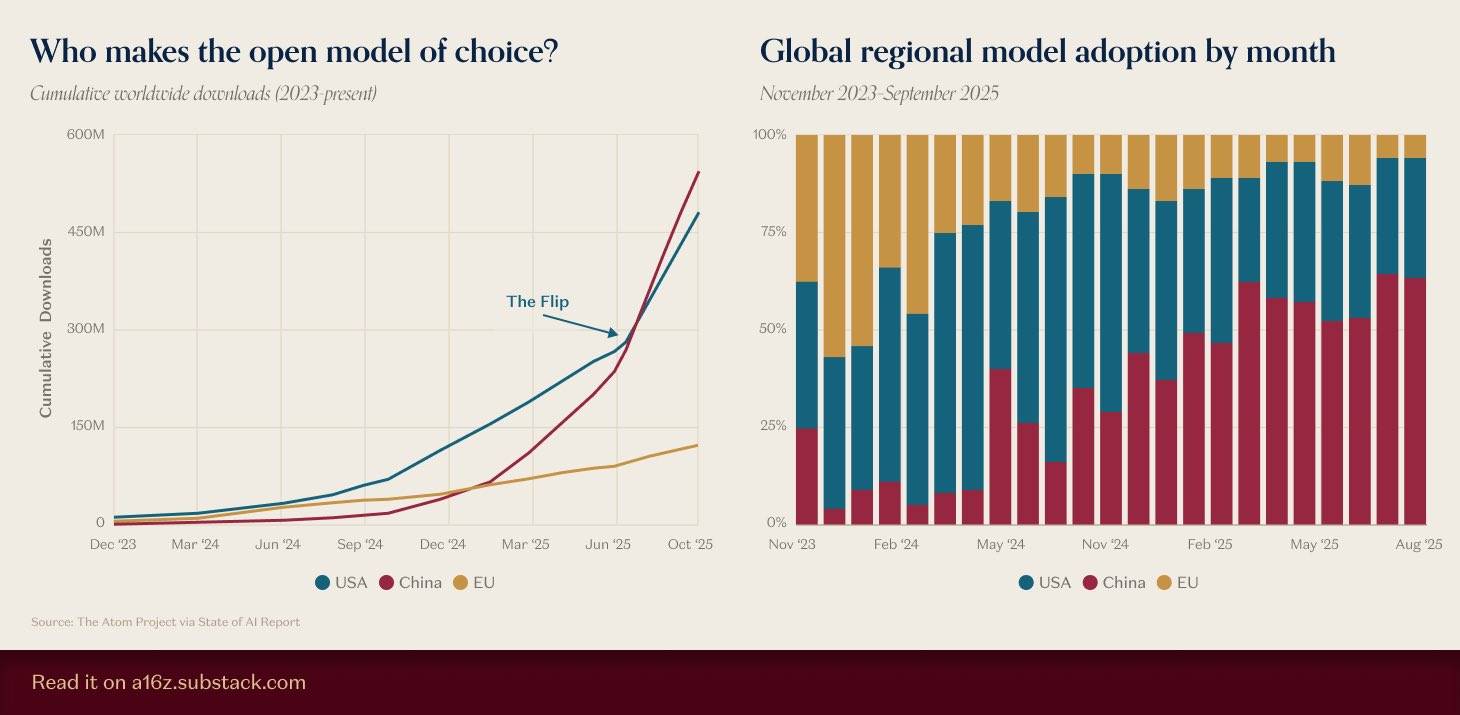
▲Источник изображения: https://a16z.substack.com/p/charts-of-the-week-open-model-of
Некоторое время назад a16z собрал данные о моделях с открытым исходным кодом, и результаты показали, что совокупное количество загрузок отечественных моделей с открытым исходным кодом не только превзошло количество загрузок американских моделей, но и продолжает увеличиваться.
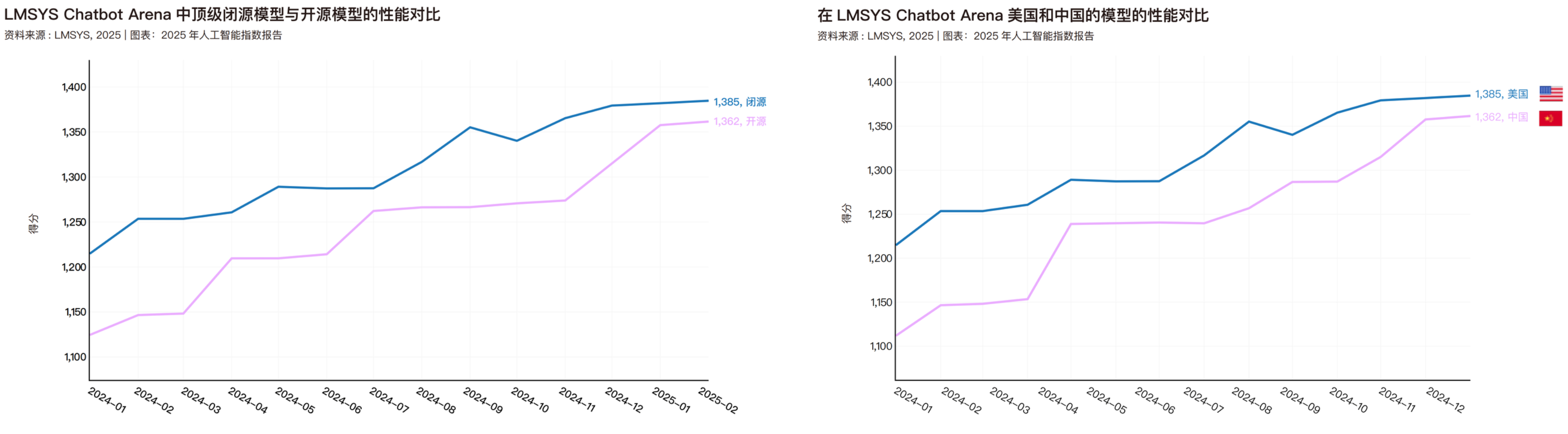
В апреле этого года Стэнфордский университет также опубликовал отчет «Индекс ИИ 2025», в котором сравнивалась производительность моделей с открытым и закрытым исходным кодом, а также производительность моделей из Китая и США. Данные в этом отчете охватывают период только до февраля этого года; к следующему году отечественные модели с открытым исходным кодом, вероятно, превзойдут как модели с закрытым исходным кодом, так и американские модели.
Если мы разложим преимущества отечественного открытого исходного кода на мельчайшие составляющие, то обнаружим, что наше нынешнее лидерство обусловлено целостной и масштабной системой открытого исходного кода. Каждое звено в этой системе делает возможности отечественного открытого исходного кода все более и более мощными.
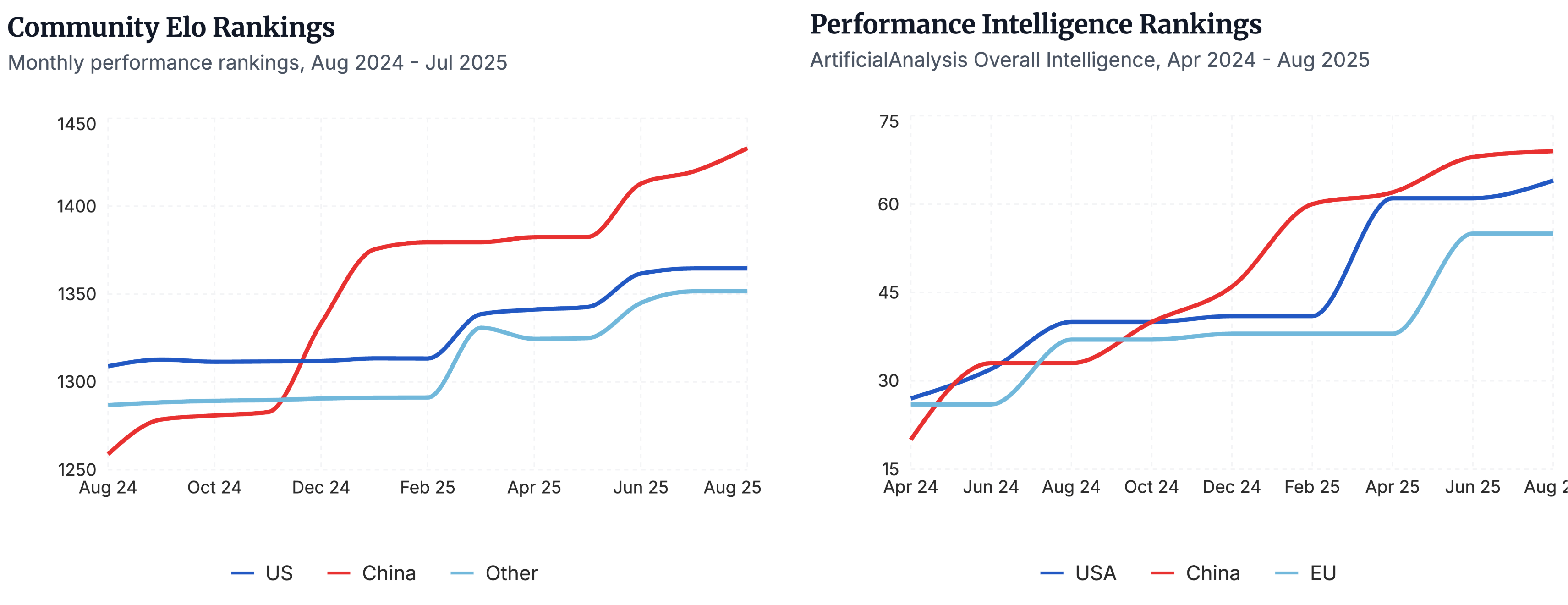
▲Будь то оценка отечественных моделей с открытым исходным кодом сообществом, например, рейтинг Эло, или сравнение производительности по регионам в сравнительном тесте по искусственному анализу, отечественные модели с открытым исходным кодом занимают лидирующие позиции. | Источник изображения: https://www.atomproject.ai/
DeepSeek открыл первую брешь благодаря своей структуре затрат и эффективному выводу данных; Qwen прорвал эту брешь, создав прорыв благодаря масштабу своей экосистемы; MiniMax, Zhipu и Kimi, с другой стороны, использовали различные технические подходы, чтобы еще больше расширить этот разрыв.
Когда небольшие команды по всему миру используют Qwen для тонкой настройки, DeepSeek для создания основ для инференции и MiniMax для проверки агентов, отечественные решения с открытым исходным кодом перестали быть просто выбором и стали решениями по умолчанию. В результате центр глобальной экосистемы открытого исходного кода начал смещаться в сторону Китая.
В прошлом месяце Дженсен Хуанг в интервью на саммите по искусственному интеллекту заявил, что «Китай выиграет гонку в области ИИ». Однако он немедленно отозвал свое заявление через официальный аккаунт Nvidia, X, уточнив, что Китай на самом деле «отстает от США в гонке в области ИИ всего на наносекунды».

Это не первый раз, когда Хуан упоминает позицию Китая в гонке за искусственный интеллект. Он неоднократно публично заявлял, что модели с открытым исходным кодом чрезвычайно важны как для разработчиков, стартапов, так и для так называемой гонки за ИИ.
На конференции NVIDIA GTC в октябре этого года Дженсен Хуанг в своем выступлении вновь упомянул, что на мировом рынке моделей с открытым исходным кодом китайская компания Tongyi Qianwen занимает первое место и обладает большей частью рыночной доли.
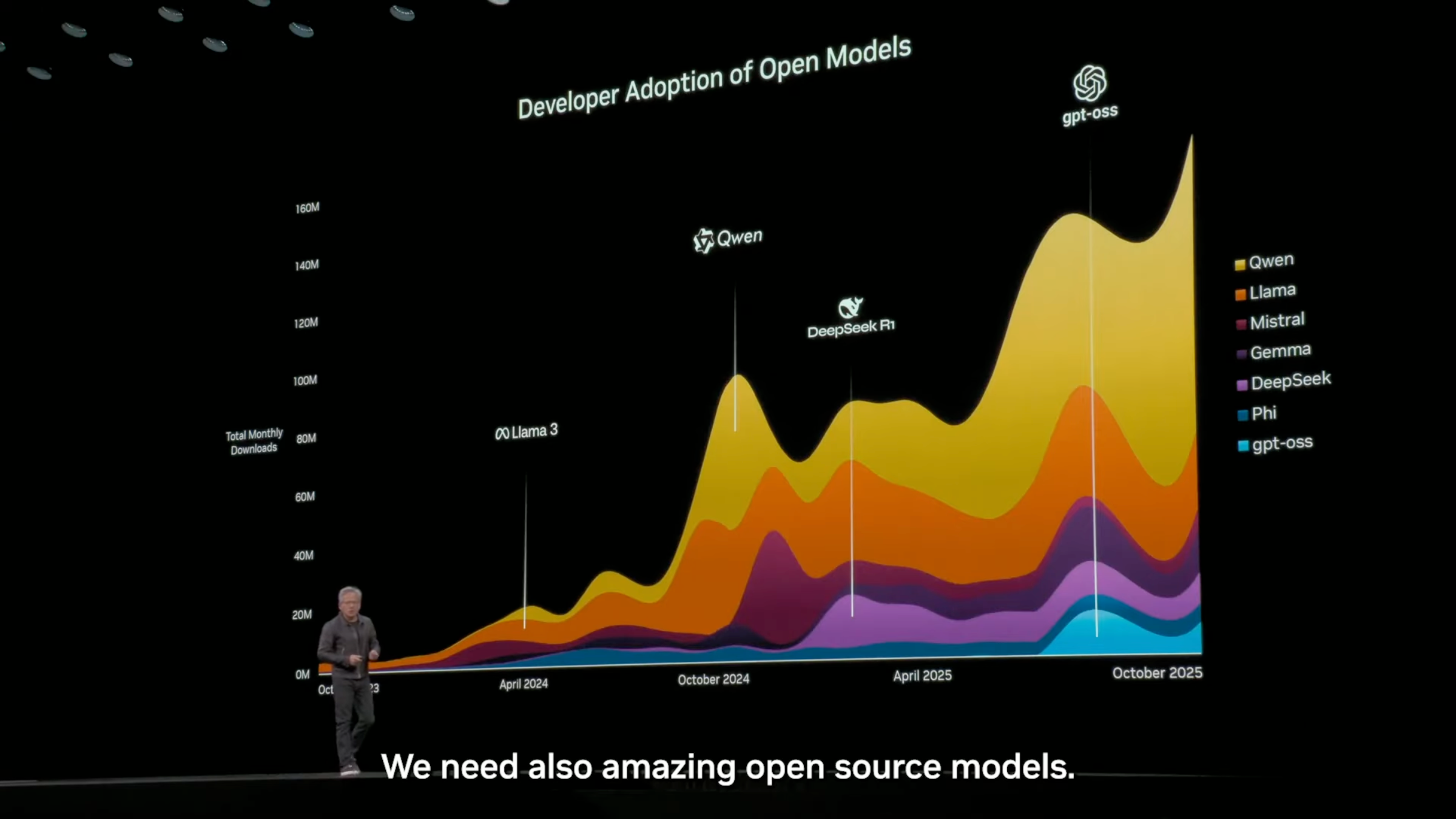
▲ Почти 60% — это Qwen.
В апреле этого года он также заявил на технологической конференции в Вашингтоне: «Без сомнения, Huawei — одна из самых мощных технологических компаний в мире… Китай не отстает в области искусственного интеллекта. Мы очень, очень близки к этому… 50% мировых исследователей в области ИИ — китайцы. Нам придется конкурировать».
Однако в конкуренции за открытый исходный код обратите внимание на лидера в этой области в США — Llama от Meta. В апреле прошлого года вышла Llama 3, за ней последовали Llama 3.1 в июле, Llama 3.2 в сентябре, а затем, в апреле этого года, неожиданно появилась Llama 4. Существует даже более продвинутая версия, Behemoth, которая еще не выпущена.

▲В игре Llama 4, вышедшей в апреле, упоминались три версии: Бегемот, Маверик и Разведчик. Похоже, разработка Бегемота была прекращена.
После этого единственными новостями о Meta стали предложения Цукерберга о высоких зарплатах за переманивание талантливых сотрудников, а затем недавнее увольнение 600 человек. Даже лауреат премии Тьюринга Ян Лекун уволился, чтобы основать собственный бизнес.
Цукерберг, вероятно, никогда не предполагал, что его решение открыть исходный код в Кремниевой долине, сделавшее его уникальной фигурой, будет превзойдено DeepSeek, популярность которого резко возросла в январе этого года. В результате Meta оказалась в затруднительном положении: открытый исходный код не является вариантом, а закрытый исходный код не является жизнеспособной альтернативой.
Трудно не согласиться с тем, что Llama наполовину обязана своим успехом отечественным технологиям с открытым исходным кодом.
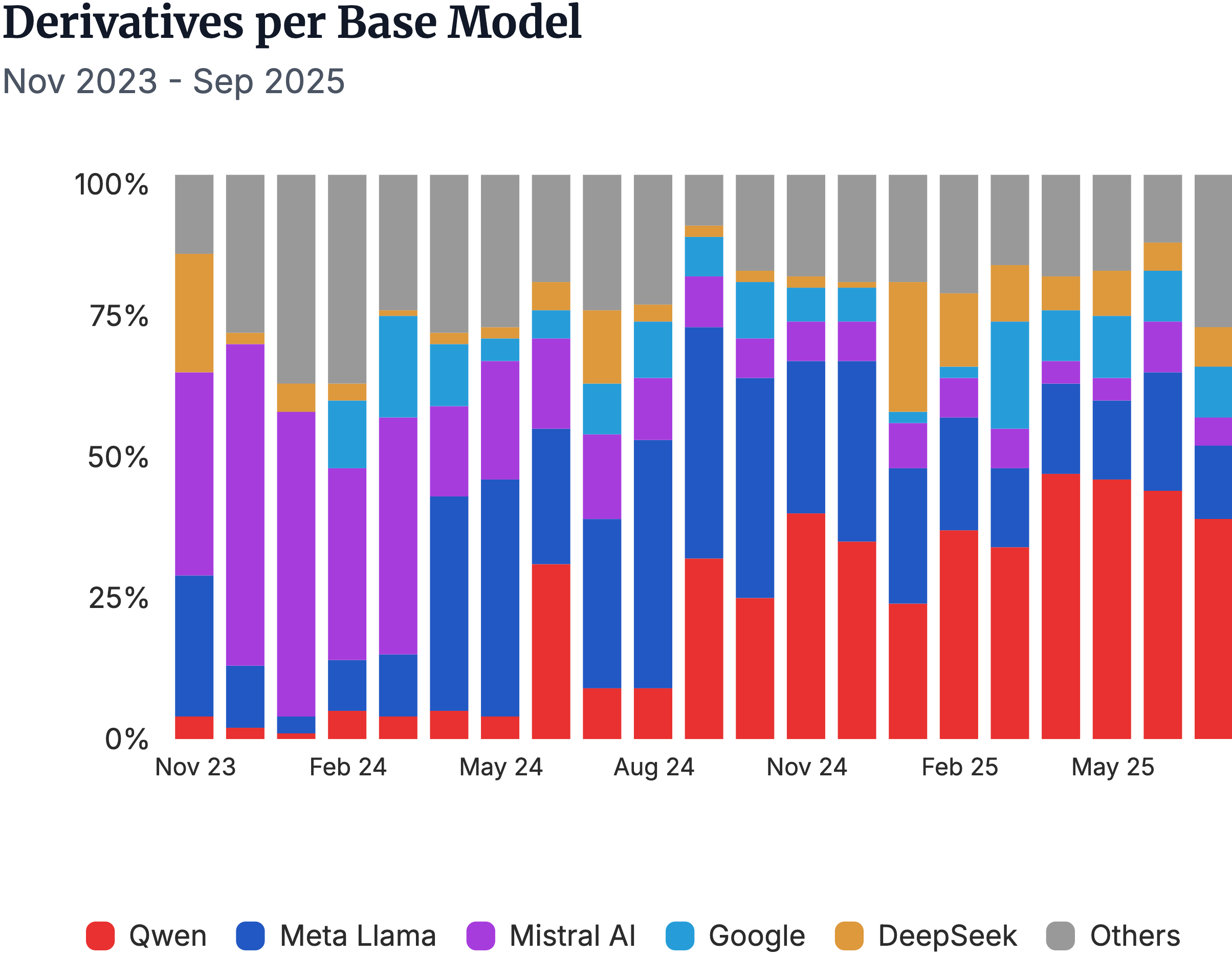
▲Мета-ориентированные производные модели и раннее лидерство Mistral AI были полностью превзойдены моделью Qwen от Alibaba.
Несколько дней назад, просматривая социальные сети, я увидел комментарий: «Открытый исходный код — это как превратить своего противника в сына; ни один сын не станет бить своего отца». Слова могут показаться грубыми, но в них есть доля правды. В цикле развития ИИ с открытым исходным кодом китайская модель открытого исходного кода явно стала основой экосистемы ИИ.
Эта волна моделей искусственного интеллекта, возглавляемая разработанными внутри страны технологиями с открытым исходным кодом, меняет вопрос о том, кто может определять будущее ИИ. Она позволит каждому из нас использовать самые передовые и удобные в использовании в мире системы ИИ с меньшими затратами и большей скоростью.
Подробности последнего изображения следующие.
▲Сверху вниз:
Передовые модели: DeepSeek, Qwen, Moonshot AI (Kimi)
Основные конкуренты: Z.Ai, MiniMax
Компании, за которыми стоит следить: StepFun, InclusionAI/Ant Financial, Meituan, Tencent, IBM, Nvidia, Google, Mistral.
Области экспертизы: OpenAI, Ai2, Moondream, Arcee, RedNote, HuggingFace, LiquidAI, Microsoft, Xiaomi, Университет Мохаммеда бин Зайеда по искусственному интеллекту. Развивающиеся компании: ByteDance Seed, Apertus, OpenBMB, Motif, Baidu, Marin Community, InternLM, OpenGVLab, ServiceNow, Skywork.
Почетные упоминания: TNG Group, Meta, Cohere, Пекинский институт искусственного интеллекта, Multimodal Art Projection, Huawei.
#Добро пожаловать на официальный аккаунт iFanr в WeChat: iFanr (идентификатор WeChat: ifanr), где вы сможете в кратчайшие сроки увидеть еще больше интересного контента.
ifanr | Оригинальная ссылка · Посмотреть комментарии · Sina Weibo